系统架构设计面试题
十大经典系统架构设计面试题_架构_程序员石磊_InfoQ写作社区翻译自:https://medium.com/geekculture/top-10-system-design-interview-questions-10f7b5ea123d在我作为微软和Faceb![]() https://xie.infoq.cn/article/4c0c9328a725a76922f6547ad
https://xie.infoq.cn/article/4c0c9328a725a76922f6547ad
任何 SDI 问题的提示
-
通过陈述你所知道的来开始每个问题:列出系统所需的所有特征,你期望在这类系统中遇到的常见问题,以及你期望系统处理的流量。列出清单的过程可以让面试官看到你的计划技巧,并在你开始解决问题之前纠正任何可能的误解。
-
叙述任何权衡:每个系统设计选择都很重要。在每个决定点,列出至少一个积极和消极的选择的影响。
-
让面试官澄清:大多数系统设计的问题都是有意模糊的。提出澄清问题,向面试官展示你是如何看待这个问题的,以及你对系统需求的了解。
-
讨论新兴技术:总结每个问题,概述系统如何以及在哪里可以从机器学习中受益。这将表明你不仅为当前的解决方案做好了准备,而且也为未来的解决方案做好了准备。
一、设计一个 URL 缩短服务
当设计一个 URL 缩短服务时,会涉及多方面的考量和设计。
下面是一些可能会涉及的问题和讨论点:(除了项目特定需求,其他都是设计项目应该考虑的点)
-
功能需求:
- 用户输入长链接,服务生成短链接。
- 用户访问短链接时,被重定向到原始长链接。
-
设计考虑因素:
- 性能和扩展性:高并发访问的处理、服务扩展能力。
- 持久性:短链接和原始链接的存储方式,数据库选择等。
- 安全性:如何确保链接安全性,防止被猜测、滥用或恶意使用。
- 短链接生成算法:如何生成唯一的短链接,碰撞几率等。
- 数据访问模式:读取和写入的比例,对存储系统的压力等。
-
存储方式:
- 数据库选择:关系型、NoSQL、键值对存储等。
- 数据模型:如何存储原始链接和对应的短链接。
-
短链接生成算法:
- 如何确保短链接的唯一性?
- 算法的设计和性能。
-
访问处理:
- 如何处理短链接的访问请求?
- 重定向的逻辑实现。
-
安全和防护:
- 如何防止恶意用户生成大量短链接?
- 访问权限控制等。
-
服务扩展:
- 如何处理大规模的访问量?
- 是否需要分布式服务?采用什么样的架构?
-
统计和分析:
- 是否需要统计链接的点击次数?
- 如何进行链接访问的分析和报告?
-
定期清理:
- 如何处理长时间未使用的链接或者失效链接?
- 是否需要定期清理数据库中的数据?
-
API 设计:
- 如果提供 API 服务,如何设计 API 接口?
- 接口的权限控制和访问限制。
-
监控与告警:
- 如何监控服务的稳定性和性能?
- 针对服务异常如何设置告警和处理机制?
-
国际化和本地化:
- 是否需要考虑多语言环境下的短链接生成和访问?
-
错误处理:
- 如何处理用户访问错误、404 页面等异常情况?
-
容灾和备份:
- 如何确保服务的高可用性?采取什么样的容灾备份措施?
二、案例分析:京东转链接

原始链接:福临门 粳米 5kg/袋【13.41】
https://item.m.jd.com/product/3911869.html?ad_od=share&utm_user=plusmember&gx=RnAomDgLPTTeyp5Z_sA9&gxd=RnAowmYKPGXfnp4Sq4B_W578vOMp4E7JgUugKDcomXTOIlSPI-BCnvuytD0G7kc&cu=true&rid=10109&utm_source=kong&utm_medium=jingfen&utm_campaign=t_2011419013_&utm_term=6a1e75e36a4b44ef938ebc20867d6fd0
转链接之后:福临门 粳米 5kg/袋【13.41】
https://u.jd.com/ZijidW8
组合方式
英文大小写[a-zA-Z] :合计有 52个= 26+26
数字[0-9]:合计有9个
(他估计能塞入其他符号)
合计有:62 = 26+26+10
7个位置可以放的商品是 3,521,614,606,208 = 62 ^ 7
理论上可以放3.5万亿的数据,够用。
关于jd的转法,我研究下再出个学习文章~
三、假如我来设计
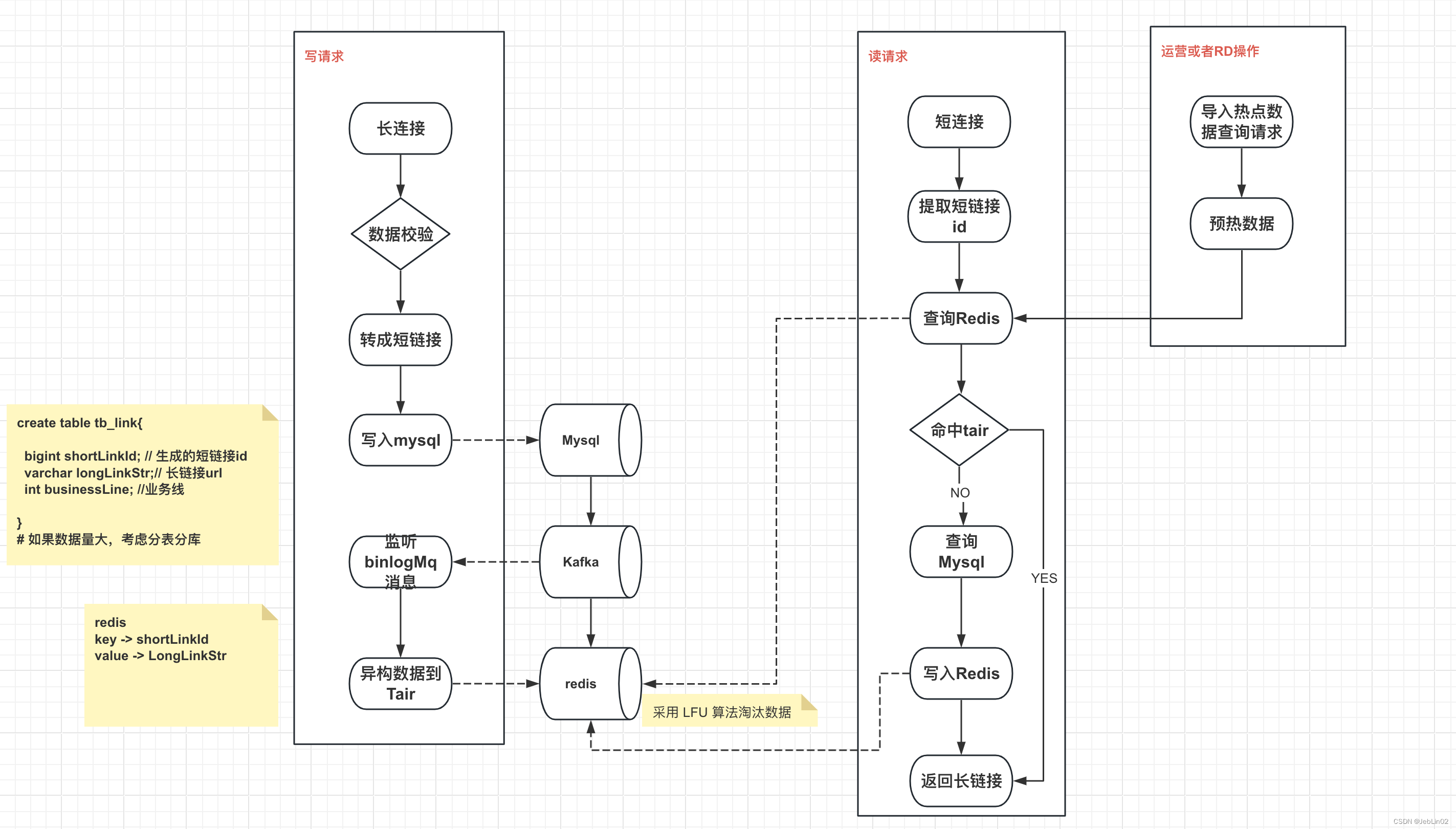
1、长连接如何转成短链接? ShortGenerator
功能需求:
- 用户输入长链接,服务生成短链接。
- 用户访问短链接时,被重定向到原始长链接。
短链接生成算法:
- 如何确保短链接的唯一性?
- 算法的设计和性能。
- 考虑用 AES 加密算法 (但是需要消耗CPU)
- 考虑用UUID(但是uuid是字符串乱序的,如果存mysql做index的话,会有性能影响)
- 雪花算法,42位的long + 商品Id后8位 + 8位随机数字(单纯的42位容易被爬虫,商品id后八位,转完之后也才50位长度,放mysql的bigInt没问题,bigInt是64位),生成的纯数字有两个缺点太长 + 容易被暴力猜出来,那么可以转化成62进制(a-zA-Z0-9合计62=26+26+10)
2、链接之间的对应关系如何存储与转换
存储方式:
- 数据库选择:关系型、NoSQL、键值对存储等。
- 数据模型:如何存储原始链接和对应的短链接。
- 存 Mysql (市面上的公司存储都用Mysql,因为他最成熟,最可靠)
- 数据通过 binlog异构到 Tair 或者 Redis (存缓存的目的是为了高效查)

3、如何实现高并发与可扩展?(分布式+动态伸缩)
设计考虑因素:
- 性能和扩展性:高并发访问的处理、服务扩展能力。
- 持久性:短链接和原始链接的存储方式,数据库选择等。
- 安全性:如何确保链接安全性,防止被猜测、滥用或恶意使用。
- 短链接生成算法:如何生成唯一的短链接,碰撞几率等。
- 数据访问模式:读取和写入的比例,对存储系统的压力等

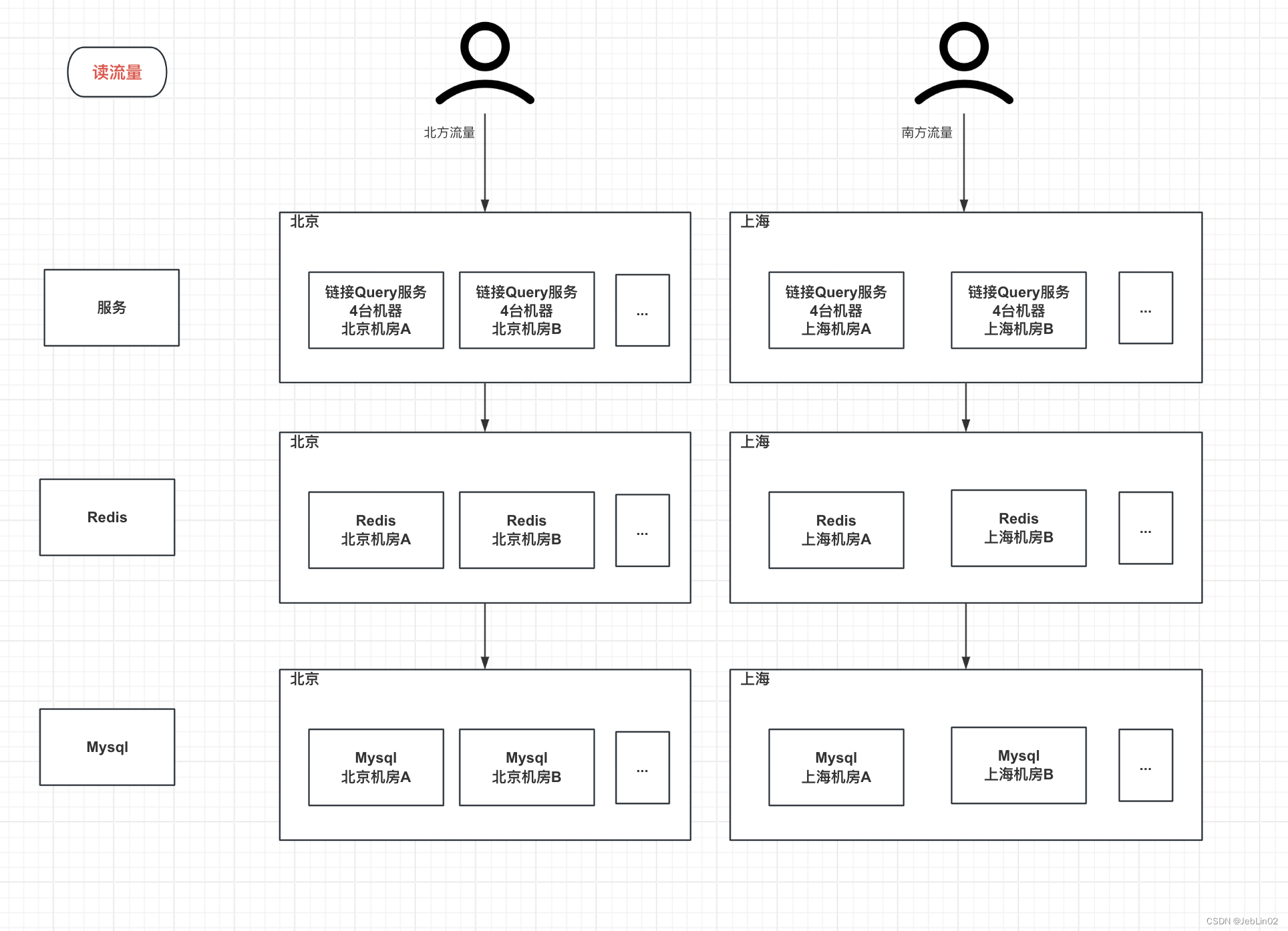
- 多机器多机房部署(挂了就切换机房)
- 服务器可以根据流量动态伸缩
- 关于DB的选择,肯定是选择mysql,关于缓存的选择,可以考虑Tair和Redis, Tair的优势是可以无限扩容,毕竟冷数据放磁盘,热数据放内存,Redis的话,用户群体相对较多,但是会淘汰数据,需要考虑缓存大面积失效的情况下,缓存雪崩给Mysql造成的大量query请求压力
4、如何防止恶意流量?
缓存穿透:redis失效,redis查不到数据,访问mysql拿到数据
缓存雪崩:大量的缓存穿透造成缓存雪崩
缓存击穿:redis查不到数据,mysql也查不到数据(恶意流量大概率是缓存击穿,干爆Mysql)
针对短链接服务,你可以考虑以下几种方法来防止缓存穿透:
| 方案 | 描述 | 缺点 | 采纳 |
|---|---|---|---|
| 缓存空对象(Cache Null Objects) | 对于数据库中不存在的短链接,也将这些查询结果缓存,但设置一个较短的过期时间,这样可以在一定时间内拒绝相同的无效请求,同时减少数据库的访问次数。 | 由于淘汰机制,如果此时来了大量的无效短链接请求,会把正常的缓存数据给冲掉。 | ❌ |
| 使用限流器(Rate Limiter) | 对短链接服务进行流量控制,限制单个用户或IP地址的请求频率,以防止暴力遍历和恶意请求。 | 攻击者还是有可能伪造大量的虚拟ip地址来进行攻击无法预防 | ✅ |
| CDN 防护 | 使用 CDN(内容分发网络)作为中间层,可以对请求进行过滤,拦截无效请求,从而减轻服务器的压力。 | CDN 防护通常适用于已知的请求和基于静态内容的服务。对于不断变化的动态请求,CDN 防护的效果可能会受到影响。 | ✅ |
| 布隆过滤器(Bloom Filter) | 使用布隆过滤器来过滤掉无效的短链接请求,它可以快速判断一个元素是否存在于集合中,如果元素不存在,可以直接拒绝请求,从而减轻对数据库的访问压力。 | 无法删除数据,但是可以接受,毕竟是要拦截恶意请求 | ✅ |
| 权限控制 | 访问的时候,先检查登录状态,如果没登录,就直接拦截,如果登录了,那么配合限流器,对同一用户可以进行拦截(比如京东的短连接进去之后,都会先检查你是否登录) | 可能影响用户体验(比如微博短连接跳进去老要求登录) 攻击者可能模仿多个用户多个ip进行攻击 | ✅ |
5、数据统计
1、实时统计
- 使用 SpringCloud的 Sentinel 进行流量控制与限流
- Redis4.0后使用 redis-cli -h xxxxxx.com -a <password> --hotkeys
- Redis4.0前用公司组件看
2、离线数据统计
- 数据入 Hive (linkId,userid, dt(YYYY-MM-DD hh mm) , 商品id,门店id)
- 按月、天、小时统计(门店访问量 Top100 ,商品访问量 Top100)
6、预警
假如我是淘宝,核心指标是门店id与商品id,
我关心的是
- 某个门店某段时间内是否有尖刺流量,如果有,那是否是这家门店运营设置错价格出bug了?
- 某个商品有尖刺流量,那么是不是这个商品价格设置有问题?
- 某段时间所有门店流量突增,是不是有营销的同学在搞活动?
- 查询或者写入接口流量突增,观察是不是某个业务方在刷数据?(根据来源的appkey,看看是不是业务方上线,代码有问题?需要回滚?)
上述都要求考虑应急方案,比如限流、比如熔断、比如机器扩容~
1、实时告警(超出阈值告警)
- 根据门店id打点(该门店的商品被访问一次就打点一次)
- 根据商品id打点(商品被访问一次就打点一次)
- 接口流量尖刺告警
- 接口流量跌零告警
2、离线数据预警
- 如果某个门店,或者某个商品一直占据 Top100,去看看是否有问题
7、数据定期归档清理
- Redis中数据根据 LFU 自动淘汰,暂时无需处理
- Mysql 超出1年的数据,归档到 Hbase 里面去(如果放hive,hive查询响应很慢的)
- Mysql中数据的清理 delete,需要考虑分表分库下,对于同一个集群的写压力,删除数据后,记得治理表空洞(治理表空洞需要关注磁盘容量,记得及时删除临时表)
- 若存在删除链接的场景,Redis中布隆过滤器可以定期重新扫描生成。
数据的情况,可以考虑采用定时任务~
98、项目FAQ
99、项目应急预案
1、应急步骤
- 先通报,后处理(看到报警,先响应,然后通报给组内同事或者Leader)
- 先止损,后定位(该摘流量摘流量,服务上线到一半也先停止)
- 有变更,先回滚(配置变更,服务上线变更,先回滚)
- 预定级,要从重(引起重视)
- COE复盘(后续如何避免)
2、应急处理人员
- 总指挥
- 处理人(rd负责止损操作)
- 协调者(中间件的协助同学,比如需要替换机器、比如需要扩容,运营客服同学帮忙安抚客户)

3、服务的某台机器挂了
- 去哪个平台摘除流量?
- 去哪个平台 dump下现场环境?(保存堆栈信息)
- 去那个平台进行服务扩容?或者替换机器?
4、es挂了
- 能否降级到Mysql?
- 如何替换机器?
- 如何转移节点?
- 联系哪个运维同学?
5、tair
- 能否降级到Mysql
- 联系哪个运维同学?
6、Mysql挂了
- 能否降级?
- 联系哪个 DBA ?
7、kafak挂了
- 如何停止消费?
- 如何降级?
- 联系哪个运维同学?