-系列目录-
大数据架构(一)背景和概念
大数据架构(二)大数据发展史
一、背景
1.岗位现状
大数据在一线互联网已经爆发了好多年,2015年-2020年(国内互联网爆发期)那时候的大数据开发,刚毕业能写Hive SQL配置个离线任务、整个帆软报表都20K+起步。如果做到架构师,50K跑不掉。现在市场回归理性后:
- 普通岗:大数据/数仓开发,实际上除超一线城市之外,尚存很多大型企业转型期信息化、互联网(物联网IOT)还在发展,数据还在爆发式增长,仍大有可为。
- 精英岗/管理岗:大数据总监/架构师,在重视数据的企业(一线互联网大厂、数据服务厂商),年包上百万也不少。
2.行业现状
数据架构在过去20年发展迅速,尤其是过去十年,几乎每年都有新概念、新产品开源出来。一些新名词爆发式展现出来:数据仓库、数据集市、大数据、离线数仓、实时数仓、时空数据库、数据中台、数据湖、流批一体、湖仓一体、实时湖仓、商业智能(BI)等等。
- 数据精细化:从经营与分析转为数据化的精细运营,对数据要求过程化、粒度更细。
- 产品多样性:传统 BI 中的 Report、OLAP 等工具开始转向面向最终用户自助式、半自助的产品,来快速获取数据并分析得到结果。
- 数据时效性:从 T+1 转为近乎实时的数据诉求。
- 平台轻薄化:阿里自砍中台战略,把中台拆分到各条业务线部门独自负责。把中台变得轻薄,更贴近业务。数据只有贴近业务才能焕发活力。底层逻辑是某业务领域的中心化是推荐的,有价值的。
3.本文目标
本系列文章不做源码级分析大数据框架,而是关注大数据的发展历史、主流架构和原理、落地流程。可作为架构师对于大数据架构的扫盲贴。(笔者花了2月的时间阅读大量文章总结出来的,可能会有问题,欢迎留言交流。)
二、概念解析
前面说了大数据领域出了很多概念:数据仓库、数据集市、大数据、离线数仓、实时数仓、时空数据库、数据中台、数据湖、流批一体、湖仓一体、实时湖仓。我们就来简单解析一下这些"专业名词",从概念上达成一致,有一个基本的定位。
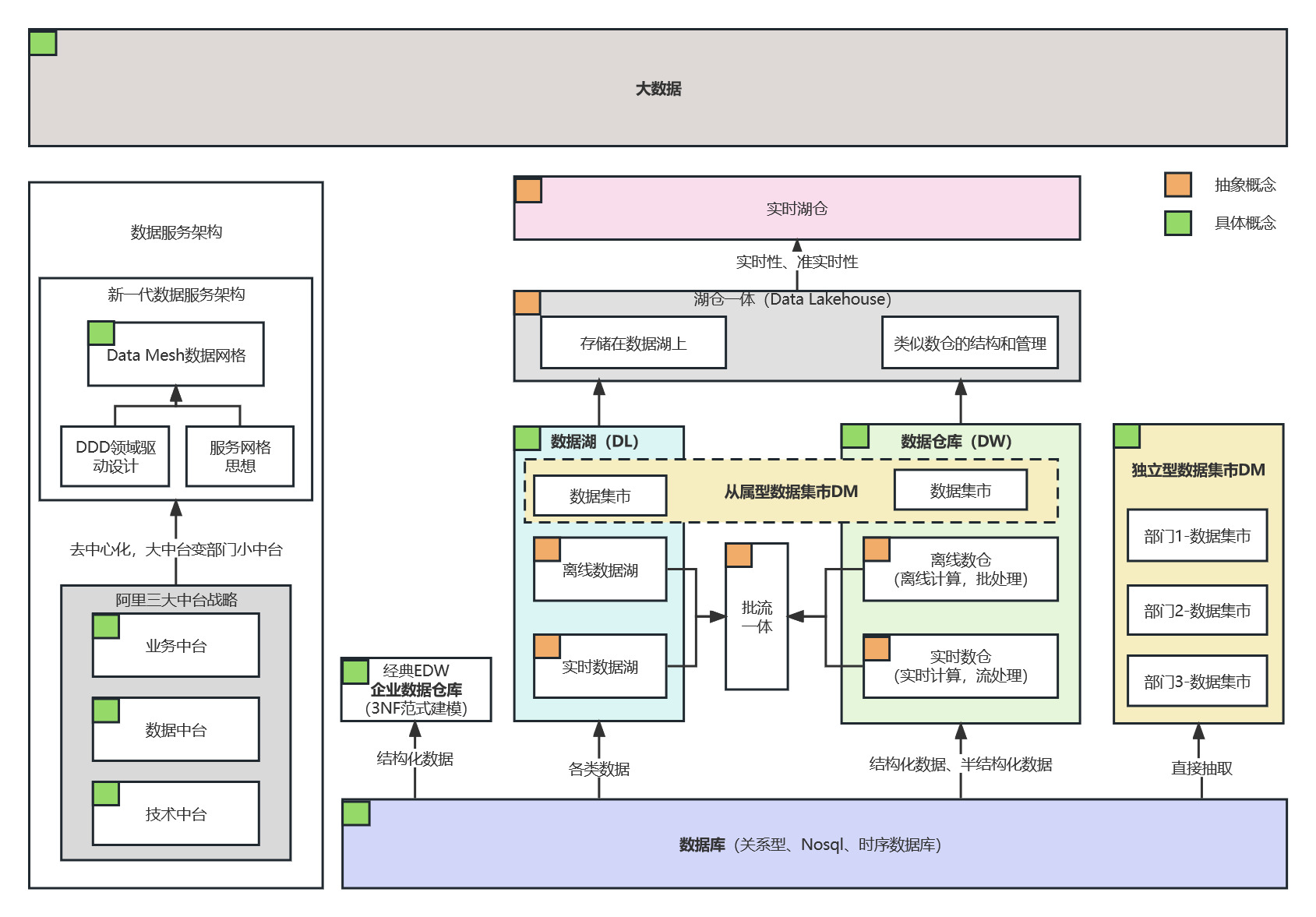
如上图所示,这些大数据领域的名词,我们可以分为2大类:1.数据服务架构相关 2.数据库、数仓相关。其中绿色角标标识具体概念的,黄色角标标识抽象概念的。
1.大数据:广义上的大数据概念,涵盖数据服务、数据仓库领域的概念。
1.数据服务架构相关:
- 数据中台:归属阿里三大中台战略。但2023年4月马云回国后,将公司按照业务线拆分,各付盈亏。同时中台也同步拆分到各业务中去,原中台只保留偏底层的少量系统。由此可见,中台可能去中心化,大中台变部门小中台,更贴近业务,盘活数据。
- Data Mesh数据网格:基于DDD领域驱动设计和服务网格思想的数据架构,可能会热度增加,但落地尚早。(国内service mesh都还没热起来,按照惯性data mesh最少3年后再说)。
2.数据仓库架构相关:
1.具体概念
- 数据库 :按照数据结构来组织、存储和管理数据的仓库。
- 数据仓库:抽取或导入结构化/半结构化数据,主要用于OLAP数据分析,支持管理决策。上世纪90年代,强制使用结构化数据+范式建模,构建EDW企业数据仓库。
- 数据集市:数据集市(Data Mart),也叫数据市场,是数据仓库的一个子集(部门级业务)。按照抽取方式可分为两类:1)独立型数据集市:直接从源数据抽取业务数据。2)从属型数据集市:从数据仓库/数据湖抽取。
- 数据湖 :以原始类型存储数据的存储系统。倡导:先导入,后处理分析使用。
2.抽象概念(逻辑概念)
- 离线数仓:数据仓库的延伸逻辑概念,描述的是批处理(离线计算)场景。
- 实时数仓:数据仓库的延伸逻辑概念,描述的是实时处理(实时计算)场景。
- 批流一体: 大数据的数据清洗ETL,可简单分为2类:批处理(离线任务)、流计算(实时计算)。批流一体讲究用一套技术方案实现2种目标。
- 湖仓一体:数据在数据湖和数仓中流动,兼具数仓的稳定性建模和数据湖的灵活特性。
- 实时湖仓:强调实时计算能力的湖仓一体架构。
2.1 数据库
数据库是“按照数据结构来组织、存储和管理数据的仓库”。数据库有很多种类型适用不同业务场景,最常见的是关系型数据库、键值型数据库、时序数据库。
2.1.1 关系型数据库
支持事务ACID特性的数据库。常见的有Mysql、Oracle、PostgresSQL等。2.1.2 非关系型数据库
- 文档型数据库(Document databases):MongoDB。优点是对数据结构要求不特别的严格。而缺点是查询性的性能不好。
- 键值型数据库(Key-value databases):Redis、Memcached,常用于缓存方案。
- 列数据库(Column-family databases):以列族的形式存储数据,如Apache Cassandra、HBase。优点是查询快速。缺点是数据结构有局限性。
- 时间序列数据库(Time-series databases):专门用于存储时间序列数据,如InfluxDB、OpenTSDB。目前时序大数据存储场景很多,前景极大,处于上升期。
2.2 数据仓库
2.2.1 数据仓库
数据仓库是Bill Inmon在1991年出版的“Building the Data Warehouse”一书中所提出的定义被广泛接受:数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
- 面向主题的:根据使用者的需求,将来自不同数据源的数据围绕着各种主题进行分类整合。
- 集成的:来自各种数据源的数据按照统一的标准集成于数据仓库中。
- 相对稳定的:数据仓库中的数据是一系列的历史快照,不允许修改或删除,只涉及数据查询。
- 反映历史变化的 :数据仓库会定期接收新的集成数据,从而反映出最新的数据变化。
2.2.2 数据仓库VS数据库

2.2.3 企业数据仓库EDW
EDW也是一种数据仓库DW。上世纪90年代,使用结构化数据+3NF范式建模,构建EDW企业数据仓库。
2.2.4 离线数仓
2003~2006年 Google发表了三篇论文:分布式文件系统GFS、分布式计算框架MapReduce、分布式存储系统BigTable。2006年,Hadoop正式面世。此后,以Hadoop技术栈为代表的离线数仓架构引领大数据发展了十多年。这时候的处理任务基本都是批处理任务。离线数仓特指:应对批处理(离线计算)场景的数据仓库。如下图所示:
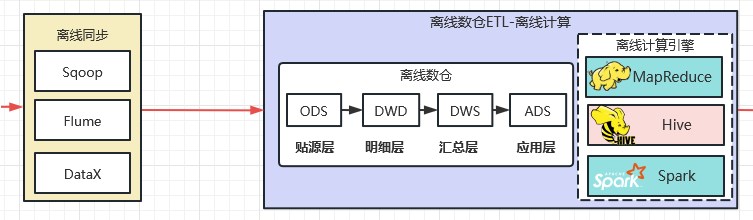
早期离线数仓使用离线计算引擎实现批处理数据。最常用的离线计算引擎就是Hive(Hadoop技术体系)。典型应用是定时任务跑批生成报表数据。
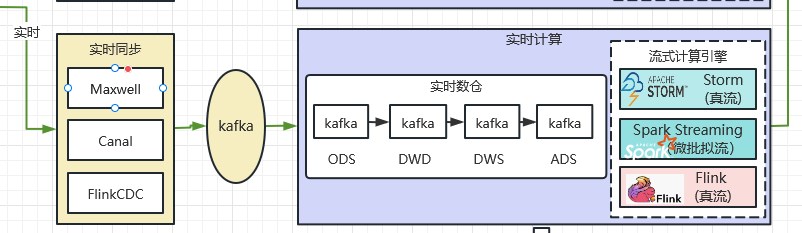
2.2.5 实时数仓
2014年,Flink为代表的实时计算风靡,基于Flink为计算引擎的实时数仓跃然纸上。实时数仓特指:应对实时处理(实时计算)场景的数据仓库。典型的实时数仓如下图所示:
2.3 数据集市
数据集市(Data Mart),也叫数据市场,就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
按照抽取方式可分为两类:
1)独立型数据集市:直接从源数据抽取业务数据。
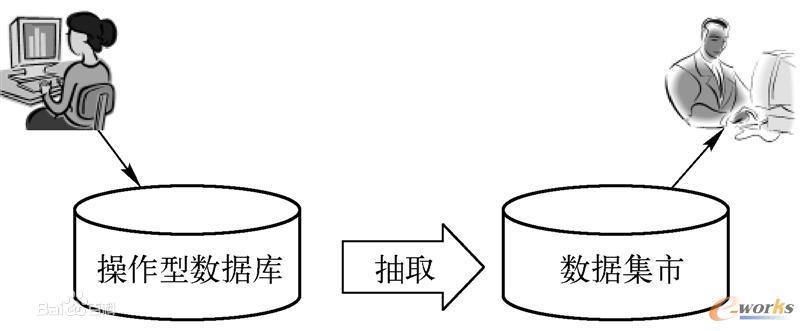
2)从属型数据集市:从数据仓库/数据湖抽取。
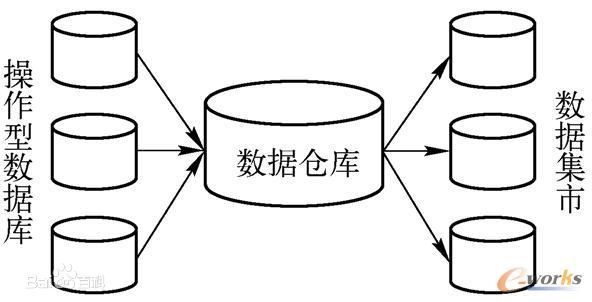
数据仓库VS数据集市

2.4 数据湖
2.4.1 数据湖
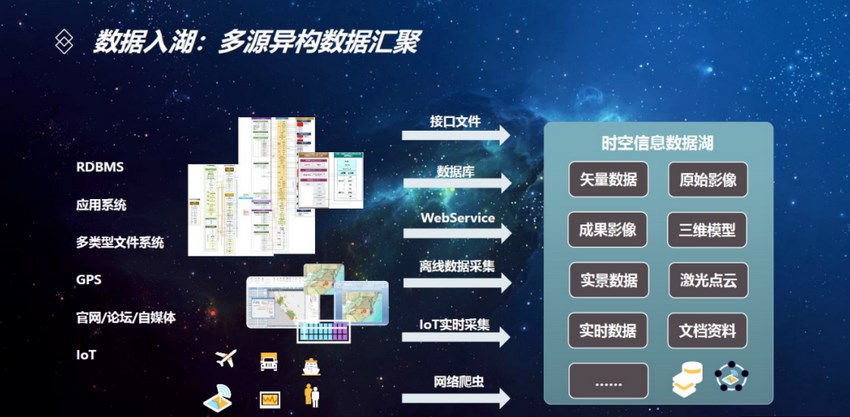
随着互联网->移动互联网->IOT物联网 这一条商业智能发展线路的改变,产生了大量的照片、视频、文档等非结构化数据、时序数据。数据湖诞生了:允许用户以任意规模存储所有结构化和非结构化数据,并支持对数据进行快速加工和分析。用户可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析(从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
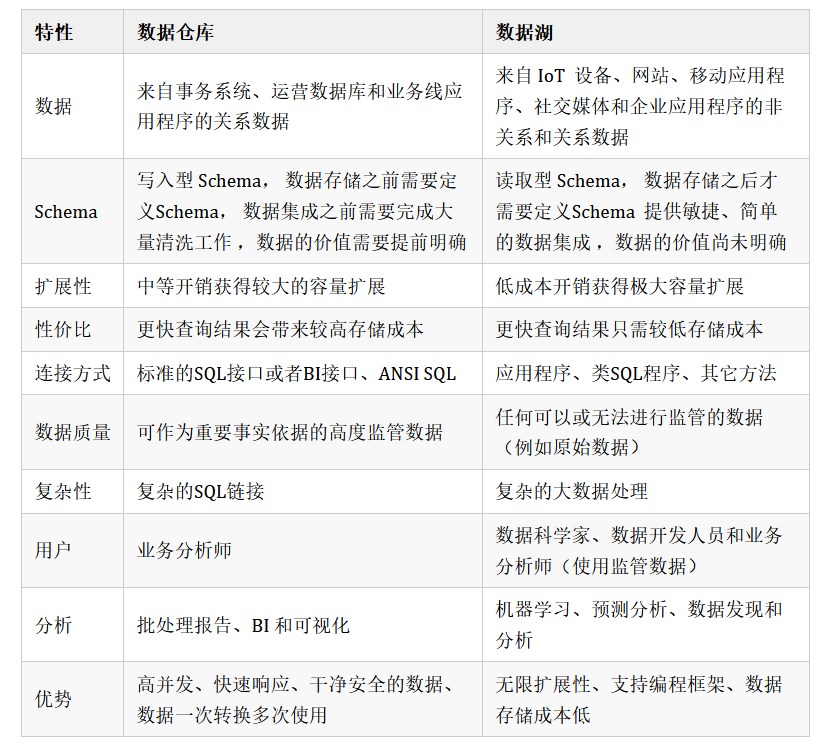
2.4.2 数据仓库VS数据湖
数据仓库的成长性很好,而数据湖更灵活。数据仓库支持的数据结构种类比较单一,数据湖的种类比较丰富,可以包罗万象。数据仓库更加适合成熟的数据当中的分析和处理,数据湖更加适合在异构数据上的价值的挖掘。
=========参考=============
How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh