- https://github.com/search?q=fastai+ssd 有几个值得参考的代码,好好学习。
- GitHub - Samjoel3101/SSD-Object-Detection: I am working on a SSD Object Detector using fastai and pytorch fastai2实现的SSD,终于找到了code。
- https://github.com/sidravic/SSD_ObjectDetection_2/tree/master/train 这也是fastai2实现的ssd
- 很重要的参考:mAP的参考,基于fastai2的结构:GitHub - rbrtwlz/fastai_object_detection: Extension of the fastai library to include object detection.
- fastai2的SSD,来自:dhblog - Object Detection from scratch - Single Shot Detector
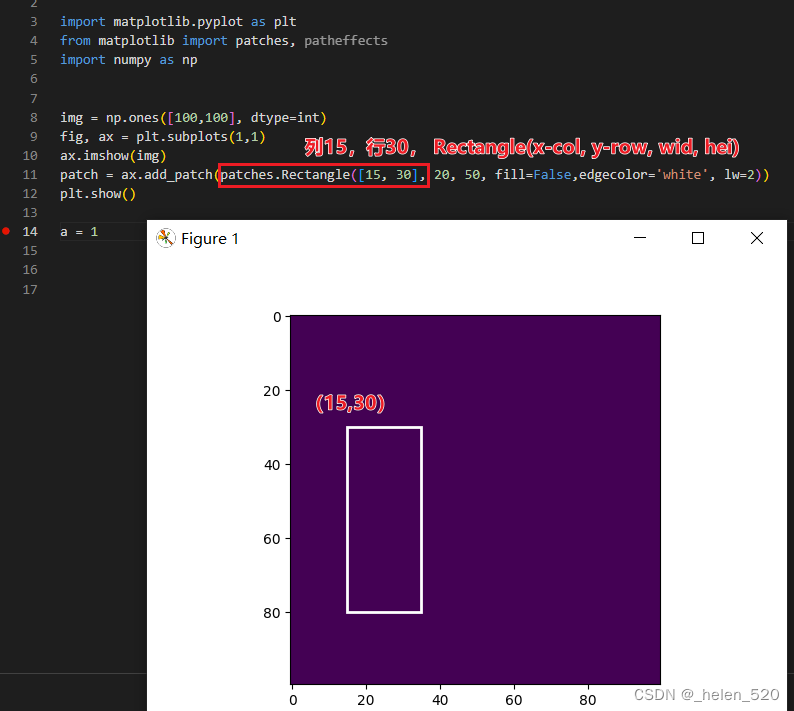
- fastai2和fastai1的bbox都是:x1,y1,x2,y2格式;显示框plt都是x,y,h,w格式
- fastai2的bbox范围是[-1,1];显示到224需要变换:
for i,ax in enumerate(axes.flat): # y~[-1,1] ([-1,1] + 1)/2~[0,1]
show_ground_truth(ax, x[i], ((y[0][i] + 1)/2 * 224).cpu(), y[1][i].cpu())
def draw_rect(ax, b, color='white'):
patch = ax.add_patch(patches.Rectangle(b[:2], *b[-2:], fill=False, edgecolor=color, lw=2)) - 的
" 使用fastai v2 重写ssd by fastai course-v2 2018 part2 pascal_multi.ipynb "
# data pascal_voc2007
import warnings
warnings.filterwarnings('ignore')
import sys
sys.path.insert(0, '/home/zhr/fastai2/fastai_object_detection/fastai_object_detection') # debug源码,而非package
from pathlib import Path
from fastai.vision.all import *
# from zhr_util import get_annotations
from zhr_util import ssd_loss, SSD_Head, SSD_MultiHead, FocalLoss
path = Path('/home/helen/dataset/pascal_2007')
trn_im_names, trn_truths = get_annotations(path/'train.json')
val_im_names, val_truths = get_annotations(path/'valid.json')
# tst_im_names, tst_truths = get_annotations(path/'test.json')
tot_im_names, tot_truths = [trn_im_names + val_im_names, trn_truths + val_truths]
img_y_dict = dict(zip(tot_im_names, tot_truths))
truth_data_func = lambda o: img_y_dict[o.name]
sz=224 # Image size
bs=64 # Batch size
item_tfms = [Resize(sz, method='squish'),]
batch_tfms = [Rotate(), Flip(), Dihedral()]
getters = [lambda o: path/'train'/o, lambda o: img_y_dict[o][0], lambda o: img_y_dict[o][1]]
pascal = DataBlock(blocks=(ImageBlock, BBoxBlock, BBoxLblBlock),
splitter=RandomSplitter(),
getters=getters,
item_tfms=item_tfms,
batch_tfms=batch_tfms,
n_inp=1)
dls = pascal.dataloaders(tot_im_names,bs=bs)
# dls.vocab
k = 9
head_reg4 = SSD_MultiHead(k, -3., dls)
body = create_body(resnet34(True))
model = nn.Sequential(body, head_reg4)
ssd_learner = Learner(dls, model, loss_func=ssd_loss)
ssd_learner.fit_one_cycle(3, 1e-3)

import json
import collections
from fastai.vision.all import *
def get_annotations(fname, prefix=None):
"Open a COCO style json in `fname` and returns the lists of filenames (with maybe `prefix`) and labelled bboxes."
annot_dict = json.load(open(fname))
id2images, id2bboxes, id2cats = {}, collections.defaultdict(list), collections.defaultdict(list)
classes = {}
for o in annot_dict['categories']:
classes[o['id']] = o['name']
for o in annot_dict['annotations']:
bb = o['bbox']
id2bboxes[o['image_id']].append([bb[0],bb[1], bb[2]+bb[0], bb[3]+bb[1]])
id2cats[o['image_id']].append(classes[o['category_id']])
for o in annot_dict['images']:
if o['id'] in id2bboxes:
id2images[o['id']] = ('') + o['file_name']
ids = list(id2images.keys())
return [id2images[k] for k in ids], [[id2bboxes[k], id2cats[k]] for k in ids]
" 多类别的标签:fastai v2版本的使用方法 "
# if 0:
# df = pd.read_csv(path/'train.csv')
# def get_x(r): return path/'train'/r['fname']
# def get_y(r): return r['labels'].split(' ')
# # dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
# # get_x = get_x, get_y = get_y)
# # dsets = dblock.datasets(df)
# def splitter(df):
# train = df.index[~df['is_valid']].tolist()
# valid = df.index[df['is_valid']].tolist()
# return train,valid
# dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
# splitter=splitter,
# get_x=get_x,
# get_y=get_y,
# item_tfms = RandomResizedCrop(224, min_scale=0.35))
# dls = dblock.dataloaders(df)
# dls.show_batch(max_n=9, figsize=(8, 6))
__all__ = ['get_ssd_model','ssd_resnet34', 'ssd_loss']
# Cell
import torch
from torch import nn
from torch.nn import Module
from torchvision.ops.boxes import batched_nms
from torch.hub import load_state_dict_from_url
from functools import partial
from fastai.vision.all import delegates
from fastai.vision import *
from fastai.callback import *
from fastai.vision import models
from fastai.vision.learner import create_body
from fastai.callback.hook import num_features_model
from fastai.layers import *
import torch.nn.functional as F
# Method used to match the shape of the conv_ssd_layer to the ground truth's shape
def flatten_conv(x,k):
# Flatten the 4x4 grid to dim16 vectors
bs,nf,gx,gy = x.size()
x = x.permute(0,2,3,1).contiguous()
return x.view(bs,-1,nf//k)
# Standard convolution with stride=2 to halve the size of the image
class OutConv(nn.Module):
# Output Layers for SSD-Head. Contains oconv1 for Classification and oconv2 for Detection
def __init__(self, k, nin, bias, dls):
super().__init__()
self.k = k
self.oconv1 = nn.Conv2d(nin, (len(dls.vocab))*k, 3, padding=1)
self.oconv2 = nn.Conv2d(nin, 4*k, 3, padding=1)
self.oconv1.bias.data.zero_().add_(bias)
def forward(self, x):
return [flatten_conv(self.oconv2(x), self.k), # 先box,再label
flatten_conv(self.oconv1(x), self.k)]
# SSD convolution that camptures bounding box and class
class StdConv(nn.Module):
# Standard Convolutional layers
def __init__(self, nin, nout, stride=2, drop=0.1):
super().__init__()
self.conv = nn.Conv2d(nin, nout, 3, stride=stride, padding=1)
self.bn = nn.BatchNorm2d(nout)
self.drop = nn.Dropout(drop)
def forward(self, x): return self.drop(self.bn(F.relu(self.conv(x))))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class SSD_Head(nn.Module):
def __init__(self, k, bias, dls):
super().__init__()
self.drop = nn.Dropout(0.25)
self.sconv0 = StdConv(512,256, stride=1)
self.sconv2 = StdConv(256,256)
self.out = OutConv(k, 256, bias, dls)
def forward(self, x):
x = self.drop(F.relu(x))
x = self.sconv0(x)
x = self.sconv2(x)
return self.out(x)
def one_hot_embedding(labels, num_classes):
return torch.eye(num_classes)[labels].cuda()
# 还是写成GPU格式更为有效,否则
class BCE_Loss(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
def forward(self, pred, targ):
t = one_hot_embedding(targ.squeeze(), self.num_classes)
t = t[:,1:] # Start from 1 to exclude the Background
x = pred[:,1:]
w = self.get_weight(x,t)
return F.binary_cross_entropy_with_logits(x, t, w.detach(), reduction='sum')/self.num_classes
def get_weight(self,x,t): return None
class FocalLoss(BCE_Loss):
def get_weight(self,x,t):
alpha,gamma = 0.25,1
p = x.sigmoid()
pt = p*t + (1-p)*(1-t)
w = alpha*t + (1-alpha)*(1-t)
return w * (1-pt).pow(gamma)
#convert center/height/width to fastai top left and bottom right coordinates
def cthw2corners(boxes):
top = (boxes[:,0] - boxes[:,2]/2).view(-1,1)
left = (boxes[:,1] - boxes[:,3]/2).view(-1,1)
bot = (boxes[:,0] + boxes[:,2]/2).view(-1,1)
right = (boxes[:,1] + boxes[:,3]/2).view(-1,1)
return torch.cat([top,left,bot,right],dim=1)
def hw2corners(ctr, hw):
# Function to convert BB format: (centers and dims) -> corners
return torch.cat([ctr-hw/2, ctr+hw/2], dim=1)
# Filter out all zero-valued bounding boxes
def un_pad(boxes,labels):
bb_keep = ((boxes[:,2] - boxes[:,0])>0).nonzero()[:,0]
return boxes[bb_keep],labels[bb_keep]
# Calculate the area of a bounding box
def box_area(boxes):
return (boxes[:,2] - boxes[:,0]) * (boxes[:,3] - boxes[:,1])
# Calculate the intersection of two given bounding boxes
def intersect(box_a,box_b):
#make sure box_a and box_b exists, otherwise undefine behavior if you call the func
top_left = torch.max(box_a[:,None,:2],box_b[None,:,:2])
bot_right = torch.min(box_a[:,None,2:],box_b[None,:,2:])
inter = torch.clamp((bot_right - top_left),min=0)
return inter[:,:,0] * inter[:,:,1]
# Calculate Jaccard (IOU)
def iou(bbox,anchor):
#bbox is gt_bb, anchor is anchor box, all in fastai style
if len(bbox.shape) == 1: bbox = bbox[None,...]
inter = intersect(bbox,anchor)
union = box_area(bbox).unsqueeze(dim=1) + box_area(anchor).unsqueeze(dim=0) - inter #to broadcast shape to (N,16),where N is number of gt_bb for single image
return inter / union
# Transform activations to bounding box format
def act_to_bbox(activation,anchor):
activation = torch.tanh(activation) #force scale to be -1,1
anchor = anchor.to(device)
act_center = anchor[:,:2]+ (activation[:,:2]/2 * grid_sizes.float().to(activation.device))
act_hw = anchor[:,2:] * (activation[:,2:]/2 + 1)
# return cthw2corners(torch.cat([act_center,act_hw],dim=1))
return hw2corners(act_center, act_hw)# 速度更快
# Map to Ground Truth
def map_to_gt(overlaps):
prior_overlap,prior_idx = overlaps.max(dim=1)
sec_overlap,sec_idx = overlaps.max(dim=0)
sec_overlap[prior_idx] = 4.99
for i,o in enumerate(prior_idx):
sec_idx[o] = i
return sec_overlap,sec_idx
class SSD_MultiHead(nn.Module):
def __init__(self, k, bias, dls, drop=0.4):
super().__init__()
self.drop = nn.Dropout(drop)
self.sconv0 = StdConv(512,256, stride=1, drop=drop)
self.sconv1 = StdConv(256,256, drop=drop)
self.sconv2 = StdConv(256,256, drop=drop)
self.sconv3 = StdConv(256,256, drop=drop)
self.out0 = OutConv(k, 256, bias, dls)
self.out1 = OutConv(k, 256, bias, dls)
self.out2 = OutConv(k, 256, bias, dls)
self.out3 = OutConv(k, 256, bias, dls)
def forward(self, x):
x = self.drop(F.relu(x))
x = self.sconv0(x)
x = self.sconv1(x)
o1c,o1l = self.out1(x)
x = self.sconv2(x)
o2c,o2l = self.out2(x)
x = self.sconv3(x)
o3c,o3l = self.out3(x)
return [torch.cat([o1c,o2c,o3c], dim=1), # box
torch.cat([o1l,o2l,o3l], dim=1)] # clas
anc_grids = [4, 2, 1]
anc_zooms = [0.75, 1., 1.3]
anc_ratios = [(1., 1.), (1., 0.5), (0.5, 1.)]
anchor_scales = [(anz*i,anz*j) for anz in anc_zooms
for (i,j) in anc_ratios]
# *** Number of Anchor Scales
k = len(anchor_scales)
# ***************************
import numpy as np
anc_offsets = [2/(o*2) for o in anc_grids] #2 is the h,w in fastai 1.0 (-1,1)
anc_x = np.concatenate([np.repeat(np.linspace(ao-1, 1-ao, ag), ag)
for ao,ag in zip(anc_offsets,anc_grids)])
anc_y = np.concatenate([np.tile(np.linspace(ao-1, 1-ao, ag), ag)
for ao,ag in zip(anc_offsets,anc_grids)])
anc_ctrs = np.repeat(np.stack([anc_x,anc_y], axis=1), k, axis=0)
anc_sizes = np.concatenate([np.array([[2*o/ag,2*p/ag]
for i in range(ag*ag) for o,p in anchor_scales])
for ag in anc_grids]) #2/grid * scale,2 is the h,w in fastai 1.0
grid_sizes = torch.tensor(np.concatenate([np.array([ 1/ag
for i in range(ag*ag) for o,p in anchor_scales])
for ag in anc_grids])).unsqueeze(1) *2 #again fastai 1.0 h,w is 2
anchors = torch.tensor(np.concatenate([anc_ctrs, anc_sizes], axis=1)).float()
anchor_cnr = cthw2corners(anchors)
anchors = anchors.to(device)
anchor_cnr = anchor_cnr.to(device)
# 自己的SSD模型
class SSDModel(Module):
def __init__(self, arch=models.resnet34, k=9, drop=0.4, no_cls=21):
super().__init__()
self.k = k
self.body = create_body(arch(True))
self.backbone = self.body
self.drop = nn.Dropout(0.2)
self.std_conv_0 = conv2_std_layer(num_features_model(self.body), 256, drop=drop,stride=1)
# Dimension-reducing layers
self.std_conv_1 = conv2_std_layer(256, 256, drop=drop, stride=2) # 4 by 4 layer
self.std_conv_2 = conv2_std_layer(256, 256, drop=drop, stride=2) # 2 by 2 layer
self.std_conv_3 = conv2_std_layer(256, 256, drop=drop, stride=2) # 1 by 1 layer
# Standard layers
self.ssd_conv_1 = conv2_ssd_layer(256, k=self.k, no_cls=no_cls)
self.ssd_conv_2 = conv2_ssd_layer(256, k=self.k, no_cls=no_cls)
self.ssd_conv_3 = conv2_ssd_layer(256, k=self.k, no_cls=no_cls)
# self.criterion = FocalLossMy()
self.device = device
self.anchors = anchors
def forward(self, *x):
imgs, targets = x if len(x)==2 else(x[0], None)
xb = self.drop(F.relu(self.body(imgs)))
xb = self.std_conv_0(xb)
xb = self.std_conv_1(xb)
bb1, cls1 = self.ssd_conv_1(xb) # 4 x 4
xb = self.std_conv_2(xb)
bb2, cls2 = self.ssd_conv_2(xb) # 2 x 2
xb = self.std_conv_3(xb)
bb3, cls3 = self.ssd_conv_3(xb) # 1 x 1
# bboxes = torch.cat([bb1, bb2, bb3], dim=1)
# clases = torch.cat([cls1, cls2, cls3], dim=1)
preds = [torch.cat([bb1, bb2, bb3], dim=1),
torch.cat([cls1, cls2, cls3], dim=1)]
return preds
# if targets is not None: # 训练过程
# cls_loss, reg_loss = self.criterion(preds, targets, self.anchors)
# return {"cls_loss": cls_loss, "reg_loss":reg_loss}
# else:#验证过程
# predsOut = self.postprocess(imgs, self.anchors, preds)
# return predsOut
def postprocess(self, x, anchors, preds):
return None
loss_f = FocalLoss(21)
def ssd_1_loss(b_c,b_bb,bbox,clas,print_it=False):
bbox,clas = un_pad(bbox,clas)
a_ic = act_to_bbox(b_bb, anchors) # 之前的代码是有问题的,应该先转换激活元
overlaps = iou(bbox.data, anchor_cnr.data)
gt_overlap,gt_idx = map_to_gt(overlaps) # 找到真实的anchor
gt_clas = clas[gt_idx]
pos = gt_overlap > 0.4
pos_idx = torch.nonzero(pos)[:,0]
gt_clas[~pos] = 0
gt_bbox = bbox[gt_idx]
# loc_loss = ((a_ic[pos_idx] - gt_bbox[pos_idx]).abs()).mean()
loc_loss = ((TensorBase(a_ic[TensorBase(pos_idx)]) - TensorBase(gt_bbox[TensorBase(pos_idx)])).abs()).mean()
clas_loss = loss_f(b_c, gt_clas)
return loc_loss, clas_loss
def ssd_loss(pred,*targ,print_it=False):
lcs,lls = 0.,0.
for b_bb,b_c,bbox,clas in zip(*pred,*targ):
loc_loss,clas_loss = ssd_1_loss(b_c,b_bb,bbox,clas,print_it)
lls += loc_loss
lcs += clas_loss
if print_it: print(f'loc: {lls.data}, clas: {lcs.data}')
# bce_loss就注释掉
# if print_it: print(f'loc: {lls.data[0]}, clas: {lcs.data[0]}')
return lls+lcs
@delegates(SSDModel)
def get_ssd_model(arch_str, num_classes, pretrained=True, pretrained_backbone=True,
trainable_layers=5, **kwargs):
model = SSDModel(arch=arch_str, no_cls=num_classes)
return model
ssd_resnet34 = partial(get_ssd_model, arch_str=models.resnet34)