接踵而至,昆仑万维天工大语言模型发布
目录
- 天工大语言模型
- 对标GPT3.5
- 对话能力
- 多模态应用
- 同行对比
- 后言
天工大语言模型
国产ChatGPT再次迎来新成员,4月17日下午,昆仑万维正式发布千亿级大语言模型“天工”,同时宣布即日起启动邀请测试,并注册了chatgpt.cn作为域名。天工大语言模型是国内首个对标ChatGPT的双千亿级大语言模型,通过自然语言与用户进行问答式交互,AI生成能力可满足文案创作、知识问答、代码编程、逻辑推演、数理推算等多元化需求。
根据官网介绍,“天工作为一款大型语言模型,拥有强大的自然语言处理和智能交互能力,能够实现智能问答、聊天互动、文本生成等多种应用场景,并且具有丰富的知识储备,涵盖科学、技术、文化、艺术、历史等领域”。
天工较前面国内发布的各个大语言模型区别不大,均侧重于中文应用场景,一方面是训练数据来源方便,另一方面是在国内与同等产品竞争要比去海外与OpenAI竞争更为容易,ChatGPT都被各国或禁用或限制,更不用说我们的产品了。
本次体验只有获得邀请的用户才可在“天工”官网登录体验。
对标GPT3.5
根据昆仑万维官方表态,天工大模型参数规模达千亿级,其水平已经非常接近OpenAI ChatGPT的智能水平,ChatGPT是基于GPT3.5大模型,所以昆仑万维把这个版本命名为“天工”3.5。
天工能够得出接近GPT3.5的水平是经过了统一标准的测试的。在GPT-3.5、GPT-4的论文中都附了相应的大型测试数据集,目前可能有将近20类,涵盖了大模型多维度的各项能力测试。天工以及其他大模型在发布产品前都会用这些数据做评测,根据这些公开数据的测试,得到了天工可以对标GPT3.5的结论。
对话能力
当前版本下,最高能够支持1万字以上文本对话,实现20轮次以上用户交互。不得不说,其联系上下文多次作答的能力已经非常出众了,20轮交互已经可以实现用户进行对话纠偏的需求,直到用户获取到令人满意的答案。
由于无法实际测试,目前还不清楚天工的联系上下文的真实能力,但单问单答是挺OK的。
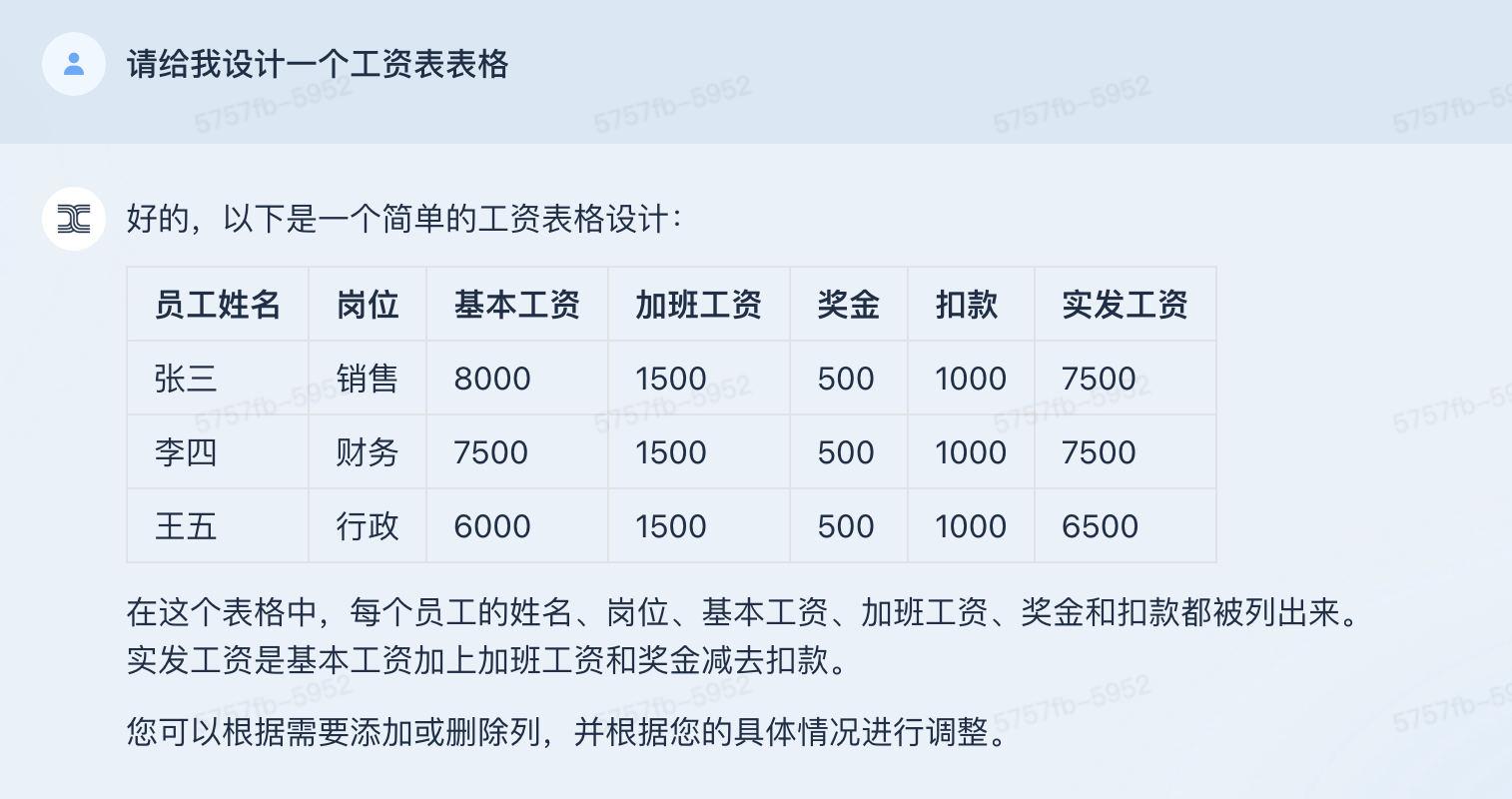
下面是天工设计的工资表表格,能够列出一张工资条的常见条目,并可以计算实发工资,但实发工资全部都是不正确的,令人遗憾。
多喝热水以前是一句标准的关心女朋友的话,但随着大家无限滥用,现在已经成为了一个梗。相信不少程序员兄弟会有感受,不说这句话还好,说了反而可能引发女朋友的怒火。这时,你应该问问天工了,女朋友身体不舒服,给她说“多喝热水”会有什么后果?看看天工的作答,可比咱们这些直男强多了,标准暖男。

通过上面的对话可以看到,天工文本生成能力是具备了,但是如同360大模型一样,准确度还有所欠缺。另外,虽然昆仑天工AIGC全系列算法与模型覆盖了图像、音乐、文本、编程,但此次发布的是大语言模型,没有图像和音乐生成能力,也未体现编码能力。
多模态应用
在此次大语言模型发布前,昆仑万维曾在2022年12月发布了AIGC全系列算法与模型,覆盖了图像、音乐、文本、编程等多模态的AI内容生成能力,分别命名为天工巧绘SkyPaint、天工乐府SkyMusic、天工妙笔SkyText、天工智码SkyCode。

天工乐府、天工智码都是基于自研的天工系列模型,天工巧绘的下游基于Stable Diffusion模型。在这次天工3.5大模型正式推出后,昆仑万维CEO方汉表示可以用来替代天工多模态应用的底层模型。
可以预见,昆仑万维将依靠天工大模型为底座,对天工系列应用进行升级和融合,提升全系列生成式AI的能力。GPT-4具备图像生成能力,GPT-5将具备视频生成能力。天工若要实现天工4、天工的目标,整合图像,音频,视频和编程能力,势在必行。
同行对比
在OpenAI ChatGPT点燃人工智能火炬的情况下,国产ChatGPT产品如雨后春笋般不断涌现。天工与同行相比,优势并不明显。
首先是算力,GPT的能力是训练出来的,决定其能力的最核心要素是三个,算法,数据量和算力,能用多大的数据量进行训练,最后还是要看拥有的算力有多大。当前昆仑万维有用200张卡的训练集群,百度文心一言有约1000张卡的训练资源,ChatGPT训练需要用到1万多片英伟达A100 GPU,加上其他应用,对应芯片需求为3万多片GPU。可以看到,天工在核心的算力支持上,与其他大佬还有不小差距。
其次是应用,昆仑万维基于原有的图像、音乐、文本、编程多模态的AI内容生成能力,加上现在天工大语言模型的发布,试图构建一个如同商汤日日新的大模型体系的想法显而易见。以昆仑的体量,明显无法像百度和微软一样支撑C端大量用户,而是与国内其他ChatGPT类产品一样,面向B端。在B端市场,已经发布的阿里和商汤,产品成熟度要领先于昆仑,尤其前者可以通过接入阿里系所有APP来获取用户,从而获得大量用户使用数据进行升级迭代。
后言
虽然天工大模型还有许多不足,还有很长的路要走,但成功发布大模型意味着昆仑拿到了AI盛宴的入场门票。从此,国产大模型又多了一言,作为普通用户,希望竞争越激烈越好,一个有活力有竞争的市场,能够给普通人带来更多机会和受益。