体验 nanoGPT
体验 nanoGPT
- 1. 使用预训练模型
- 2. 训练自己的模型
- 2-1. 准备训练数据
- 2-2. 模型训练
- 2-3. 模型验证
1. 使用预训练模型
在我们尝试训练自己的模型之前,我们先使用其他人训练好的模型,看看如何在自己的环境中运行聊天机器人。
今天我们使用 GPT4ALL 并从 hugging face 下载训练好的模型进行测试。
首先下载模型,我们使用来自 hugging face 的预训练模型。
sudo apt install -y git-lfs
git lfs install
git clone https://huggingface.co/decapoda-research/llama-7b-hf
需要注意的是,该模型下载之后不能执行,会报配置错误,经过检查之后发现,模型的作者在编写配置文件时,出现了拼写错误。
请将tokenizer_config.json 文件按照如下格式修改即可:
sed -i 's/LLaMATokenizer/LlamaTokenizer/g' ./llama-7b-hf/tokenizer_config.json
安装依赖,
pip3 install nomic peft sentencepiece protobuf==3.20.3
然后我们使用如下代码,问聊天机器人,清华大学在哪里?看看它的回答。
import warnings
warnings.filterwarnings("ignore")
from nomic.gpt4all import GPT4AllGPU
m = GPT4AllGPU('llama-7b-hf/')
config = {'num_beams': 2,
'min_new_tokens': 10,
'max_length': 100,
'repetition_penalty': 2.0}
out = m.generate('where is qinghua university?', config)
print(out)
它的回答基本正确,但又说了一些和问题无关的信息,

2. 训练自己的模型
之前使用预制模型,只是为了让大家了解如何运行GPT聊天机器人,而真正为企业服务的是使用我们自己训练的模型。
这里我们将使用另外一个模型 nanoGPT,它是用于训练/微调中型 GPT 的比较简单、相对快速的软件库。
它是以 minGPT 为基础的重新实现版本,该模型目前仍在积极开发中。
首先需要满足nanoGPT的运行条件。
pytorch <3
numpy <3
pip install transformers for huggingface transformers <3 (to load GPT-2 checkpoints)
pip install datasets for huggingface datasets <3 (if you want to download + preprocess OpenWebText)
pip install tiktoken for OpenAI's fast BPE code <3
pip install wandb for optional logging <3
pip install tqdm <3
执行下面命令安装依赖,
pip3 install torch numpy transformers datasets tiktoken wandb tqdm
然后需要克隆nanoGPT的存储库。
git clone https://github.com/karpathy/nanoGPT.git; cd nanoGPT
2-1. 准备训练数据
你可以将自己的文本作为训练集,并将他们放在data文件夹中。在今天的示例中,我们将使用莎士比亚的作品作为我们的训练集,所以我们首先从网络下载一个1MB左右的文本文件,并对它进行数字化转换。
python3 data/shakespeare_char/prepare.py
--- output
length of dataset in characters: 1,115,394
all the unique characters:
!$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
vocab size: 65
train has 1,003,854 tokens
val has 111,540 tokens
---
2-2. 模型训练
在训练数据准备完毕后,我们将启动模型的训练。
python3 train.py config/train_shakespeare_char.py
通过 watch -n 1 nvidia-smi 对GPU状态的观察,我们可以看到GPU现在已经几乎满负荷运行。
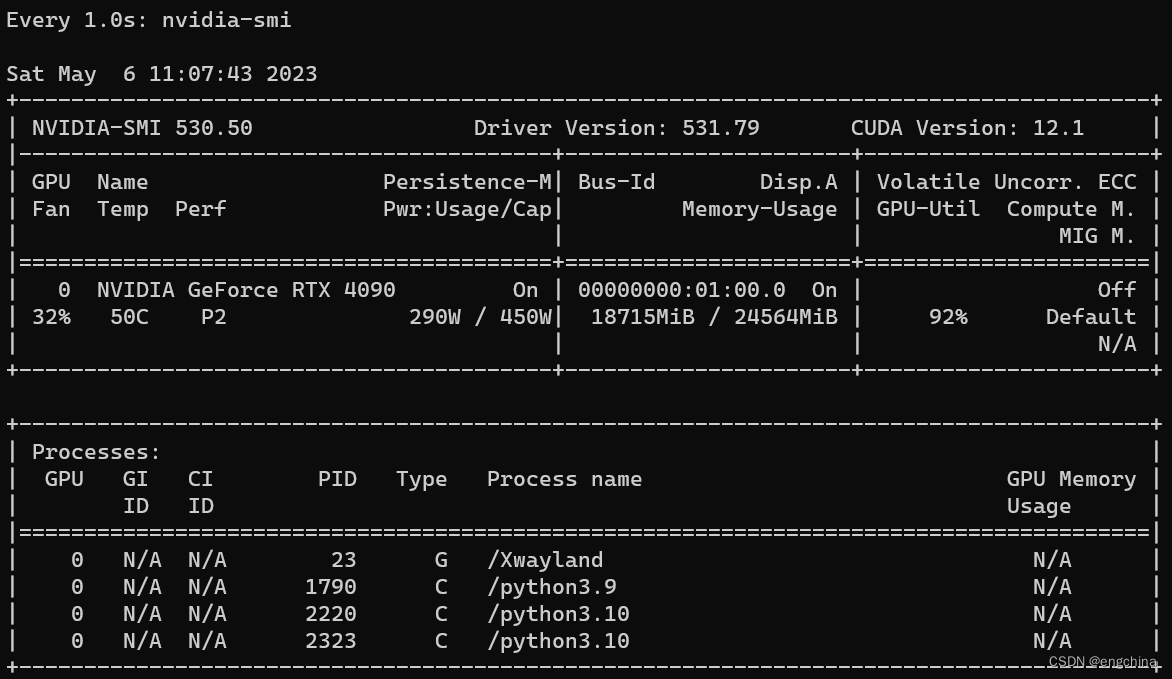
我们的训练需要进行 5000 次迭代,运行时间大概为 3 分钟左右。之前在Intel IceLake系列 16 cores 的 CPU,128GB 内存环境中完成相同的训练需要 12 个小时,使用英伟达 A10 单卡 GPU 之后,效率提升 90 倍(注:不同模型,不同训练数据,情况不同。90 倍只是本次实验所属情况),在验证集上得到的 min loss 为 1.7075,在没有对模型进行精细调整的情况下,目前的指标还令人满意。

2-3. 模型验证
通过我们刚才生成的 best 模型,我们让它生成一些文字,看看是否满足我们的要求。
python3 sample.py --out_dir=out-shakespeare-char
因为我们没有对模型进行调整,所以现在它的表现不是很理想,当对模型参数进行调整,调高某些参数值(有些参数值需要降低)之后,利用多块 GPU 同时训练,估计会得到更高的结果。一旦您的模型达到预期,就可以请前端工程师帮您制作精美的页面,然后调用您的模型进行工作了。
完结!