【头歌】完整汇编语言程序设计
摘自头歌实训
目录
相关知识
1.1 RISC-V 汇编语言程序基本结构
1.2 RISC-V 汇编语言程序主要元素
1.2.1 汇编指令
1.2.2 标签
1.2.3 汇编指示语句
1.3 RISC-V 汇编语言程序示例
相关知识
RISC-V 操作数类型、基本调用约定等已在前序关卡中介绍,前序关卡主要完成 C 语言基本语句到 RISC-V 汇编指令的转换。本关卡将通过一个简单的 C 语言程序与其对应的 RISC-V 汇编语言程序向同学们介绍完整的汇编语言程序的基本结构。
1.1 RISC-V 汇编语言程序基本结构
RISC-V 汇编语言表示为文本文件,主要包含四种主要元素:
- 汇编指令(Assembly instructions):包含助忆符和相关参数序列(即操作数)的字符序列,可被汇编器转换成机器指令。例如,字符串
addi a0, a1, 1包含助忆符addi及其操作数a0、a1和1- 汇编指示语句(Assembly directives):用于辅助汇编的命令,通过汇编器转换成实际的若干条汇编指令,或通过汇编器进行解释。例如,指示语句
.word 10告诉汇编器将一个 32 位 (.word)的值10汇编到程序中。汇编指示语句编码为字符串,包含一个以点(.)为前缀的指示语句名(directive name)及其对应的参数- 注释(Comments):用于提示代码相关信息,不影响目标代码生成,汇编器处理时丢弃注释语句
- 标签(Labels):表示程序位置,通常用冒号(
:)标记,可以用于标记程序位置,其他汇编指令或者汇编命令(如汇编指示语句)可通过标签查找程序位置
汇编器丢弃注释等操作通过一个汇编前处理过程实现,将所有注释丢弃,并删除多余的空格,处理后的汇编程序仅包含三种元素:标签、汇编指令和汇编指示语句。若分别用 <label>、<instruction>、<directive> 表示有效的标签、汇编指令和汇编指示语句,则完成的汇编语言程序可以用下图所示的正则表达式表示:

即:
程序(PROGRAM)由若干行(LINES)组成若干行(LINES)包含至少一行(LINE),该行后可以通过换行符出现其他行一行(LINE)有以下形式:
- 空行(
[x]代表 x 是可选内容,可以不出现)- 仅包含一个标签
- 包含一个标签、后跟一条汇编指令
- 仅包含一条汇编指令
- 包含一个标签、后跟一条汇编指示语句
- 仅包含一条汇编指示语句
1.2 RISC-V 汇编语言程序主要元素
1.2.1 汇编指令
汇编指令主要包含实际汇编指令和伪指令,其中的汇编指令可直接与 RISC-V 指令对应,例如 addi x0, x0, 0 可直接对应机器指令 00000013 (十六进制形式)。伪指令则没有直接对应的 RISC-V 指令,但是汇编器会将伪指令转换为若干条对应功能的机器指令,例如 nop 伪指令代表 空操作,该指令不存在实际的 RISC-V 对应指令,但是由于 addi x0, x0, 0 指令相当于不执行任何操作,因此汇编器将伪指令 nop 转换为 addi x0, x0, 0;mv 伪指令代表将一个寄存器的值复制到另一个寄存器,因此伪指令 mv a5, a7 可以转换为实际指令 addi a5, a7, 0
汇编指令中的操作数主要包含下列类型:
- 寄存器名:表示所有 ISA 寄存器中的某个寄存器,可以是通用的编号名称,即 x0 到 x31,也可以是按照调用约定规定的寄存器别名。例如,第 5 号寄存器的寄存器名可以是
x5,也可以是t0(临时寄存器)- 立即数值:立即数值是直接编码在机器指令中的常数值
- 符号名:符号名可以在符号表中找到对应的符号,在汇编和链接的过程中会替换为实际符号表达的数值,可以是用户自定义的符号名,也可以是汇编器自动生成的符号名(例如标签对应的符号名)
1.2.2 标签
标签可用于标记程序位置,可以标记指令和汇编指示语句的位置,在汇编和链接的过程中被翻译为实际的地址。GNU 汇编器通常接受两种类型的标签:符号标签和数字标签。
符号标签存储为符号表中的符号,用于标识全局变量和子程序,符号标签定义为标识符及冒号(例如:label:)。
数值标签则由十进制数字及冒号定义(例如:1:),用于局部参考,不出现在可执行文件的符号表中,在同一个汇编程序中可以反复重定义。对数值标签的引用需要包含后缀以表明数值标签的位置在引用之前(后缀 b) 或者引用之后(后缀 f)。

以上图所示的数值标签为例,图中包含数值标签 1,该标签定义了两次,其中,指令 beqz a1,1f 引用的标签位置为第二个标签(即该指令出现之后的标签 1),指令 j 1b 引用的标签位置则为第一个标签(即该指令出现之前的标签 1)。
1.2.3 汇编指示语句
汇编指示语句表示为前缀 . 加上一个标识符,用于控制汇编器行为,例如汇编指示语句 .section .data 表示指导汇编器将 .data 段转换为活跃段(active section),.data 10 汇编指示语句则表示指导汇编器汇编一个 32 位数值,并将其添加到当前的活跃段。
汇编指示语句的主要作用包括:
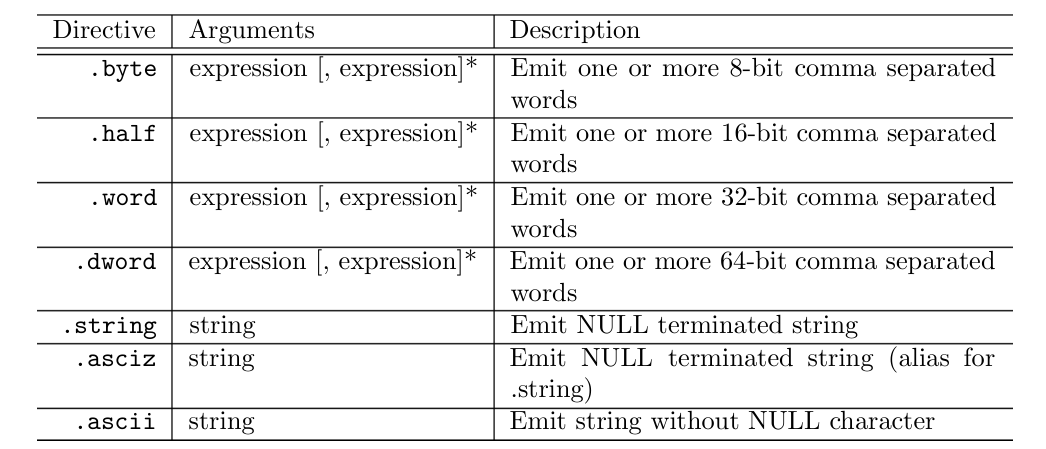
- 向程序中添加数值,例如
.byte汇编指示语句添加若干个 8 比特的数据、.string汇编指示语句添加一个以空字符 NULL 结尾的字符串,用于添加数值的汇编指示语句如下图所示:
.section汇编指示语句。RISC-V 汇编语言程序以“段”(section)的形式组织,每个段包含数据或指令,每个段映射到主存中的一段连续地址空间,对于 Linux 系统,RISC-V 编译器生成的可执行文件通常包含下列段:.text:存储程序指令的段,即 代码段;.data:存储 初始化的全局变量 的段;.bss:存储 未初始化全局变量 的段;.rodata:存储常量的段,即 只读数据段。.section secname汇编指示语句汇编器处理的该语句之后的所有信息添加到 名为 secname 的段中
1.3 RISC-V 汇编语言程序示例
本节以一个简单的 C 语言程序及其对应的汇编语言程序介绍完整的 RISC-V 汇编语言程序结构。
以如下的 C 语言程序为例,该程序定义全局变量 n (整型) 及 fibonacci_array (长度为 100 的整型数组),在该程序的 main 函数中,将数组 fibonacci_array 的前两个元素初始化为 1,该数组存储一个斐波那契数列,本程序计算数组的前 n+1 个元素的数值:
#include <stdio.h>
int n = 10;
int fibonacci_array[100];
int main() {
fibonacci_array[0] = 1;
fibonacci_array[1] = 1;
int i;
for(i = 2; i <= n; ++ i) {
fibonacci_array[i] = fibonacci_array[i-2] + fibonacci_array[i-1];
}
printf("%d", fibonacci_array[n]);
return 0;
}若只保留核心功能对应的汇编指令,上述的 C 语言程序对应的 RISC-V 汇编语言程序可以写为:
.data
n: .word 10
fibonacci_array: .zero 400
.text
main:
addi x5, x0, 1
la x6, fibonacci_array
sw x5, 0(x6)
sw x5, 4(x6)
la x7, n
lw x7, 0(x7)
addi x28, x0, 2
for_loop:
blt x7, x28, end_loop
# load fibonacci_array[i-2] to x29
addi x29, x28, -2
slli x29, x29, 2
add x29, x6, x29
lw x29, 0(x29)
# load fibonacci_array[i-1] to x30
addi x30, x28, -1
slli x30, x30, 2
add x30, x6, x30
lw x30, 0(x30)
# add x29 (fibonacci_array[i-2]) and x30 (fibonacci_array[i-1]) to x31
add x31, x29, x30
# store x31 to fibonacci_array[i]
addi x29, x28, 0
slli x29, x29, 2
add x29, x6, x29
sw x31, 0(x29)
# i = i + 1
addi x28, x28, 1
j for_loop
end_loop:
addi x29, x7, 0
slli x29, x29, 2
add x29, x6, x29
lw x29, 0(x29)
addi a7, x0, 1
addi a0, x29, 0
ecall
addi a7, x0, 10
ecall示例的 C 语言程序和 RISC-V 汇编语言程序对应关系如下图所示(单击图片可放大查看):
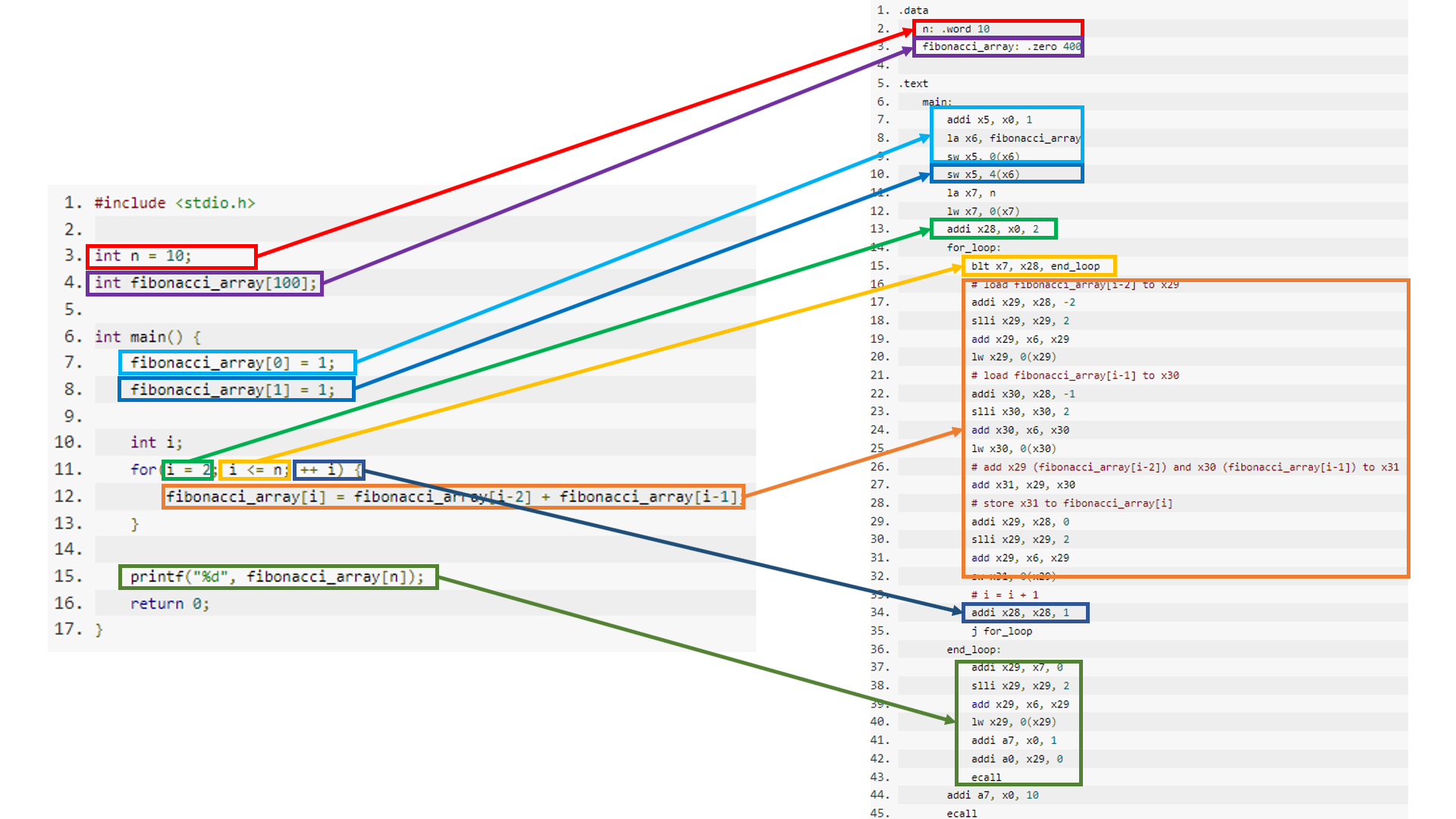
其中:
- 全局变量的定义通过汇编指示语句实现,即在
.data段定义初始化的全局变量,在该例子中,.data段内定义了整型变量n,整型类型为 4 字节,对应 RISC-V 中的一个“字”,因此其定义语句为n: .word 10,该指示语句由三部分组成,即标签、数据类型、变量值,分别对应变量名称、变量大小、变量数值;.data段还定义了整型数组fibonacci_array,该数组类型为整型、长度为 100,故其大小为 400 字节,其定义语句为fibonacci_array: .zero 400,该指示语句表示为fibonacci_array初始化 400 字节的内存空间,每个字节数值设置为 0,即定义长度为 100 的整型数组,并将数组元素值初始化为 0。- 变量的赋值通过组合一系列指令实现,该例子中,局部变量 i 直接存储在 x28 寄存器中,因此 i 的赋值可直接通过运算类指令
addi实现;实际情况下的变量通常存储在内存区域中,则此时变量的运算和赋值需要通过访存指令和运算类指令实现,如例子中对fibonacci_array[0]=1的实现可分为如下步骤:
- 运算赋值语句右边表达式的值。本例中该值为常数 1,因而直接由指令
addi x5, x0, 1得到赋值语句的右表达式值,并将其存放在 x5 寄存器中- 获取变量内存地址。本例中通过伪指令
la x6,fibonacci_array将数组的地址存放在 x6 寄存器中- 存储变量值。本例中,
fibonacci_array[0]的地址可由fibonacci_array作为基地址、0 (即 0 * 4)作为偏移量计算得到,因此,可由指令sw x5, 0(x6)将赋值语句的右表达式值(当前存储在 x5 寄存器中)存储到变量对应的内存区域- 库函数的调用遵循子程序调用流程,但实际实现时候输入/输出功能由系统调用实现,在本例中,printf 函数仅输出一个整型数值,该功能可由系统调用直接实现,若编译器中规定该系统调用功能编号为 1、系统调用功能选择由 a7 寄存器指定,则本例中的
printf("%d", fibonacci_array[n]);语句的实现可分为如下步骤:
- 获取输出整型的数值。由于变量 n 的地址已经通过伪指令
la x7, n存放在 x7 寄存器中,故由addi x29, x7, 0和slli x29, x29, 2两条指令计算fibonacci_array[n]相对于fibonacci_array的偏移量(由于数组类型为整型,故偏移量为 n * 4,实际可通过逻辑左移两位实现等价功能);此例中数组 fibonacci_array 的地址已经通过伪指令la x6, fibonacci_array存放在 x6 寄存器中,因此fibonacci_array[n]的实际地址可以通过 x6 寄存器内容加上偏移量得到,即指令addi x29, x6, x29计算fibonacci_array[n]的实际地址并将其存放在 x29 寄存器中;最后,通过lw x29, 0(x29)指令将该数组元素的实际值从内存中加载到 x29 寄存器- 设置系统调用编号及参数。本例使用的 RISC-V 汇编语言假设约定系统调用编号存放在 a7 寄存器中、参数存放在 a0 寄存器中,且打印整型数值的系统调用编号为 1,因此,可以通过指令
addi, a7, x0, 1设置选择打印整型数值,通过指令addi a0, x29, 0将获取的整型数值存放在参数寄存器中,通过指令ecall完成系统调用- main 函数执行
return 0;后实际程序还有其他处理流程,本例子中假设 main 函数执行return 0;表示程序完成功能、退出执行,因而可以通过 10 号系统调用退出程序执行。注意:实际的完整汇编程序中,return 0;语句执行后会返回到调用 main 函数的地方继续执行
系统调用的知识——是否联想到PWN中的ret2syscall了呢?