2023年4月的12篇AI论文推荐
GPT-4发布仅仅三周后,就已经随处可见了。本月的论文推荐除了GPT-4以外还包括、语言模型的应用、扩散模型、计算机视觉、视频生成、推荐系统和神经辐射场。
1、GPT-4 Technical Report
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang.
GPT-4 在上个月一直是无可争议的明星。这篇评估报告包含了 GPT-4 实验的样本和操作。论文中一个有意思的事情是在 TikZ (LaTeX) 中绘制独角兽的能力如何随着时间的推移而改进,而模型仍在积极开发中。
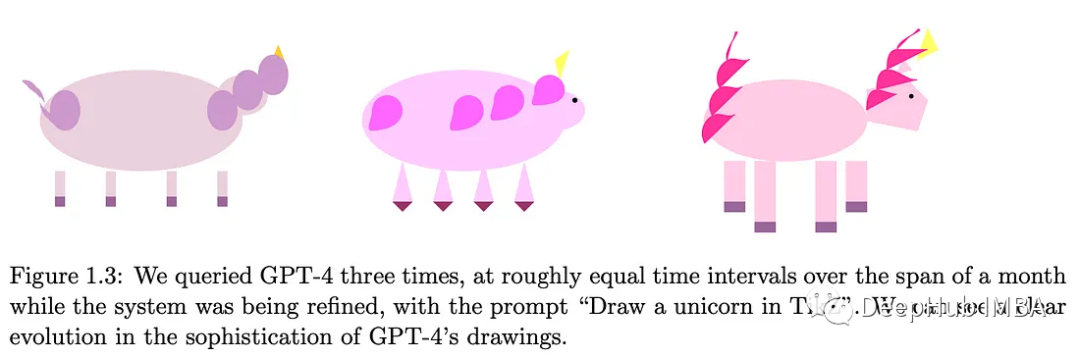
这份长达 155 页的评估报告涵盖了广泛的主题,例如多模式能力、数学推理、编码、人际互动和社会影响。作者认为 GPT-4 表现出的一些行为可以被标记为一般智能,同时承认其局限性和警告。
2、Larger language models do in-context learning differently
Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, Tengyu Ma.
大型语言模型中复杂语境学习的出现引起了大家的兴趣。本文深入研究了大型语言模型中一些小众但很有意思的功能,这些功能在小型语言模型中是不存在的。
大型模型拥有独特的能力,小型模型根本无法复制,无论投入多少数据和精力。例如,大型模型可以在提示内学习翻转标签和学习新的映射,例如反转句子的情感标签(例如,积极的句子被标记为消极的)。
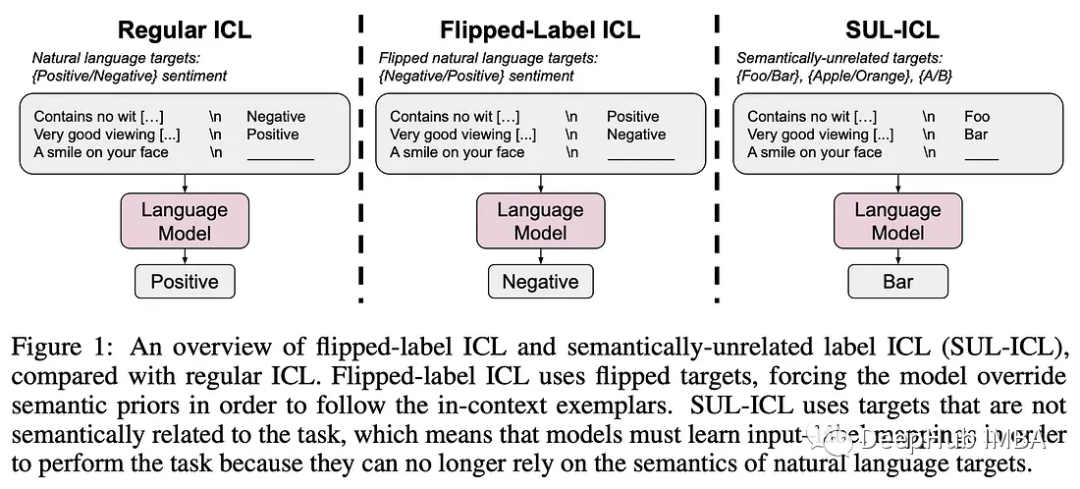
- 大型模型学习翻转标签,而小型模型则坚持预先训练好的知识,继续将正标记为正,将负标记为负。
- 语义无关标签(SUL)随着规模的扩大而出现,其中模型用非单词的标记标记事物。
- 指令调优模型加强了语义先验的使用和学习输入标签映射的能力,但是更强调前者。
3、Reflexion: an autonomous agent with dynamic memory and self-reflection
Noah Shinn, Beck Labash, Ashwin Gopinath.
将 LM 嵌入自我改进循环的技术非常流行!我们人类并不总是在第一次尝试时就把事情做好。为了解决问题,我们通常依赖于尝试一条推理路径,然后在它完全展开后验证它的有效性。如果没有,我们会尝试纠正它,直到整件事情都变得有意义。而传统自回归 LM 没有这样的能力。
研究人员发现,为 LM 配备类似的机制可以提高它们的性能。简单地说,提示一个 LM,然后要求它反思它的输出并在必要时进行更正。这可以嵌入到一个环境中,LM可以知道一个答案或操作是否正确,然后尝试改进它,直到正确为止。
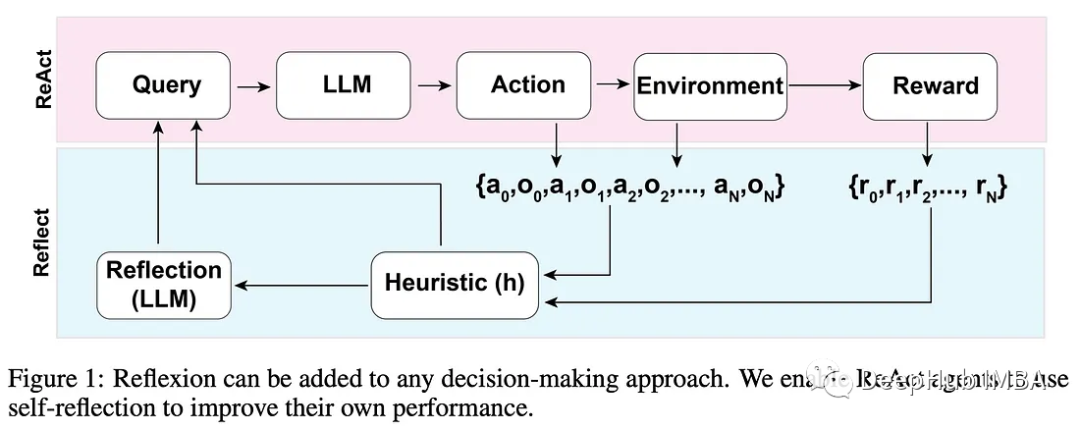
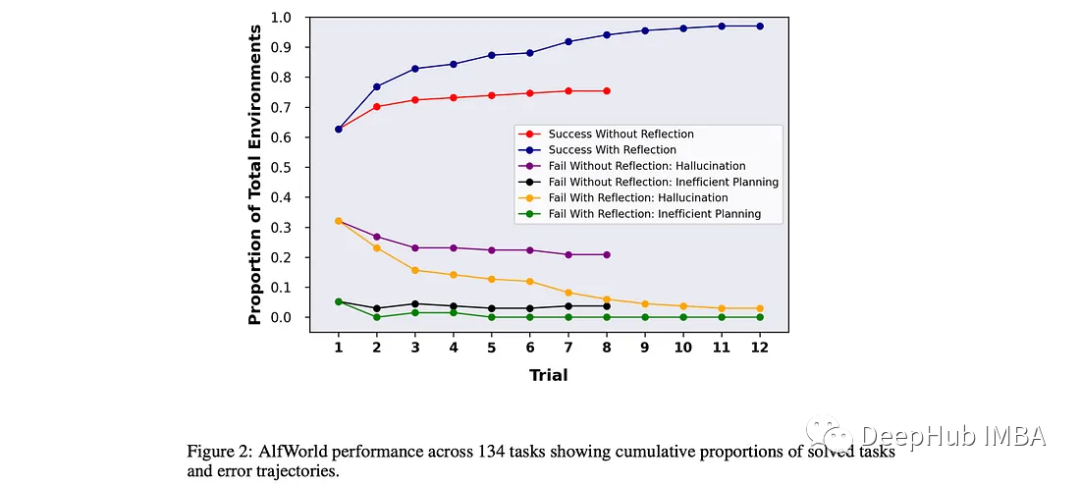
结果还是不错的
其他类似的论文还有《Self-Refine: Iterative refine with Self-Feedback》(更专注于指令遵循而不是问题解决),和《Language Models can Solve Computer Tasks》(专注于做面向目标的规划),它们遵循类似的“生成-批评-修复”反馈循环,主要基于启发式和模板化的自然语言,这也可以证明,现有的lm可以被视为一个新的平台,在其上构建东西,我们只是触及了可能的表面。
4、Foundation Models for Decision Making: Problems, Methods, and Opportunities
Sherry Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, Dale Schuurmans.
LM 似乎是一种非常有用的灰盒计算引擎。它们可以应用于语言以外的各种事物,例如决策。 作者考虑了在可以采取行动并观察奖励的环境中嵌入基础模型的一般情况。他们确定了 FM 可用于决策环境的几个角度:作为生成模型、表示学习者、代理或环境。
与强化学习 (RL) 中使用的特定于任务的交互式数据集相比,用于训练 FM 的视觉和语言领域的广泛数据集通常在模式和结构上有所不同。例如,视频数据集通常缺乏明确的动作和奖励标签,而这些是强化学习的重要组成部分。因为大多数用于决策模型的 FM 被概念化为通过行为克隆(如离线 RL)训练马尔可夫决策过程(MDP),这可能导致整个动作状态空间的覆盖率很低,理论上可以与 RL 微调,但最终在实践中很难。本文强调了弥合这一差距以增强 LM 在决策任务中的适用性的必要性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e392Jovw-1681355548210)(null)]
5、GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
Tyna Eloundou, Sam Manning, Pamela Mishkin, Daniel Rock.
我们经常听到关于人工智能将对就业市场产生影响的热门话题。这篇论文试图为各种职业量化这一点。
通过观察历史上主流未来主义者在预测哪些事情难以自动化以及 AI 将首先学习做什么方面表现得多么糟糕来作为序言。然后量化了使用 LM 的不同任务的生产力收益。
我们的分析表明,通过获得 LLM,美国大约 15% 的工人任务可以在相同质量水平下更快地完成。当合并构建在 LLM 之上的软件和工具时,这一份额增加到所有任务的 47% 到 56%。
论文里定义完成繁重工作的关键概念是“Exposure”,它被定义为访问 LLM 系统可以将人类执行特定任务所花费的时间减少至少 50% 的程度。不过,Exposure的影响仍不清楚:提高生产率和增加工资?减少可用职位?都算作Exposure但是具体哪一个还没有结论,论文里有一些数据表明在不同任务中使用 LM 辅助性能有多大的相关性。

6、Erasing Concepts from Diffusion Models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, David Bau.
高级的AICG最令人兴奋的地方在于它将如何实现全新的人机交互范式。本文提出了一种在使用扩散模型编辑图像时进行这种交互的方法。
作者介绍了一种称为擦除稳定扩散 (ESD) 的技术,该技术仅使用“不需要的”概念描述来微调模型的参数,而无需额外的训练数据。这种特别的方法可以很容易地集成到任何预训练的扩散模型中。例如,给定一张有树的田野图像,您可以简单地提示“擦除树”,输出将是没有树的“相同”图像。
ESD的主要目标是利用模型自身的知识,而不需要额外的数据就可以从文本到图像扩散模型中删除相应的内容。该方法采用潜在扩散模型(LDM),关注潜在空间而不是像素空间,并使用[稳定扩散]进行所有的实验。该技术针对3种类型的删除进行了优化:艺术效果(例如,取消梵高风格的过滤器),明确的内容和对象。下图为这些方法的例子:

7、Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, Humphrey Shi.
我们已经看到一些文本到“视频”的作品,例如 Meta 的Make-a-video(它更像是 GIF)。
仅使用现成的文本到图像模型并且不需要进一步训练的文本到视频呢?Text2Video-Zero 提出了一种将现有的文本到图像合成扩散模型转换为文本到视频模型的方法。这种方法可以使用文本提示或提示结合姿势或边缘的指导,甚至是指令指导的视频编辑来生成零样本的视频生成。 它完全无需训练,不需要强大的计算能力或多个 GPU,让每个人都可以生成视频。
还是使用扩散模型将图像与文本对齐的潜在表示空间中进行“运动”。虽然微动嵌入会在生成的视频中产生不连贯的运动,但这项工作提出了两种新颖的后处理技术,通过在潜在代码中编码运动动态并使用跨帧注意力重新编辑每个帧的自注意力来强制执行时间生成的一致性(参见 下图)。结果是在没有任何视频特定训练的情况下创建的连贯短视频。
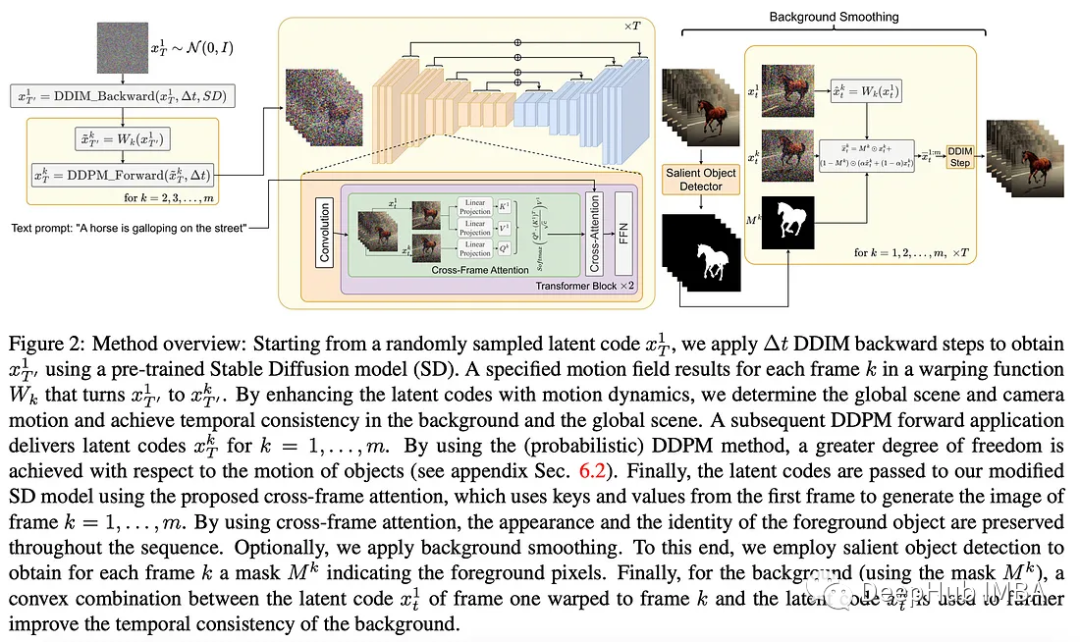
8、LERF: Language Embedded Radiance Fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, Matthew Tancik.
将nerf与现成的CLIP嵌入相结合,以获得优秀的语义分割和语言基础。LERF通过沿训练射线利用CLIP嵌入,并在多个训练图像上使用多尺度CLIP特征来监督它们,从而优化密集的多尺度3D语言场。这种优化可以为语言查询实时、交互式地提取3D相关性图。LERF支持长尾、开放词汇表的跨卷分层查询,而不依赖于区域提议、掩码或微调。
与2D CLIP嵌入相比,3D提供了对遮挡和视点变化的鲁棒性,以及更清晰的外观,更好地符合3D场景结构。多尺度监督和DINO正则化提高了对象边界和整体质量。
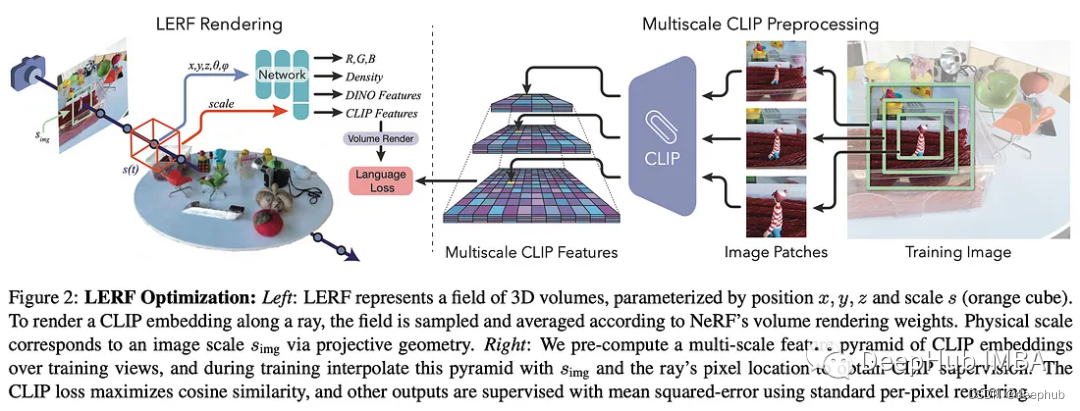
作者还展示了LERF如何与ChatGPT无缝集成,允许用户使用自然语言与3D世界进行交互。一个示例演示了ChatGPT如何为清理咖啡溢出提供语言查询(见下图)。这将很快被集成到流行的Nerfstudio研究代码库中。



9、Resurrecting Recurrent Neural Networks for Long Sequences
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, cagar Gulcehre, Razvan Pascanu, Soham De。
RNN 隐藏的潜力?Transformer 的注意力机制的计算复杂度意味着可能需要一定程度的重复性才能实现真正的远程依赖建模。递归神经网络 (RNN) 在深度学习中对序列数据建模至关重要,但众所周知,它存在梯度消失和爆炸问题,而 LSTM(某种程度上)在过去解决了这些问题。尽管如此,它们仍无法与Transformer 的显式自注意力相提并论。最近推出的 S4 是一种深度状态空间模型 (SSM),它克服了其中的一些问题,并在超长距离推理任务上取得了卓越的性能。本文证明,通过对深度传统 RNN 进行微小更改,线性循环单元 (LRU) 模型可以在LRA ( Long Range Arena) 基准测试中与深度 SSM 的性能和效率相媲美。
线性循环单元 (LRU) 是本文的核心架构贡献。传统 RNN 的修改包括线性化(去除循环连接中的非线性)、对角化(允许并行化和更快的训练)、稳定的指数参数化和归一化。
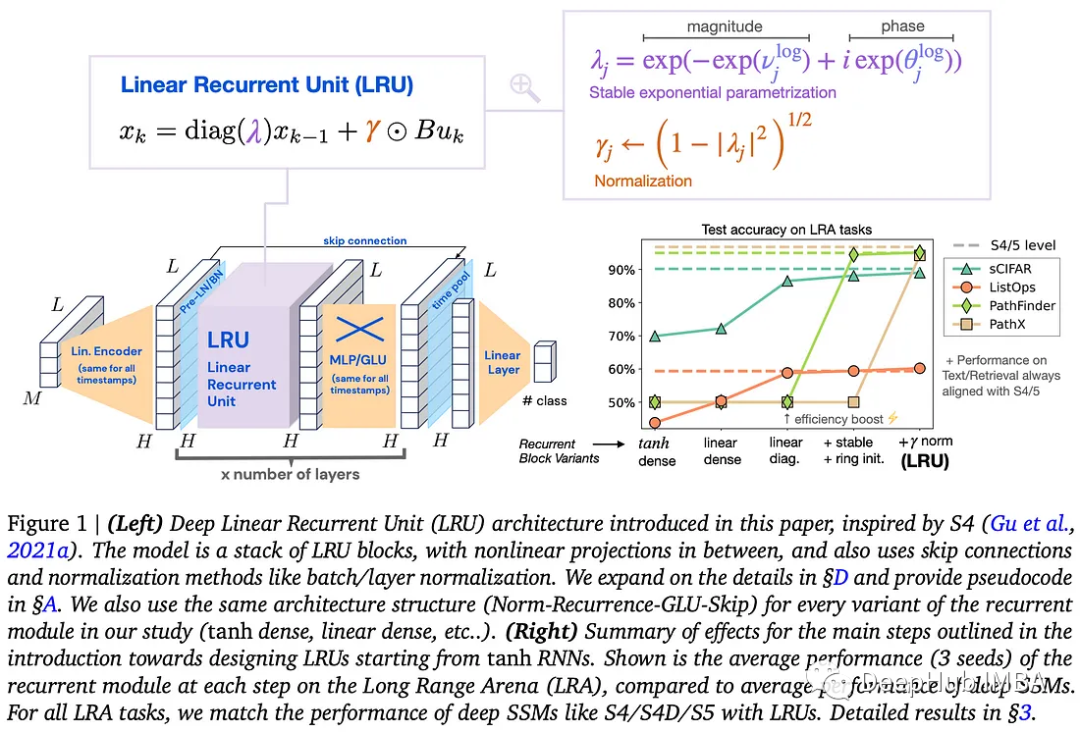
这篇论文再次展示了神经网络中的许多进步依赖于巧妙的优化,包括使训练更快、稳定和可扩展;而不是聪明的架构选择。虽然这不会很快取代Transformer ,但当需要线性推理的复杂性时,长距离的递归仍然是有用的。
10、 Recommender Systems with Generative Retrieval
Shashank Rajput et al.
还记得可微搜索索引(DSI)吗?现在他又开始折腾推荐系统了😒。
可微分搜索索引使用transformer 来记忆文档id,并根据查询自回归地生成它们,消除了对传统索引的需要。基于这一想法,研究人员提出了TIGER,一种基于生成检索的推荐模型。TIGER为每件商品分配唯一的语义ID,然后训练检索模型来预测用户将使用之前商品ID的下一件商品的语义ID。其实就是对这些id进行自回归建模。
与DSI基础实验不同的是,在这种情况下,id在语义上是相关的:它们使用条目的标题和文本描述来使用Sentence-T5对它们进行编码,然后应用残差量化以获得每个项目的量化表示。

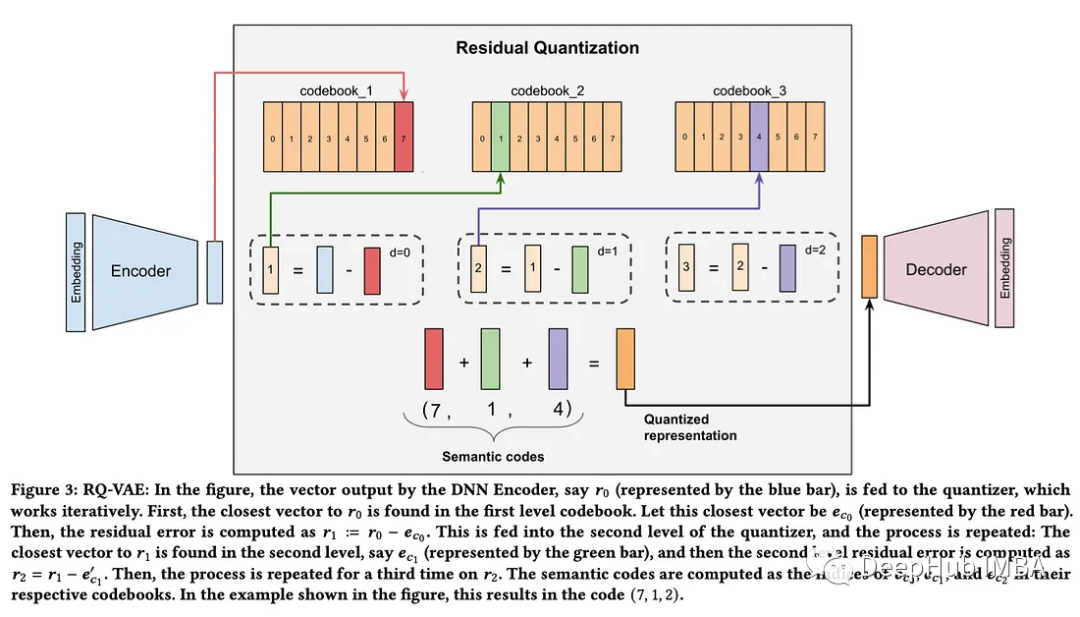
TIGER在亚马逊产品评论数据集的召回和NDCG方面击败了以前的最先进技术。尽管与DSI相关的缺点(向预训练的模型中添加新项目并不容易),但这种新的生成式检索范式确实提供了一些优势,例如推荐不常见的项目(改善冷启动问题),并通过调整生成的温度来生成多样化的推荐。
11、Segment Anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, Ross Girshick
meta发布的号称分割届的GPT,SAM已经了解了物体的一般概念,这种理解可以在不需要额外训练的情况下对不熟悉的物体和图像进行零样本泛化。
目测效果很不错,这个论文我在研究他的源代码,所以后续还有更详细的应用和解释。有兴趣的可以先看看他的demo网站
12、Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein
这篇论文展示了让生成式AI具备记忆、规划、沟通和反思的能力,让其像人类一样自然活动、社交、成长。论文使用的是GPT-3.5-turbo版本的ChatGPT,也就是说理论上可以为ChatGPT加上记忆、反思和规划等更高阶的人类能力,可有效提升大语言模型输出能力、稳定性和降低风险,同时在游戏领域有着巨大的应用空间。
1)AI自己建立了记忆体系并定期进行深层次反思,从而获得对新鲜事物的见解;
2)AI之间建立了关系并记住了彼此;
3)AI之间学会了相互协调;
4)AI之间学会了共享信息;
5)AI具备了定制和修改计划的能力。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Izfbp33J-1681355548195)(null)]
有兴趣的可以看看演示非常有意思
https://avoid.overfit.cn/post/8d6f2aa6f8eb4d8583ee9f2b4ba1e834
作者:Sergi Castella i Sapé