8个python自动化脚本提高打工人幸福感~比心~
人生苦短,我用Python
最近有许多打工人都找我说打工好难

每天都是执行许多重复的任务,
例如阅读新闻、发邮件、查看天气、打开书签、清理文件夹等等,
使用自动化脚本,就无需手动一次又一次地完成这些任务,
非常方便啊有木有?!
而在某种程度上,Python 就是自动化的代名词。
今天就来和大家一起学习一下,
用8个python自动化脚本提高工作效率~ 快乐摸鱼~
python 安装包+资料:点击此处跳转文末名片获取

1、自动化阅读网页新闻
这个脚本能够实现从网页中抓取文本,然后自动化语音朗读,当你想听新闻的时候,这是个不错的选择。
代码分为两大部分,第一通过爬虫抓取网页文本呢,第二通过阅读工具来朗读文本。
需要的第三方库:
- Beautiful Soup - 经典的HTML/XML文本解析器,用来提取爬下来的网页信息
- requests - 好用到逆天的HTTP工具,用来向网页发送请求获取数据
- Pyttsx3 - 将文本转换为语音,并控制速率、频率和语音
import pyttsx3
import requests
from bs4 import BeautifulSoup
voices = engine.getProperty('voices')
newVoiceRate = 130 ## Reduce The Speech Rate
engine.setProperty('rate',newVoiceRate)
engine.setProperty('voice', voices[1].id)
def speak(audio):
engine.say(audio)
engine.runAndWait()
text = str(input("Paste article\n"))
res = requests.get(text)
# python学习裙:660193417#
articles = []
for i in range(len(soup.select('.p'))):
article = soup.select('.p')[i].getText().strip()
articles.append(article)
text = " ".join(articles)
speak(text)
# engine.save_to_file(text, 'test.mp3') ## If you want to save the speech as a audio file
engine.runAndWait()

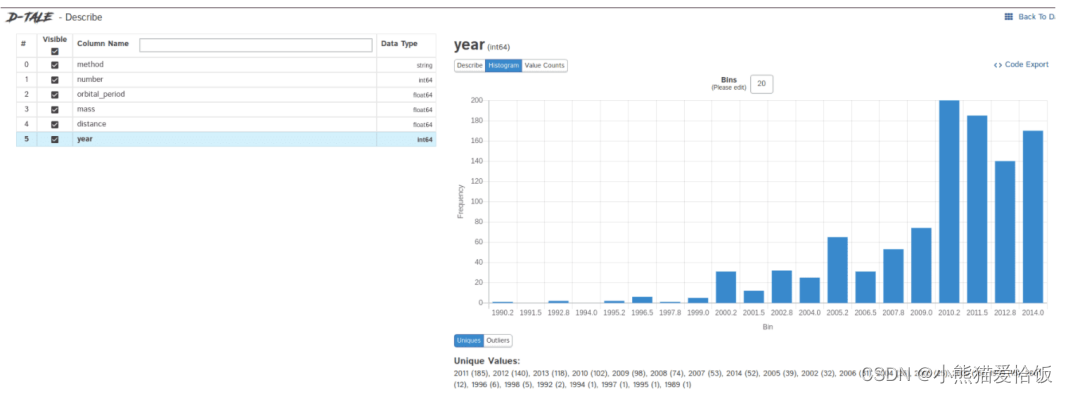
2、自动化数据探索
数据探索是数据科学项目的第一步,你需要了解数据的基本信息才能进一步分析更深的价值。
一般我们会用pandas、matplotlib等工具来探索数据,但需要自己编写大量代码,如果想提高效率,Dtale是个不错的选择。
Dtale特点是用一行代码生成自动化分析报告,它结合了Flask后端和React前端,为我们提供了一种查看和分析Pandas数据结构的简便方法。
我们可以在Jupyter上实用Dtale。
需要的第三方库:
- Dtale - 自动生成分析报告
python 安装包+资料:点击此处跳转文末名片获取
### Importing Seaborn Library For Some Datasets
import seaborn as sns
### Printing Inbuilt Datasets of Seaborn Library
print(sns.get_dataset_names())
### python学习裙:660193417
### Loading Titanic Dataset
df=sns.load_dataset('titanic')
### Importing The Library
import dtale
3、自动发送多封邮件
这个脚本可以帮助我们批量定时发送邮件,邮件内容、附件也可以自定义调整,非常的实用。
相比较邮件客户端,Python脚本的优点在于可以智能、批量、高定制化地部署邮件服务。
需要的第三方库:
- Email - 用于管理电子邮件消息;
- Smtlib - 向SMTP服务器发送电子邮件,它定义了一个 SMTP 客户端会话对象,该对象可将邮件发送到互联网上任何带有 SMTP
或ESMTP 监听程序的计算机; - Pandas - 用于数据分析清洗地工具;
import smtplib
from email.message import EmailMessage
def send_email(remail, rsubject, rcontent):
email = EmailMessage() ## Creating a object for EmailMessage
email['from'] = 'The Pythoneer Here' ## Person who is sending
email['to'] = remail ## Whom we are sending
email['subject'] = rsubject ## Subject of email
email.set_content(rcontent) ## content of email
with smtplib.SMTP(host='smtp.gmail.com',port=587)as smtp:
smtp.ehlo() ## server object
smtp.starttls() ## used to send data between server and client
smtp.login("deltadelta371@gmail.com","delta@371") ## login id and password of gmail
smtp.send_message(email) ## Sending email
print("email send to ",remail) ## Printing success message
if __name__ == '__main__':
df = pd.read_excel('list.xlsx')
length = len(df)+1
for index, item in df.iterrows():
email = item[0]
subject = item[1]
content = item[2]

4、将 PDF 转换为音频文件
脚本可以将 pdf 转换为音频文件,
原理也很简单,
首先用 PyPDF 提取 pdf 中的文本,
然后用 Pyttsx3 将文本转语音。
import pyttsx3,PyPDF2
pdfreader = PyPDF2.PdfFileReader(open('story.pdf','rb'))
speaker = pyttsx3.init()
for page_num in range(pdfreader.numPages):
text = pdfreader.getPage(page_num).extractText() ## extracting text from the PDF
cleaned_text = text.strip().replace('\n',' ') ## Removes unnecessary spaces and break lines
print(cleaned_text) ## Print the text from PDF
#speaker.say(cleaned_text) ## Let The Speaker Speak The Text
speaker.save_to_file(cleaned_text,'story.mp3') ## Saving Text In a audio file 'story.mp3'
speaker.runAndWait()
speaker.stop()

5、从列表中播放随机音乐
这个脚本会从歌曲文件夹中随机选择一首歌进行播放,
需要注意的是 os.startfile 仅支持 Windows 系统。
import random, os
music_dir = 'G:\\new english songs'
songs = os.listdir(music_dir)
song = random.randint(0,len(songs))
print(songs[song]) ## Prints The Song Name
os.startfile(os.path.join(music_dir, songs[0]))

python 安装包+资料:点击此处跳转文末名片获取
6、智能天气信息
国家气象局网站提供获取天气预报的 API,直接返回 json 格式的天气数据。所以只需要从 json 里取出对应的字段就可以了。
下面是指定城市(县、区)天气的网址,直接打开网址,就会返回对应城市的天气数据。比如:
http://www.weather.com.cn/data/cityinfo/101021200.html 上海徐汇区对应的天气网址。
具体代码如下:
mport requests
import json
import logging as log
def get_weather_wind(url):
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
info = json.loads(r.content.decode())
# get wind data
data = info['weatherinfo']
WD = data['WD']
WS = data['WS']
return "{}({})".format(WD, WS)
def get_weather_city(url):
# open url and get return data
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
# convert string to json
info = json.loads(r.content.decode())
# get useful data
data = info['weatherinfo']
city = data['city']
temp1 = data['temp1']
temp2 = data['temp2']
weather = data['weather']
return "{} {} {}~{}".format(city, weather, temp1, temp2)
if __name__ == '__main__':
msg = """**天气提醒**:
{} {}
{} {}
来源: 国家气象局
""".format(
get_weather_city('http://www.weather.com.cn/data/cityinfo/101021200.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101021200.html'),
get_weather_city('http://www.weather.com.cn/data/cityinfo/101020900.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101020900.html')
)
print(msg)
运行结果如下所示:

7、长网址变短网址
有时,那些大URL变得非常恼火,
很难阅读和共享,此脚本可以将长网址变为短网址。
import contextlib
from urllib.parse import urlencode
from urllib.request import urlopen
import sys
def make_tiny(url):
request_url = ('http://tinyurl.com/api-create.php?' +
urlencode({'url':url}))
with contextlib.closing(urlopen(request_url)) as response:
return response.read().decode('utf-8')
def main():
for tinyurl in map(make_tiny, sys.argv[1:]):
print(tinyurl)
if __name__ == '__main__':
main()
这个脚本非常实用,
比如说有内容平台是屏蔽公众号文章的,
那么就可以把公众号文章的链接变为短链接,
然后插入其中,就可以实现绕过。

python 安装包+资料:点击此处跳转文末名片获取
8、清理下载文件夹
世界上最混乱的事情之一是开发人员的下载文件夹,
里面存放了很多杂乱无章的文件,
此脚本将根据大小限制来清理您的下载文件夹,
有限清理比较旧的文件。
import os
import threading
import time
def get_file_list(file_path):
#python交流:903971231#
dir_list = os.listdir(file_path)
if not dir_list:
return
else:
dir_list = sorted(dir_list, key=lambda x: os.path.getmtime(os.path.join(file_path, x)))
return dir_list
def get_size(file_path):
"""[summary]
Args:
file_path ([type]): [目录]
Returns:
[type]: 返回目录大小,MB
"""
totalsize=0
for filename in os.listdir(file_path):
totalsize=totalsize+os.path.getsize(os.path.join(file_path, filename))
#print(totalsize / 1024 / 1024)
return totalsize / 1024 / 1024
def detect_file_size(file_path, size_Max, size_Del):
"""[summary]
Args:
file_path ([type]): [文件目录]
size_Max ([type]): [文件夹最大大小]
size_Del ([type]): [超过size_Max时要删除的大小]
"""
print(get_size(file_path))
if get_size(file_path) > size_Max:
fileList = get_file_list(file_path)
for i in range(len(fileList)):
if get_size(file_path) > (size_Max - size_Del):
print ("del :%d %s" % (i + 1, fileList[i]))
#os.remove(file_path + fileList[i])
