Java实习生------Redis常见面试题汇总(AOF持久化、RDB快照、分布式锁、缓存一致性)⭐⭐⭐
“年轻人,就要勇敢追梦”🌹
参考资料:图解redis
目录
谈谈你对AOF持久化的理解?
redis的三种写回策略是什么?
谈谈你对AOF重写机制的理解?AOF重写机制的具体过程?
谈谈你对RDB快照的理解?怎么触发RDB?
redis大key对持久化有什么影响?
如何用redis实现分布式锁?基于 Redis 实现分布式锁的优点与缺点?
数据库和缓存如何保持一致性?
谈谈你对AOF持久化的理解?
- Redis每执行一次写操作命令,就会以追加的方式写入到一个文件里,这个文件就叫做AOF日志,当redis重启时,再去执行这个文件中的命令,就相当于做了数据恢复。将写操作命令写入到日志文件的过程就是redis的AOF持久化过程。
值得注意的是,redis只会记录写操作,读操作不会记录;另外,redis是先执行完写操作命令,再将这个命令记录到日志中,这么做有两点好处:
- 避免了额外的检查开销,如果命令是错误的,那么在执行的时候就可以检查出来了,不会往日志中记录一条错误命令
- 不会阻塞当前命令的执行
但是也有两点坏处:
- 如果redis在执行这条写命令的时候,redis发生故障宕机,也就是还没来得及将这条命令写入到日志中,所以就会造成数据丢失
- 可能会阻塞下一条命令的执行
redis的三种写回策略是什么?
AOF日志中的命令还并没有被同步到硬盘,此时这些命令还存在于server.aof_buf缓冲区中
AOF具体有三种写回策略:
- always:命令写入aof_buf之后就立即调用fsync函数,将AOF数据同步到硬盘。可靠性高,最大程度保证数据不会丢失,但是性能开销比较大
- no:命令写入aof_buf之后先将命令写入到AOF文件的内核缓冲区,不对AOF文件做fsync同步,同步硬盘操作由操作系统负责。性能好,但是如果宕机会丢失很多数据
- everysec:命令写入aof_buf之后,先将命令写入到AOF文件的内核缓冲区,然后每隔一秒调用一次fsync函数,将内核缓冲区中的数据同步到硬盘。性能适中,redis宕机会丢失一秒内的数据
谈谈你对AOF重写机制的理解?AOF重写机制的具体过程?
随着执行命令的增多,AOF文件中的命令也越来越多,AOF文件的体积也会越来越大,AOF重写机制的目的就是为了压缩AOF文件的体积。
AOF重写机制的妙处就在于,它会读取数据库中的最新数据,然后仅用一条命令来记录这条数据;也就是说,如果在之前,这条记录被多次修改过,也就意味着有多条修改命令,那么只需要记录最后一条修改不就行了吗?这样就减少了命令的数量,AOF重写机制会把这些最新的命令写入到一个新的AOF文件中,然后覆盖掉原有的AOF文件。
因为AOF重写过程比较耗时,所以一般不会在主进程中执行
开启AOF重写机制之后,主进程会fork出一个子进程,由子进程来执行AOF重写。
这样做的好处有两点:
- 重写过程由子进程来执行,主进程依旧可以相应客户端命令
- 主进程和子进程共用一份页表,即主进程和子进程共用一块物理内存
缺点:
- 主进程在fork子进程的时候,由于要复制一份页表给子进程,所以会造成主进程阻塞
- 另外,当主进程或者子进程修改共享数据时,会发生写时复制,内核会将物理内存再拷贝一份,也会造成主进程的阻塞
谈谈你对RDB快照的理解?怎么触发RDB?
RDB快照记录了某一瞬间内存中的数据,所以RDB文件记录的是实际的数据,而AOF日志记录的是一条条命令。使用RDB来进行数据恢复的效率要高于AOF,所以RDB是redis的默认持久化方式。
触发机制:两条命令,save和bgsave
- save:阻塞当前redis服务器,直到RDB过程结束
- bgsave:主进程fork出一个子进程,阻塞只发生在fork阶段,一般时间很短
redis大key对持久化有什么影响?
大key对AOF日志的影响:
- 使用always策略:主线程在执行fsync函数时,阻塞的时间比较久
- 使用no策略:由于永远不会执行fsync函数,所以不会影响主线程
- 使用everysec策略:由于是异步执行fsync函数,所以大key持久化的过程不会影响主线程
大key对AOF重写和RDB的影响:
- 创建子进程的过程中父进程会发生阻塞,因为子进程要复制父进程的页表等数据结构
- 创建完子进程之后父进程也会发生阻塞,如果父进程对大key做了修改,那么内核就会发生写时复制,会把物理内存复制一份,由于大key占用的物理内存比较大,那么在复制物理内存的时候就会很耗时,就会阻塞父进程
如何用redis实现分布式锁?基于 Redis 实现分布式锁的优点与缺点?
分布式锁主要应用于并发环境下,保证某个资源在同一时刻只能被某一个用户所使用
使用 redis 中的 SET NX命令实现分布式锁
SET lock_key unique_value NX PX 10000 在设置锁的时候,需要满足两个条件:
- 需要对锁设置过期时间,避免锁被获取之后发生异常,导致客户端无法释放锁
- 锁变量的值需要能够区分出不同的用户
优点:
- 性能高效、实现方便(使用SET NX命令)
缺点:
- 超时时间不好设置:如果设置的时间太长,那么会影响性能;如果设置的时间太短,起不到互斥的作用
- 可能存在不可靠性:redis基于集群分布的,且主从复制的过程是异步的,可能在redis主节点获取到锁之后,主节点宕机,还没来得及同步,所以在新的redis主节点上依旧可以重新获取锁
数据库和缓存如何保持一致性?
如果先更新数据库,再更新缓存:
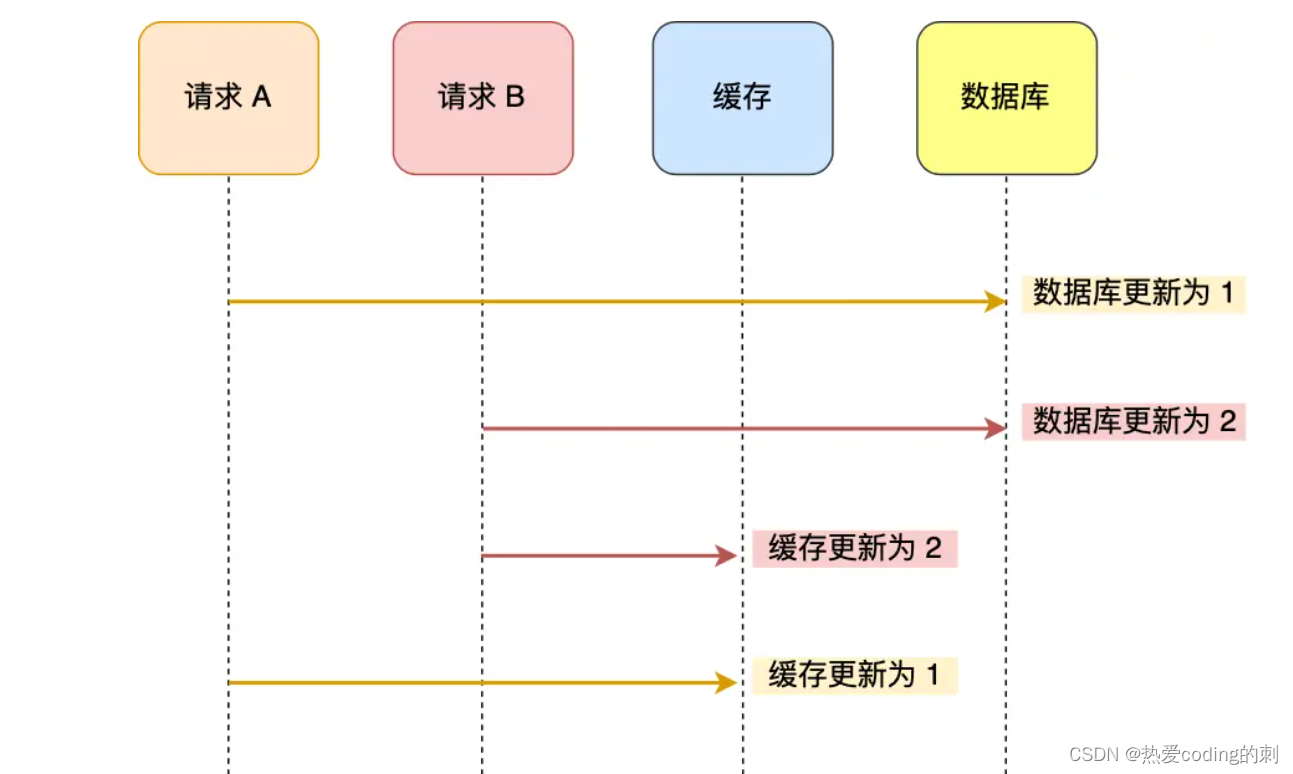
此时,数据库中的值是2,而缓存中的值是1,出现了数据库和缓存中的数据不一致的现象!
如果先更新缓存,再更新数据库:
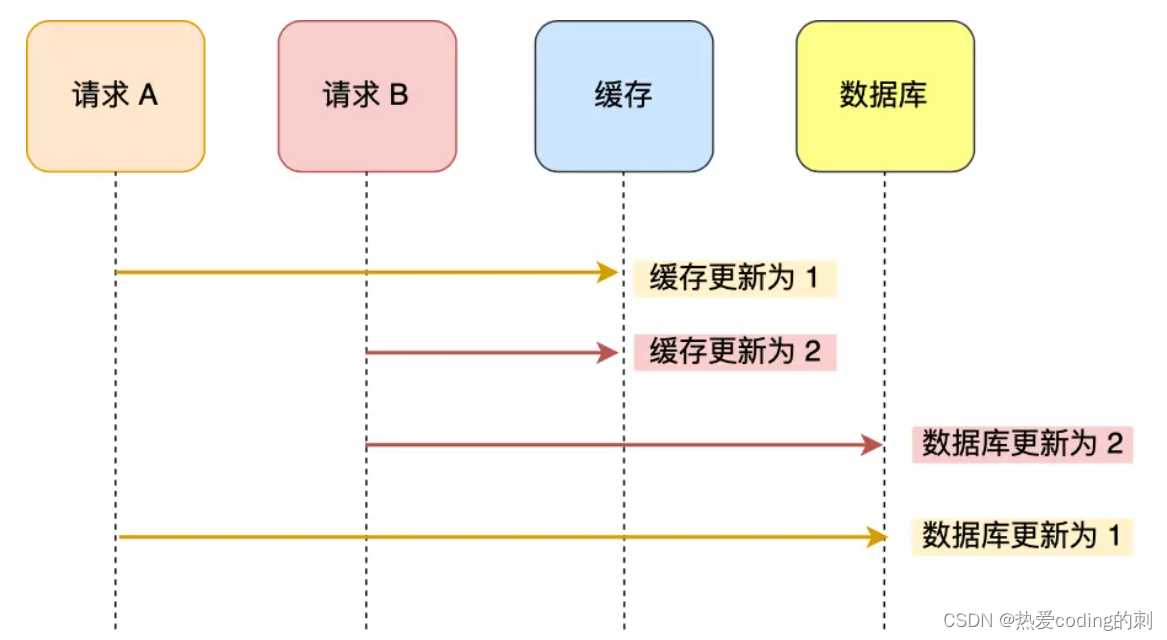
此时,缓存中的值是2,数据库中的值是1,依旧出现了数据库和缓存中的数据不一致的现象!
如果先删除缓存,再更新数据库:
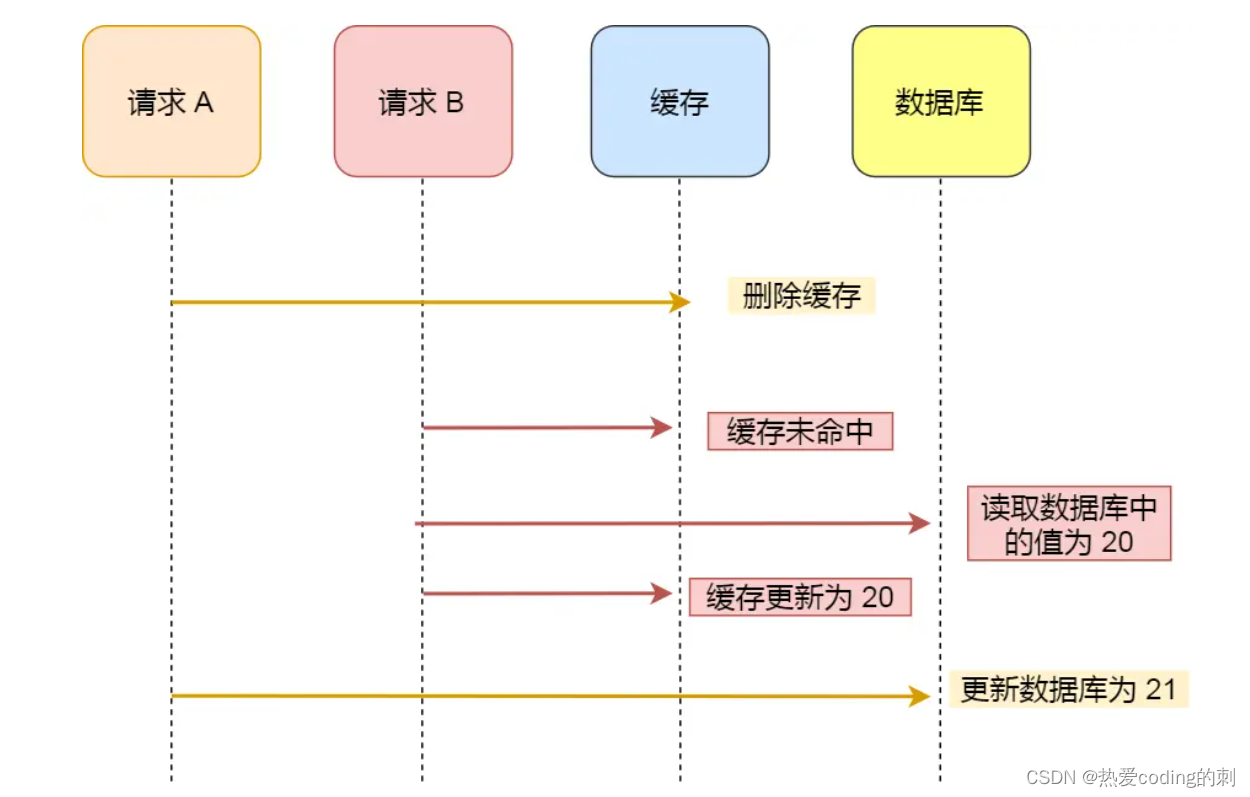 这种情况下,读请求和写请求并发的情况下,出现了数据库和缓存中的数据不一致的问题!
这种情况下,读请求和写请求并发的情况下,出现了数据库和缓存中的数据不一致的问题!
如果先更新数据库,再删除缓存:
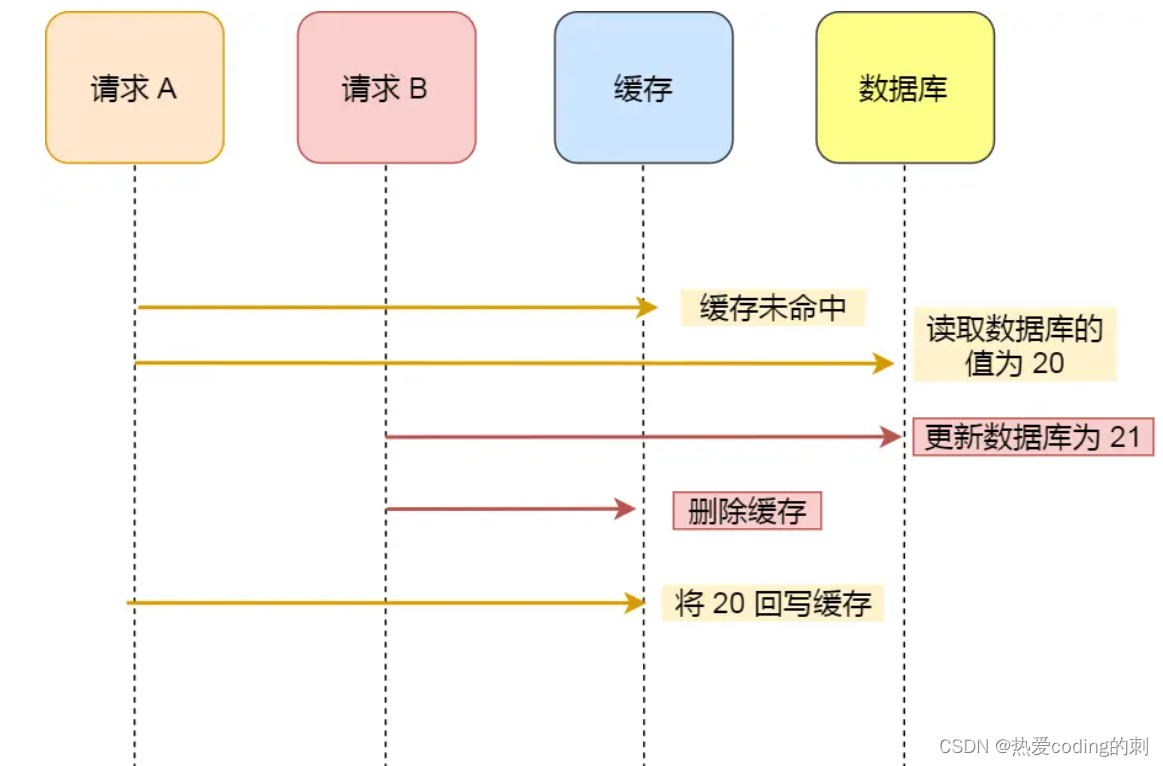 如果但从理论上分析,上述情况依旧导致了数据不一致的问题,但是,值得注意的是,在实际中,这种情况出现的概率并不高,因为写缓存的速度要快于写数据库的速度
如果但从理论上分析,上述情况依旧导致了数据不一致的问题,但是,值得注意的是,在实际中,这种情况出现的概率并不高,因为写缓存的速度要快于写数据库的速度
所以,先更新数据库,再删除缓存这种方案是可行的。
但是,继续分析,更新数据库和删除缓存,这是两种操作,如果更新数据库成功了,但是删除缓存的时候失败了,那么缓存中缓存的就是旧值,数据库中存放的是新值。怎么保证这两个操作都能顺利执行呢?
解决方案有两种:
重试机制:将要操作的数据加入到消息队列,如果删除缓存失败,那么就重新读取消息,重新执行删除缓存操作;如果删除缓存成功了,就将消息从消息队列中移除。
订阅MySQL binlog:在更新数据库时,会产生一条bin log日志,如果删除缓存失败,就从bin log中拿到具体操作的数据,进行重新删除

整理面经不易,觉得有帮助的小伙伴点个赞吧~感谢收看!