字典树(前缀树)
字典树-前缀树
- 树家族
- Trie树
- 前缀树和哈希表比较
- 代码实现
- 应用场景
- 参考
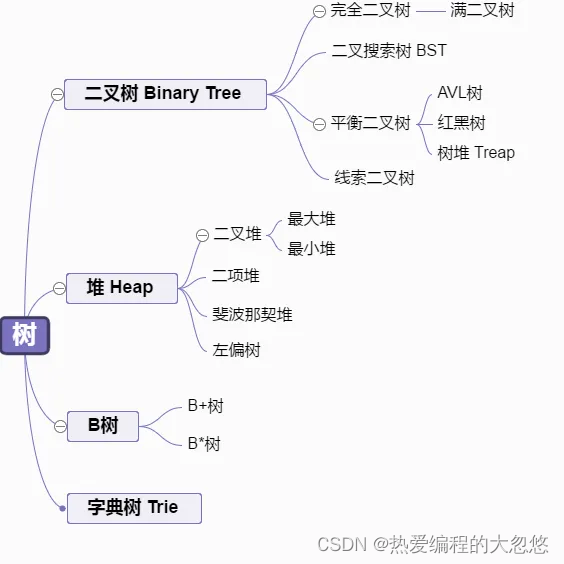
树家族
树的家族如下图所示:
堆是具有下列性质的完全二叉树:每个节点的值都小于等于其左右孩子节点值是小根堆;(大于等于则是大根堆)。
有些参考书将堆直接定义为序列,但是,从逻辑结构上讲,还是将堆定义为完全二叉树更好。虽然堆的典型实现方法是数组,但从逻辑的角度上讲,堆实际上是一种树结构。
Trie树
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种,典型应用是用于统计和排序大量相同的字符串,所以经常被搜索引擎系统用于文本词频统计。它的优点是: 利用字符串的公共前缀来减少查询时间,最大限度地减少无谓字符串的比较。
Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
前缀树的三个基本性质:
- 根节点不包含字符,除根节点外每个节点都只包含一个字符
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同
前缀树和哈希表比较
查询复杂度:
- 字典树的查询时间复杂度为O(L),L是字符串长度。
- hash的查询复杂度为O(1),但是在数据量很大的情况下,哈希冲突一多,会导致查询效率降低。
单词查询场景:
- 哈希不支持动态查询,如果我们要查询单词apple,hash表必须等待用户把单词apple输入完毕才能进行hash查询
- 字典树支持动态查询,比如用户输入到appl时,字典树此刻的查询位置就可以到达l这个位置,那么我在输入e时,光查询e即可,字典树无需等待字符串全部输入完毕才能进行查询
代码实现
- 字典树中的字符是小写字母,那么每个节点放大小为 26 的数组即可,每个字符指向一个子节点,就是 26 叉树。
208. 实现 Trie (前缀树)
class Trie {
//根节点
private Node root;
public Trie() {
root=new Node(false);
}
public void insert(String word) {
Node cur=root;
char[] charArray=word.toCharArray();
for(char c:charArray){
int index=c-'a';
if(cur.childern[index]==null){
cur.childern[index]=new Node(false);
}
cur=cur.childern[index];
}
cur.isEnd=true;
}
public boolean search(String word) {
Node res=doSearch(word);
return res!=null && res.isEnd;
}
public boolean startsWith(String prefix) {
return doSearch(prefix)!=null;
}
public Node doSearch(String str){
Node cur=root;
char[] charArray=str.toCharArray();
for(char c:charArray){
int index=c-'a';
if(cur.childern[index]==null){
return null;
}
cur=cur.childern[index];
}
return cur;
}
public static class Node{
//结束标记
private boolean isEnd;
//孩子节点
private Node[] childern;
public Node(boolean end){
childern=new Node[26];
isEnd=end;
}
}
}
- 字典树中存放多种多样的字符,这时可以用哈希表来组织。也有可能非常简单,比如数字异或前缀,就只有 0 和 1 两种可能,就是一个二叉树
class Trie {
//根节点
private Node root;
public Trie() {
root=new Node(false);
}
public void insert(String word) {
Node cur=root;
char[] charArray=word.toCharArray();
for(char c:charArray){
if(!cur.childern.containsKey(c)){
cur.childern.put(c,new Node(false));
}
cur=cur.childern.get(c);
}
cur.isEnd=true;
}
public boolean search(String word) {
Node res=doSearch(word);
return res!=null && res.isEnd;
}
public boolean startsWith(String prefix) {
return doSearch(prefix)!=null;
}
public Node doSearch(String str){
Node cur=root;
char[] charArray=str.toCharArray();
for(char c:charArray){
if(!cur.childern.containsKey(c)){
return null;
}
cur=cur.childern.get(c);
}
return cur;
}
public static class Node{
//结束标记
private boolean isEnd;
//孩子节点
private Map<Character,Node> childern;
public Node(boolean end){
childern=new HashMap<>();
isEnd=end;
}
}
}
应用场景
- 敏感词匹配,词库底层采用的数据结构可以考虑使用字典树
- 如何从大量的 URL 中找出相同的 URL?
参考
字典树刷题总结