消息中间件:Puslar、Kafka、RabbigMQ、ActiveMQ
消息队列
消息队列:它主要用来暂存生产者生产的消息,供后续其他消费者来消费。
它的功能主要有两个:
- 暂存(存储)
- 队列(有序:先进先出
从目前互联网应用中使用消息队列的场景来看,主要有以下三个:
- 异步处理数据
- 系统应用解耦
- 业务流量削峰
消息队列模型
点对点模式
-
多个生产者可以向同一个消息队列发送消息,一个消息只能被一个消费者消费,在被消费成功后,这条消息会被移除。如果消费者处理消息失败了,那么这条消息会重新被消费。
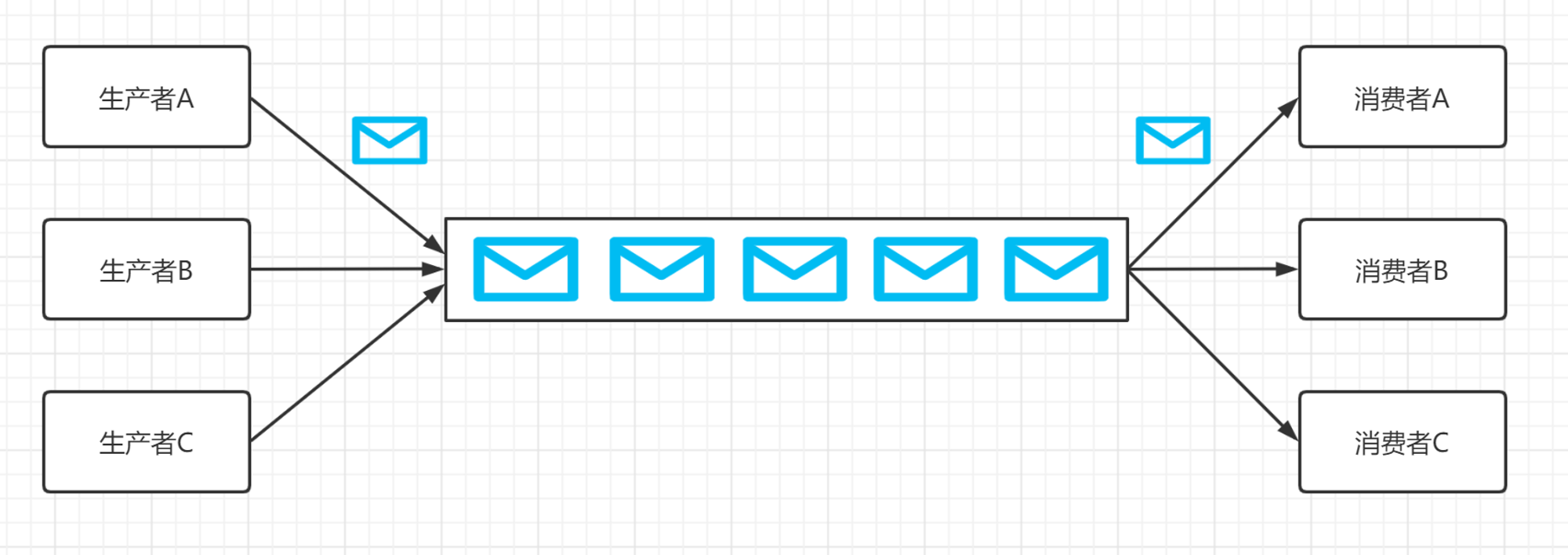
发布/订阅模式:
-
单个消息可以被多个订阅者并发的获取和处理。多个生产者可以将多个消息写到同一个 Topic 中,被同一个消费者消费。

消息队列对比

ActiveMQ:ActiveMQ 由 Apache 软件基金会基于 Java 语言开发的一个开源的消息代理。能够支持多个客户机或服务器。计算机集群等属性支持 ActiveMQ 来管理通信系统。
RabbitMQ:RabbitMQ 是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ 服务器是用 Erlang 语言编写的,而集群和故障转移是构建在开放电信平台框架上的。
所有主要的编程语言均有与代理接口通讯的客户端库。RabbitMQ 支持多种消息传递协议、传递确认等特性。
Kafka:Apache Kafka 是由 Apache 软件基金会开发的一个开源消息系统项目,由 Scala 写成。
Kafka 最初是由 LinkedIn 开发,并于 2011 年初开源。2012 年 10 月从 Apache Incubator 毕业。
该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。Kafka 是一个分布式的、分区的、多复本的日志提交服务。它通过一种独一无二的设计提供了一个消息系统的功能。
RocketMQ:Apache RocketMQ 是一个分布式消息和流媒体平台,具有低延迟、强一致、高性能和可靠性、万亿级容量和灵活的可扩展性。它有借鉴 Kafka 的设计思想,但不是 Kafka 的拷贝。
Pulsar:Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计。
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka | Pulsar |
|---|---|---|---|---|---|
| 推出时间 | 2003 | 2007 | 2012 | 2010 | 2016 |
| 所属公司 | Mozilla public License | Apache | Apache | Yahoo/Apache/顶级 | |
| 特点 | erlang语言发开,性能一般,出现比较早,有一定的用户基数 | 各个环节分布式扩展设计,主从HA,多种消费模式,性能很 好 | 高吞吐量、持久化数据存储、分布式系统易于扩展,性能极好 | 灵活、多租户、云原生架构、跨地域复制,性能超极好 | |
| 单机吞吐量 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 10万级,RocketMQ 也是可以支撑高吞吐的 MQ | 10万级别,吞吐量高是kafka最大的优点 | 100万+,高吞吐,支持强一致 |
| 支持主题数 | 千级 | 百万级 | 千级,topic 达到千级时吞吐量会有较小幅度的下降。可以支撑大量 topic 是 RocketMQ 的一大优点 | 不限制,topic 达到百级时吞吐量会大幅度下降,要尽量保证 topic 数量不要过多,否则需要增加更多机器资源 | Pulsar采用存算分离的架构,数据采用bookeeper存储,上层broker是无状态代理,两层可以对扩容,因此topic个数对吞吐量不会产生显著的影响。可无缝扩展到超过百万个 topic |
| 事务 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 消息顺序性 | 有序 | 有序 | 有序 | 分区有序 | 有序 |
| 消息重复 | 至少一次 | 至少一次 | 至少一次,最多一次 | 至少一次,最多一次 | |
| 时效性 | ms级 | 微秒级,RabbitMQ的一大优点 | ms级 | ms级 | ms级 |
| 可用性 | 高,基于主从架构实现 | 高,基于主从架构实现 | 非常高,分布式架构 | 非常高,分布式架构,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 | 非常高,分布式架构,broker层是无状态代理,动态扩容,数据存储层bookkeeper采用segment-oriented存储机制,无写入不可用风向 |
| 消息可靠性 | 有较低的概率丢失数据 | 有较低的概率丢失数据 | 经过参数优化配置,消息可以做到0丢失。消息都是持久化的,先写入系统 PAGECACHE,然后刷盘,可以保证内存与磁盘都有一份数据; | 经过参数优化配置,理论上消息可以做到0丢失 | 经过参数配置后,可以做到0丢失 |
| 消息回溯 | 不支持 | 不支持 | 支持(按时间回溯) | 支持(按offset回溯) | |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 | 云原生时代的新一代消息中间件,社区活跃、支持多租户、强一致、跨域部署等诸多特性 |
| 伸缩性 | 一般 | 高伸缩性,灵活的分布式横向扩展部署架构,整体架构和 kafka 很像 | 高伸缩性,每个主题(topic)包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中 | Pulsar 采用了 BookKeeper,因此伸缩性更灵活 | |
| 管理界面 | 普通 | 普通 | 完善 | 普通 | 完善 |
| 持久化 | 可以持久化到内存、文件、数据库 | 持久化不好,可以持久化到内存、文件 | 消息可以持久化到磁盘 | 磁盘 | 磁盘 |
| 消息路由 | 支持 | 不支持 | 不支持 | 支持 | |
| 语言支持 | 支持多语言,Java优先 | 支持几乎所有最受欢迎的编程语言:Java,C,C ++,C#,Ruby,Perl,Python,PHP等 | 支持Java、C++,但C++不成熟 | 支持多语言,Java优先 | Java、C、C++ 、Python、Go、.NET、Node |
| 社区活跃度 | 高 | 高 | 一般 | 高 | 高 |
| 消息的存活时间 | 不支持 | 支持消息TTL |
Pulsar 架构
Pulsar 由 Producer、Consumer、多个 Broker 、一个 BookKeeper 集群、一个 Zookeeper 集群构成,具体如下图所示。

Pulsar 的多层架构影响了存储数据的方式。Pulsar 将 topic 分区划分为分片(segment),然后将这些分片存储在 Apache BookKeeper 的存储节点上,以提高性能、可伸缩性和可用性。

跟Kafka不同的是,Pulsar的消息存储模型采用了分层的方式。

第一层是Topic,用来存储Producer追加的messages,Topic下面是ledger层,保存了分片(Segment),分片里面保存更小粒度的ertries,entries存储一条条的Message。
Bookkeeper中,数据的最小操作单位是Segment。
Ledger中的最后一个分片是最新写入的分片,如上图Segment-2。Segment-2之前的所有分片已完成封装,这些分片的数据是不会再发生变化的。这样增加或删除一个BookKeeper节点,或者迁移长期存储节点,都不会发生一致性问题。
Apache Pulsar 支持四种不同订阅模式
单个应用程序的订阅模式由排序和消费可扩展性需求决定。以下为这四种订阅模式及相关的排序保证。
- 独占(Exclusive)同一个topic只能有一个消费者订阅,如果多个消费者订阅,就会出错。Exclusive模式为默认订阅模式。
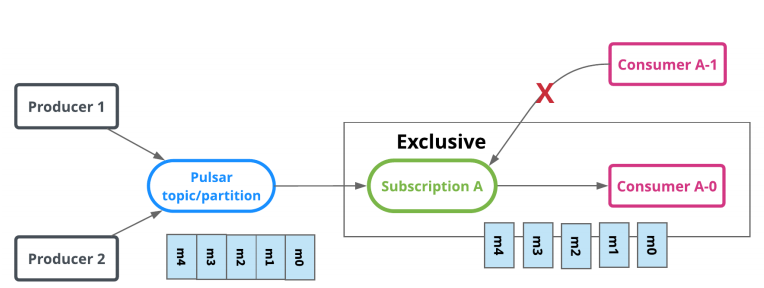
- 灾备(Failover)订阅模式都在分区级别支持强序列保证,支持跨 consumer 并行消费同一 topic 上的消息。同一个topic可以有多个消费者订阅,但是只能有一个消费者消费,其他订阅 的消费者作为故障转移的消费者,只有当前消费者出了故障才可以进行消费当前的topic。如下图:

- 共享(Shared)订阅模式支持将 consumer 的数量扩展至超过分区的数量,因此这种模式非常适合 worker 队列应用场景。同一个topic可以由多个消费者订阅和消费。消息通过round robin轮询机制分发给不同的消费者,并且每个消息仅会被分发给一个消费者。当消费者断开,发送给它的没有被消费的消息还会被重新分发给其它存活的消费者。如下图:

- 键共享(Key_Shared)订阅模式结合了其他订阅模式的优点,支持将 consumer 的数量扩展至超过分区的数量,也支持键级别的强序列保证。消息和消费者都会绑定一个key,消息只会发送给绑定同一个key的消费者。如果有新消费者建立连接或者有消费者断开连接,就需要更新一些消息的key。

Kafka 架构
参考:360度无死角 | Pulsar与Kafka对比全解析-腾讯云开发者社区-腾讯云
Kafka 机器数量(经验公式)=2*(峰值生产速度副本数/100)+1
峰值速度:比如flume读取日志文件往kafka里写数据的峰值速度,得问公司上游业务团队获得
副本数:topic的副本数,一般是2个(3个)
Topic数量本身无限制,但Topic的分区数之和有上限,当达到上限后,会导致用户无法继续创建Topic。
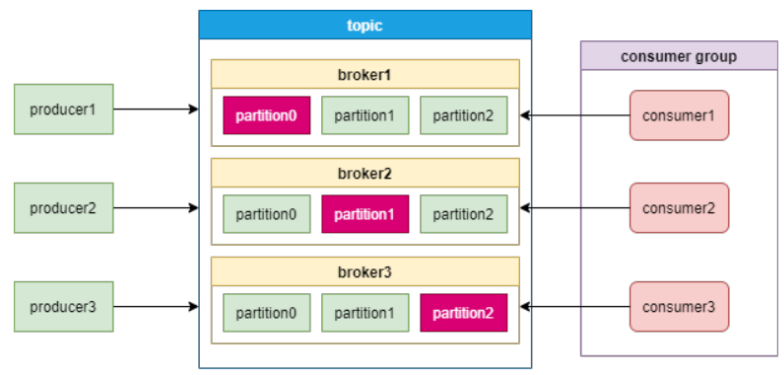
Kafka架构由broker和zookeeper组成,如下图:

Broker Leader
Kafka采用分区(Partition)的方式来保存topic,每个topic都会在不同的broker保存多个分区副本,其中只有一个副本的分区是leader分区,供消费者使用。若干个broker作为follower。所有的数据读写都通过leader所在的服务器进行,并且leader在不同broker之间复制数据。如果某个broker宕机了,这个broker上的leader分区失效,需要在其他broker上重新进行选举。模型图如下:

Kafka的消费模型是采用消费者组的模式,每一个分区只能给消费者组中的一个消费者消费。Leader Broker 1再将数据复制到follower Broker 2和Broker 3。如下图: