政安晨:示例演绎TensorFlow的官方指南(三){快速使用数据可视化工具TensorBoard}
这篇文章里咱们演绎TensorFLow的数据可视化工具:TensorBoard。
在机器学习中,要改进模型的某些参数,您通常需要对其进行衡量。TensorBoard 是用于提供机器学习工作流期间所需测量和呈现的工具。它使您能够跟踪实验指标(例如损失和准确率),呈现模型计算图,将嵌入向量投影到较低维度的空间等。

准备环境
咱们基于本地环境尝试使用tensorboard(本地环境演绎,更有助于熟悉这套工具),不熟悉如何搭建tensorflow本地环境的小伙伴可以参考我的这篇文章:
政安晨的机器学习笔记——跟着演练快速理解TensorFlow(适合新手入门)![]() https://blog.csdn.net/snowdenkeke/article/details/135950931准备好环境之后,打开Jupyter Notebook,咱们就开始啦。
https://blog.csdn.net/snowdenkeke/article/details/135950931准备好环境之后,打开Jupyter Notebook,咱们就开始啦。
我使用了已经安装好TensorFlow的虚拟环境:

开始使用
# 加载TensorBoard笔记本扩展
%load_ext tensorboard在笔记本(Jupyter Notebook)中执行上述语句,如果在CMD中就不要加%。
import tensorflow as tf
import datetime咱们在本例中依然还是使用 MNIST数据集(这个数据集已经被使用了无数次啦,经常用于各种DEMO演示)。
接下来编写一个函数对数据进行标准化,同时创建一个简单的Keras模型使图像分为10类。
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28), name='layers_flatten'),
tf.keras.layers.Dense(512, activation='relu', name='layers_dense'),
tf.keras.layers.Dropout(0.2, name='layers_dropout'),
tf.keras.layers.Dense(10, activation='softmax', name='layers_dense_2')
])通过 Keras Model.fit() 使用 TensorBoard
当使用 Keras's Model.fit() 函数进行训练时, 添加 tf.keras.callback.TensorBoard 回调可确保创建和存储日志.另外,在每个时期启用 histogram_freq=1 的直方图计算功能(默认情况下处于关闭状态)
将日志放在带有时间戳的子目录中,以便轻松选择不同的训练运行。
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])执行如下:

通过命令行 (command) 或在 notebook 体验中启动 TensorBoard ,这两个接口通常是相同的。 在 notebooks, 使用 %tensorboard 命令。 在命令行中, 运行不带“%”的相同命令。
%tensorboard --logdir logs/fit启动像这样:
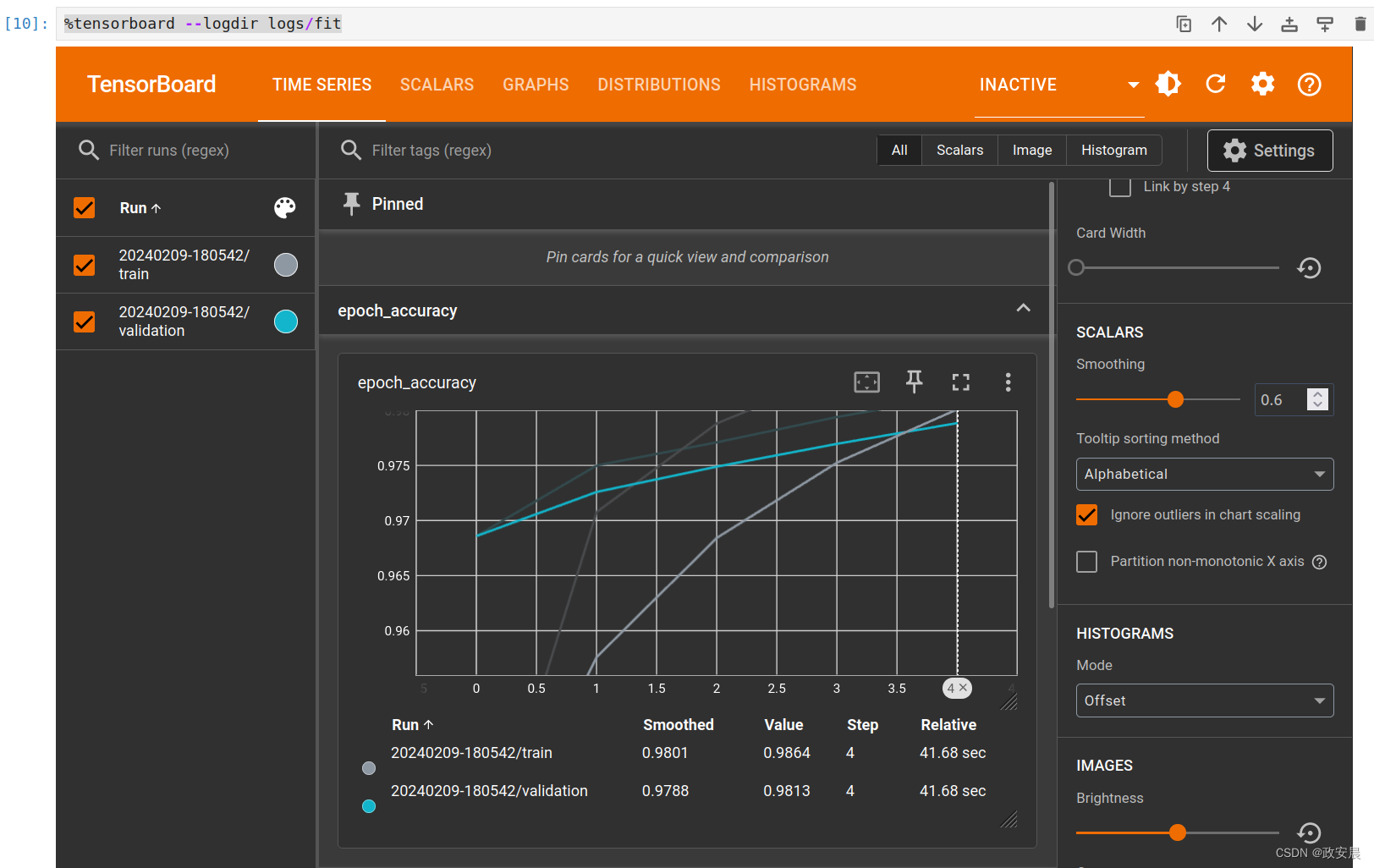
在此示例中创建的可视化效果的简要概述以及可以找到它们的信息中心
(顶部导航栏中的标签页):
- 标量显示损失和指标在每个周期如何变化。您还可以使用它们跟踪训练速度、学习率和其他标量值。可以在 Time Series 或 Scalars 信息中心找到标量。
- 计算图可以帮助您呈现模型。在这种情况下,将显示层的 Keras 计算图,这可以帮助您确保正确构建。可以在 Graphs 信息中心找到计算图。
- 直方图和分布显示张量随时间的分布。这对于呈现权重和偏差并验证它们是否以预期的方式变化很有用。可以在 Time Series 或 Histograms 信息中心中找到直方图。可以在 Distributions 信息中心中找到分布。
当您记录其他类型的数据时,会自动启用其他 TensorBoard 信息中心。 例如,使用 Keras TensorBoard 回调还可以记录图像和嵌入向量。您可以通过点击右上角的“inactive”下拉列表来查看 TensorBoard 中还有哪些其他信息中心。
通过其他方法使用 TensorBoard
用以下方法训练时,例如 tf.GradientTape(), 会使用 tf.summary 记录所需的信息。
使用与上述相同的数据集,但将其转换为 tf.data.Dataset 以利用批处理功能:
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)训练代码遵循 advanced quickstart 教程,但显示了如何将 log 记录到 TensorBoard 。 首先选择损失和优化器:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()创建可用于在训练期间累积值并在任何时候记录的有状态指标:
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')定义训练和测试代码:
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)设置摘要编写器,以将摘要写到另一个日志目录中的磁盘上:
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)开始训练。使用 tf.summary.scalar() 在摘要编写器范围内的训练/测试期间记录指标(损失和准确率)以将摘要写入磁盘。您可以控制记录哪些指标以及记录的频率。其他 tf.summary 函数可以记录其他类型的数据。
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()再次打开 TensorBoard,这次将其指向新的日志目录。 我们也可以启动 TensorBoard 来监视训练进度。
%tensorboard --logdir logs/gradient_tape您现在已经了解了如何通过 Keras 回调和通过 tf.summary 使用 TensorBoard 来实现更多自定义场景。
TensorBoard.dev:托管并共享您的机器学习实验结果
TensorBoard.dev 是一项免费的公共服务,可让您上传您的 TensorBoard 日志并获得可在学术论文、博文、社交媒体等中与所有人共享的永久链接。这有助于实现更好的重现性和协作。
要使用 TensorBoard.dev,请运行以下命令:
!tensorboard dev upload \
--logdir logs/fit \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters" \
--one_shot请注意,此调用使用感叹号前缀 (!) 来调用 shell,而不是使用百分比前缀 (%) 来调用 colab 魔法。从命令行调用此命令时,不需要任何前缀。