EMNLP 2023精选:Text-to-SQL任务的前沿进展(下篇)——Findings论文解读
导语
本文记录了今年的自然语言处理国际顶级会议EMNLP 2023中接收的所有与Text-to-SQL相关(通过搜索标题关键词查找得到,可能不全)的论文,共计12篇,包含5篇正会论文和7篇Findings论文,以下是对这些论文的略读,某几篇也有详细的笔记(见链接)。
由于篇数过多,分为两篇博客记录,本篇为第二篇,主要记录Findings论文:
| 序号 | 类型 | 标题 |
|---|---|---|
| 1 | Main | Benchmarking and Improving Text-to-SQL Generation under Ambiguity |
| 2 | Main | Evaluating Cross-Domain Text-to-SQL Models and Benchmarks |
| 3 | Main | Exploring Chain of Thought Style Prompting for Text-to-SQL |
| 4 | Main | Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations |
| 5 | Main | Non-Programmers Can Label Programs Indirectly via Active Examples: A Case Study with Text-to-SQL |
| 6 | Findings | Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison |
| 7 | Findings | Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies |
| 8 | Findings | Error Detection for Text-to-SQL Semantic Parsing |
| 9 | Findings | ReFSQL: A Retrieval-Augmentation Framework for Text-to-SQL Generation |
| 10 | Findings | Selective Demonstrations for Cross-domain Text-to-SQL |
| 11 | Findings | Semantic Decomposition of Question and SQL for Text-to-SQL Parsing |
| 12 | Findings | SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data |
Findings
Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison
- 链接:https://arxiv.org/abs/2310.10190
- 摘要:ChatGPT的成功引发了一场AI竞赛,研究人员致力于开发新的大型语言模型(LLMs),以匹敌或超越商业模型的语言理解和生成能力。近期,许多声称其性能接近GPT-3.5或GPT-4的模型通过各种指令调优方法出现了。作为文本到SQL解析的从业者,我们感谢他们对开源研究的宝贵贡献。然而,重要的是要带着审查意识去看待这些声明,并确定这些模型的实际有效性。因此,我们将六个流行的大型语言模型相互对比,系统评估它们在九个基准数据集上的文本到SQL解析能力,涵盖了五种不同的提示策略,包括零样本和少样本场景。遗憾的是,开源模型的性能远远低于像GPT-3.5这样的封闭源模型所取得的成绩,这凸显了进一步工作的需要,以弥合这些模型之间的性能差距。
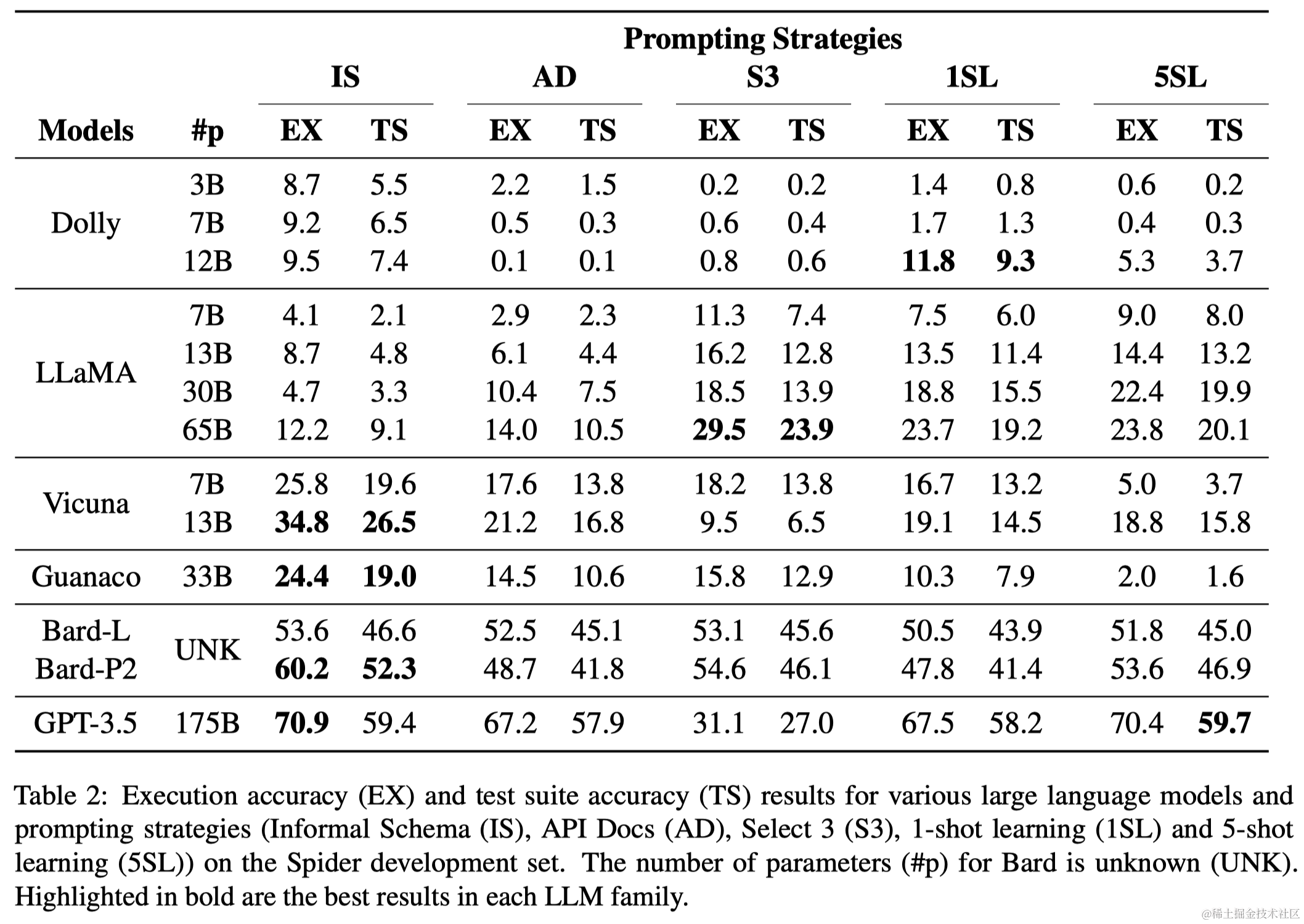
- 要点:本文对比了六种大型语言模型(包括ChatGPT、Dolly、LLaMA、Vicuna、Guanaco和Bard)在文本到SQL解析任务上的性能。尽管模型在生成语法正确的SQL语句方面表现出色,但在生成语义上仍有挑战。特别是,开源模型的表现普遍低于闭源模型。论文还指出,这些语言模型对少次学习中使用的示例非常敏感。
Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
- 链接:https://arxiv.org/abs/2305.12586
- 摘要:上下文学习(ICL)作为一种新的方法应用于各种自然语言处理任务,利用大型语言模型(LLMs)基于补充了少量示例或特定任务指令的上下文来进行预测。在这篇论文中,我们旨在将这种方法扩展到使用结构化知识源的问答任务,并通过探索使用LLMs的各种提示设计策略来改进文本到SQL系统。我们对不同的示例选择方法和提示LLMs的最佳指令格式进行了系统性的研究。我们的方法涉及利用示例SQL查询的语法结构来检索示例,并证明了在示例选择中追求多样性和相似性会带来性能的提升。此外,我们展示了LLMs从与数据库相关的知识增强中受益。我们最有效的策略在Spider数据集上比最先进的系统高出2.5个百分点(执行准确率),比最佳微调系统高出5.1个百分点。这些结果凸显了我们的方法在适应文本到SQL任务中的有效性,并且我们对促成我们策略成功的因素进行了分析。
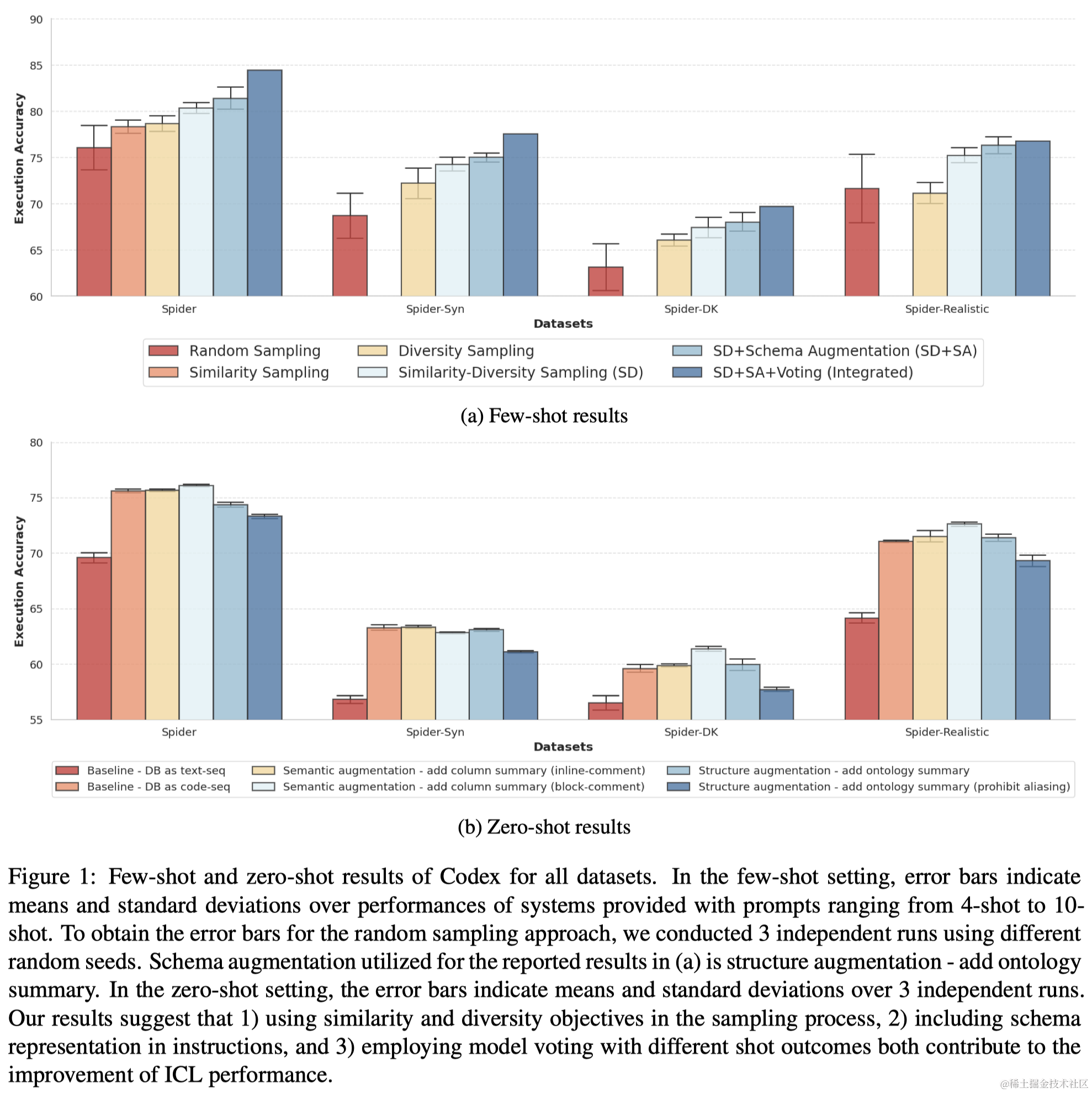
- 要点:本文主要探索了ICL中的Few-shot示例的选取原则,作者提出应该使用SQL的表征进行kNN选择而不是问题的表征,通过一系列实验证明了该方法的优越性。
- 笔记:LLM少样本示例的上下文学习在Text-to-SQL任务中的探索
Error Detection for Text-to-SQL Semantic Parsing
- 链接:https://arxiv.org/abs/2305.13683
- 摘要:尽管近年来文本到SQL语义解析取得了显著进展,但现有解析器的性能仍远非完美。与此同时,基于现代深度学习的文本到SQL解析器经常过于自信,因此在实际使用时对其可信度产生了怀疑。为此,我们提出建立一个独立于解析器的文本到SQL语义解析错误检测模型。所提出的模型基于预训练的代码语言模型,并通过图神经网络学习的结构特征进行增强。我们在跨领域环境中收集的真实解析错误上训练我们的模型。使用具有不同解码机制的三个强大的文本到SQL解析器进行的实验表明,我们的方法超越了依赖解析器的不确定性指标,并能有效地提高文本到SQL语义解析器的性能和可用性,无论它们的架构如何。
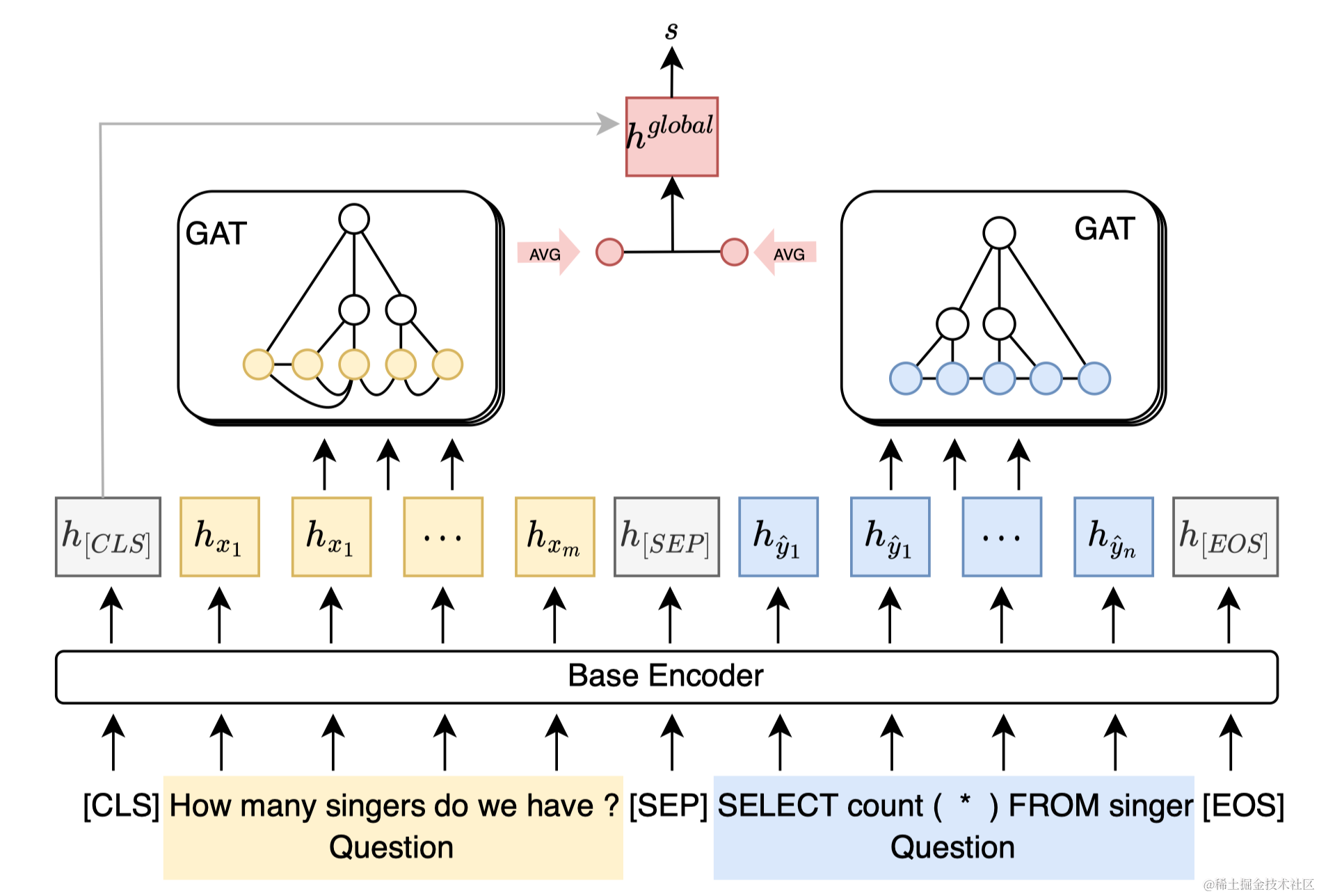
- 要点:本文基于CodeBERT训练了一个独立于解析器的SQL语义检查器,可以用于Text-to-SQL系统交互式触发检测和输出beam的重排序。
ReFSQL: A Retrieval-Augmentation Framework for Text-to-SQL Generation
- 链接:https://openreview.net/pdf/39418589877bfe8b6dae6abbd727bcdb81a46d15.pdf
- 摘要:文本到SQL是将自然语言问题转换为SQL查询的任务。现有方法直接将自然语言与SQL语言对齐,并训练一个基于编码器-解码器的模型来适应所有问题。然而,它们低估了SQL的固有结构特征,以及特定结构知识与一般知识之间的差距。这导致生成的SQL中出现结构错误。为了解决上述挑战,我们提出了一个检索增强框架,即ReFSQL。它包含两个部分:结构增强检索器和生成器。结构增强检索器旨在以无监督的方式识别具有可比特定知识的样本。随后,我们将检索到的样本的SQL纳入输入,使模型能够获得类似SQL语法的先验知识。为了进一步弥合特定知识与一般知识之间的差距,我们提出了一种马哈拉诺比斯对比学习方法,该方法有助于将样本转移到由检索样本构建的特定知识分布。在五个数据集上的实验结果验证了我们的方法在提高文本到SQL生成的准确性和鲁棒性方面的有效性。我们的框架在与许多其他主干模型(包括11B flan-T5)结合时取得了改进的性能,并在与采用微调方法的现有方法进行比较时,也取得了最先进的性能。
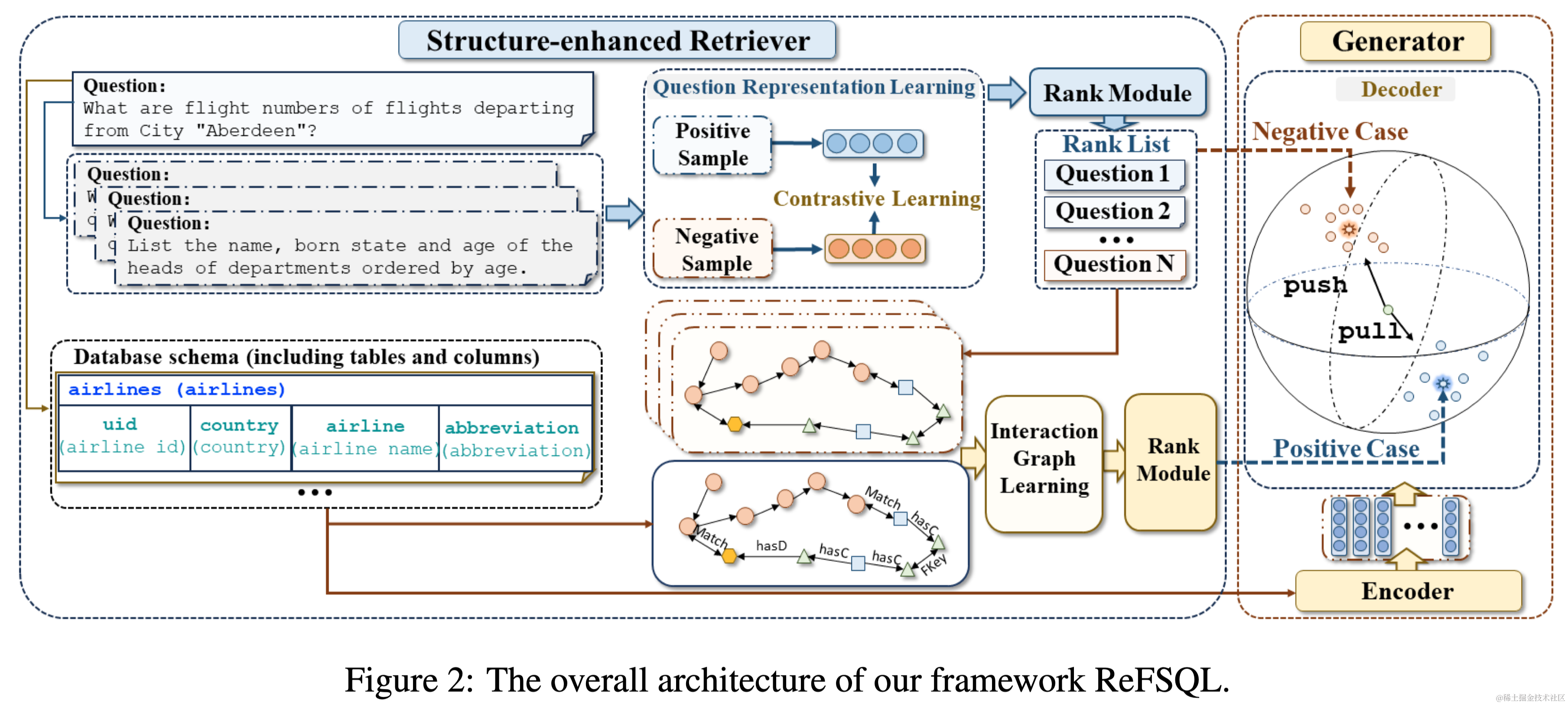
- 要点:提出使用检索式增强Text-to-SQL生成,并利用对比学习帮助解码器更好的学习到检索样本构建的特定知识分布。
Selective Demonstrations for Cross-domain Text-to-SQL
- 链接:https://arxiv.org/abs/2310.06302
- 摘要:具有上下文学习能力的大型语言模型(LLMs)在跨领域文本到SQL任务中展示了令人印象深刻的泛化能力,而无需使用领域内注释。然而,已发现纳入领域内的示例演示能大大提高LLMs的性能。在本文中,我们深入研究了领域内示例中对改善贡献的关键因素,并探索我们是否可以在不依赖领域内注释的情况下利用这些优势。基于我们的发现,我们提出了一个示例选择框架ODIS,该框架利用领域外示例和合成生成的领域内示例来构建演示。通过从混合来源检索演示,ODIS利用了两者的优势,与依赖单一数据源的基线方法相比,展示了其有效性。此外,ODIS在两个跨领域文本到SQL数据集上均超过了最先进的方法,执行准确率分别提高了1.1和11.8个百分点。

- 要点:本文介绍了ODIS框架,这是一种新颖的Text-to-SQL方法,它结合了领域外示例和合成生成的领域内示例,以提升大型语言模型在In-context Learning中的性能。
- 笔记:从领域外到领域内:LLM在Text-to-SQL任务中的演进之路
Semantic Decomposition of Question and SQL for Text-to-SQL Parsing
- 链接:https://arxiv.org/pdf/2310.13575v1.pdf
- 摘要:文本到SQL语义解析面临着泛化到跨领域和复杂查询的挑战。最近的研究采用了问题分解策略来增强复杂SQL查询的解析。然而,这种策略遇到了两个主要障碍:(1)现有数据集缺乏问题分解;(2)由于SQL的语法复杂性,大多数复杂查询无法分解为可以轻松重组的子查询。为了应对这些挑战,我们提出了一种新的模块化查询计划语言(QPL),它系统地将SQL查询分解为简单和规则的子查询。我们利用SQL服务器查询优化计划的分析,开发了从SQL到QPL的转换器,并用QPL程序增强了Spider数据集。实验结果表明,QPL的模块化特性有利于现有的语义解析架构,并且训练文本到QPL解析器比文本到SQL解析更有效,用于语义上等价的查询。
QPL方法还提供了两个额外的优势:(1)QPL程序可以被释义为简单的问题,这使我们能够创建一个(复杂问题,分解问题)的数据集。在这个数据集上训练,我们获得了一个对数据库模式敏感的数据检索问题分解器。(2)对于复杂查询,QPL对非专家来说更容易访问,导致语义解析器的输出更具可解释性。

- 要点:本文提出了一种叫做Query Plan Language (QPL)的语言,用来将复杂SQL语句分解为更加简单的子语句。QPL可以将复杂问题转述为简单问题,提供了一种复杂问题分解方案。同时,QPL对于非专家处理复杂查询更易于接近,使语义解析器的输出更易于理解。
- 笔记:QPL:一种新型的Text-to-SQL任务中间表示形式
SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data
- 链接:https://arxiv.org/abs/2311.02883
- 摘要:文本到SQL旨在自动化从自然语言文本生成数据库SQL查询的过程。在这项工作中,我们提出了“SQLPrompt”,专门用于提高大型语言模型(LLMs)的文本到SQL的少样本提示能力。我们的方法包括创新的提示设计、基于执行的一致性解码策略(在其他SQL提议中选择执行结果最一致的SQL),以及一种旨在通过在一致性选择期间使用不同的提示设计(“MixPrompt”)和基础模型(“MixLLMs”)多样化SQL提议来提高性能的方法。我们展示了SQLPrompt在少量标注数据的上下文学习中超过了以前的方法,以大幅度提升,缩小了与使用数千个标注数据进行微调的最新技术的差距。
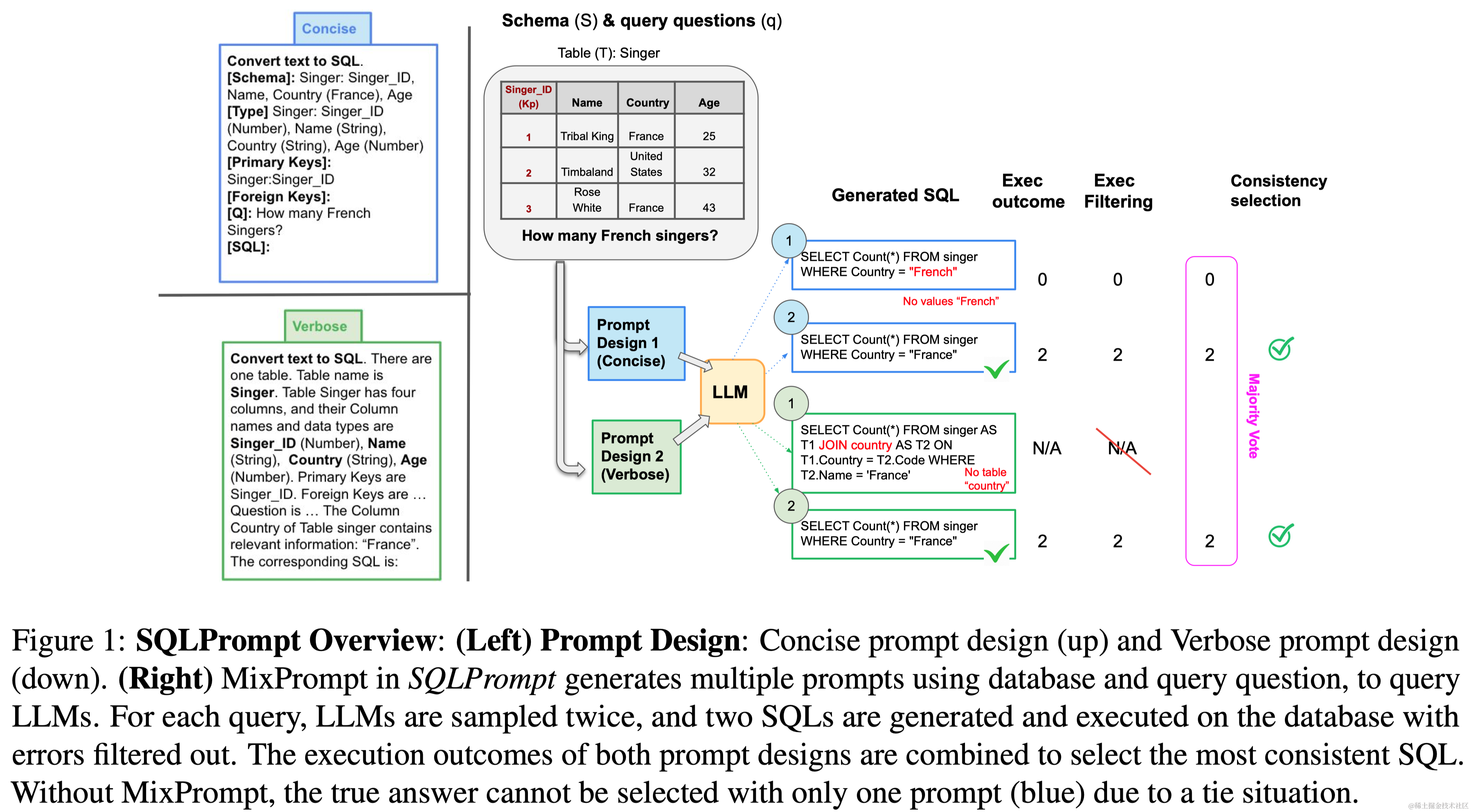
- 要点:本文提出了SQLPrompt,通过创新的Prompt设计、基于执行一致性的解码策略,以及混合不同格式的Prompt和不同LLMs输出的方式,提高了LLM在Few-shot In-context Learning下的能力。
- 笔记:论文笔记:SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data