NLP_Bag-Of-Words(词袋模型)
文章目录
- 词袋模型
- 用词袋模型计算文本相似度
- 1.构建实验语料库
- 2.给句子分词
- 3.创建词汇表
- 4.生成词袋表示
- 5.计算余弦相似度
- 6.可视化余弦相似度
- 词袋模型小结
词袋模型
词袋模型是一种简单的文本表示方法,也是自然语言处理的一个经典模型。它将文本中的词看作一个个独立的个体,不考虑它们在句子中的顺序,只关心每个词出现的频次,如下图所示
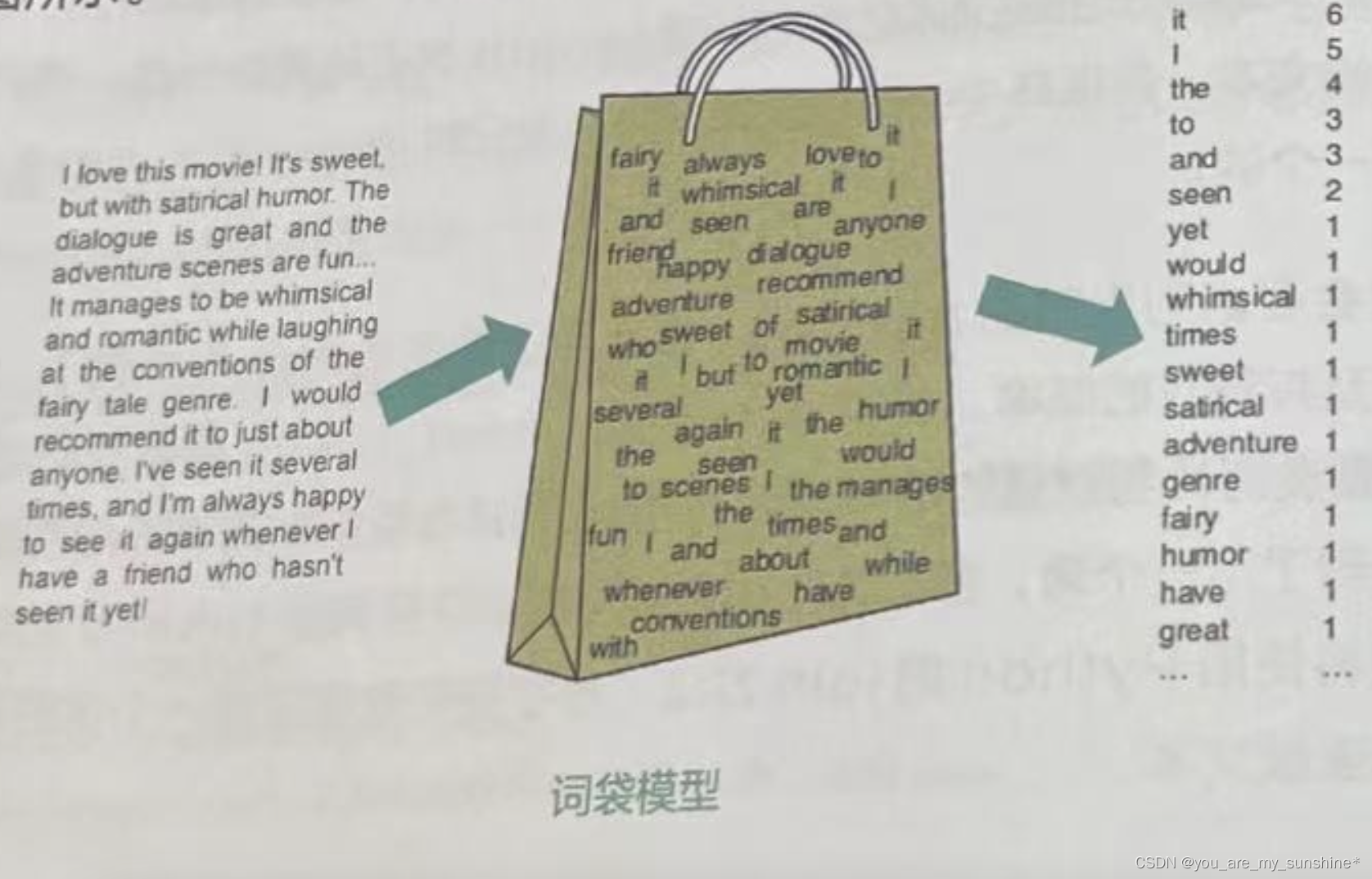
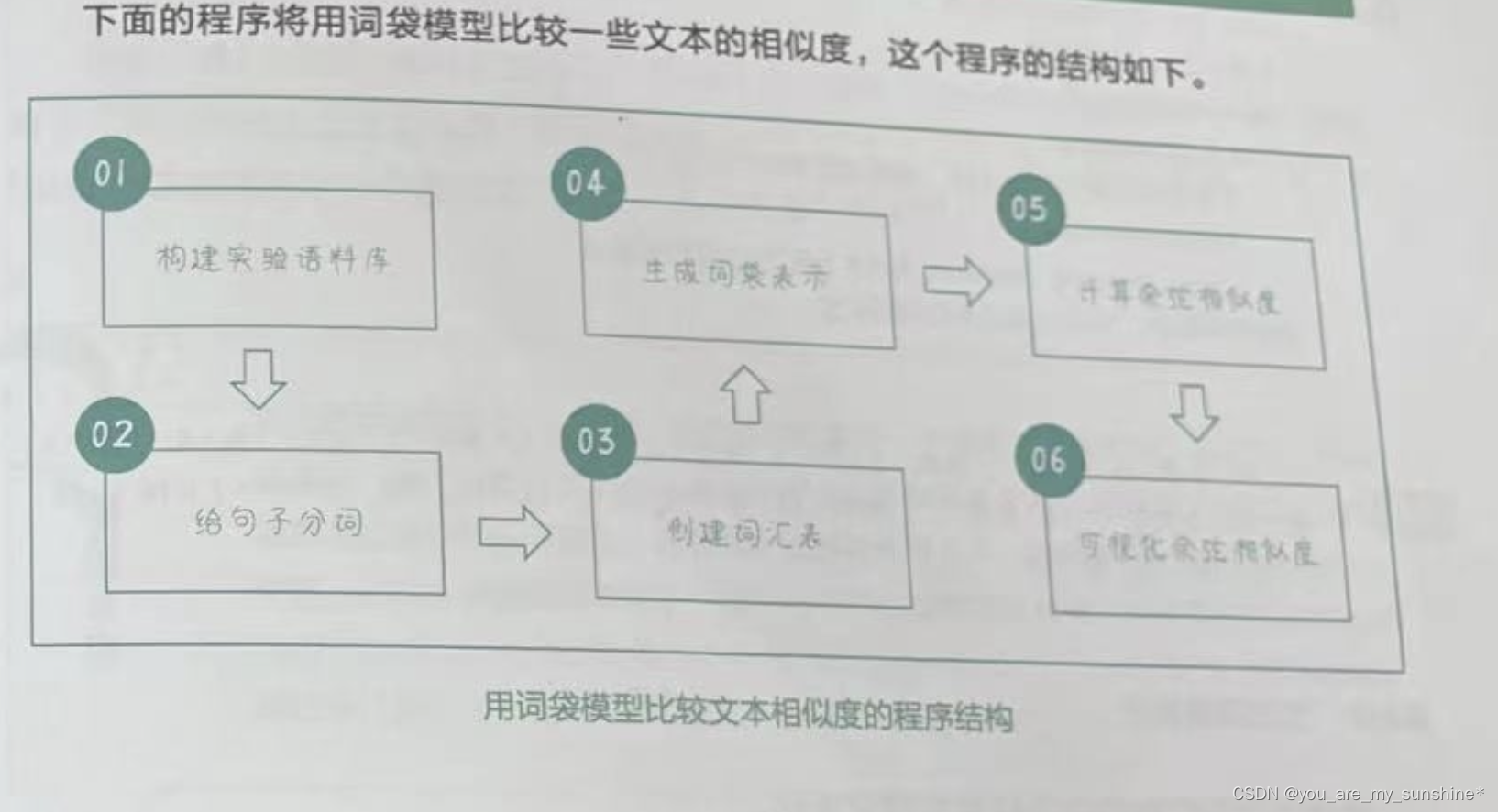
用词袋模型计算文本相似度
1.构建实验语料库
# 构建一个数据集
corpus = ["我特别特别喜欢看电影",
"这部电影真的是很好看的电影",
"今天天气真好是难得的好天气",
"我今天去看了一部电影",
"电影院的电影都很好看"]
2.给句子分词
# 对句子进行分词
import jieba # 导入 jieba 包
# 使用 jieba.cut 进行分词,并将结果转换为列表,存储在 corpus_tokenized 中
corpus_tokenized = [list(jieba.cut(sentence)) for sentence in corpus]
3.创建词汇表
# 创建词汇表
word_dict = {} # 初始化词汇表
# 遍历分词后的语料库
for sentence in corpus_tokenized:
for word in sentence:
# 如果词汇表中没有该词,则将其添加到词汇表中
if word not in word_dict:
word_dict[word] = len(word_dict) # 分配当前词汇表索引
print(" 词汇表:", word_dict) # 打印词汇表

4.生成词袋表示
# 根据词汇表将句子转换为词袋表示
bow_vectors = [] # 初始化词袋表示
# 遍历分词后的语料库
for sentence in corpus_tokenized:
# 初始化一个全 0 向量,其长度等于词汇表大小
sentence_vector = [0] * len(word_dict)
for word in sentence:
# 将对应词的索引位置加 1,表示该词在当前句子中出现了一次
sentence_vector[word_dict[word]] += 1
# 将当前句子的词袋向量添加到向量列表中
bow_vectors.append(sentence_vector)
print(" 词袋表示:", bow_vectors) # 打印词袋表示

5.计算余弦相似度
计算余弦相似度(Cosine Similarity),衡量两个文本向量的相似性。
余弦相似度可用来衡量两个向量的相似程度。它的值在-1到1之间,值越接近1,表示两个向量越相似;值越接近-1,表示两个向量越不相似;当值接近0时,表示两个向量之间没有明显的相似性。

余弦相似度和向量距离(Vector Distance)都可以衡量两个向量之间的相似性。余弦相似度关注向量之间的角度,而不是它们之间的距离,其取值范围在-1(完全相反)到1(完全相同)之间。向量距离关注向量之间的实际距离,通常使用欧几里得距离(Euclidean Distance)来计算。两个向量越接近,它们的距离越小。
如果要衡量两个向量的相似性,而不关心它们的大小,那么余弦相似度会更合适。因此,余弦相似度通常用于衡量文本、图像等高维数据的相似性,因为在这些场景下,关注向量的方向关系通常比关注距离更有意义。而在一些需要计算实际距离的应用场景,如聚类分析、推荐系统等,向量距离会更合适。
# 导入 numpy 库,用于计算余弦相似度
import numpy as np
# 定义余弦相似度函数
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2) # 计算向量 vec1 和 vec2 的点积
norm_a = np.linalg.norm(vec1) # 计算向量 vec1 的范数
norm_b = np.linalg.norm(vec2) # 计算向量 vec2 的范数
return dot_product / (norm_a * norm_b) # 返回余弦相似度
# 初始化一个全 0 矩阵,用于存储余弦相似度
similarity_matrix = np.zeros((len(corpus), len(corpus)))
# 计算每两个句子之间的余弦相似度
for i in range(len(corpus)):
for j in range(len(corpus)):
similarity_matrix[i][j] = cosine_similarity(bow_vectors[i],
bow_vectors[j])
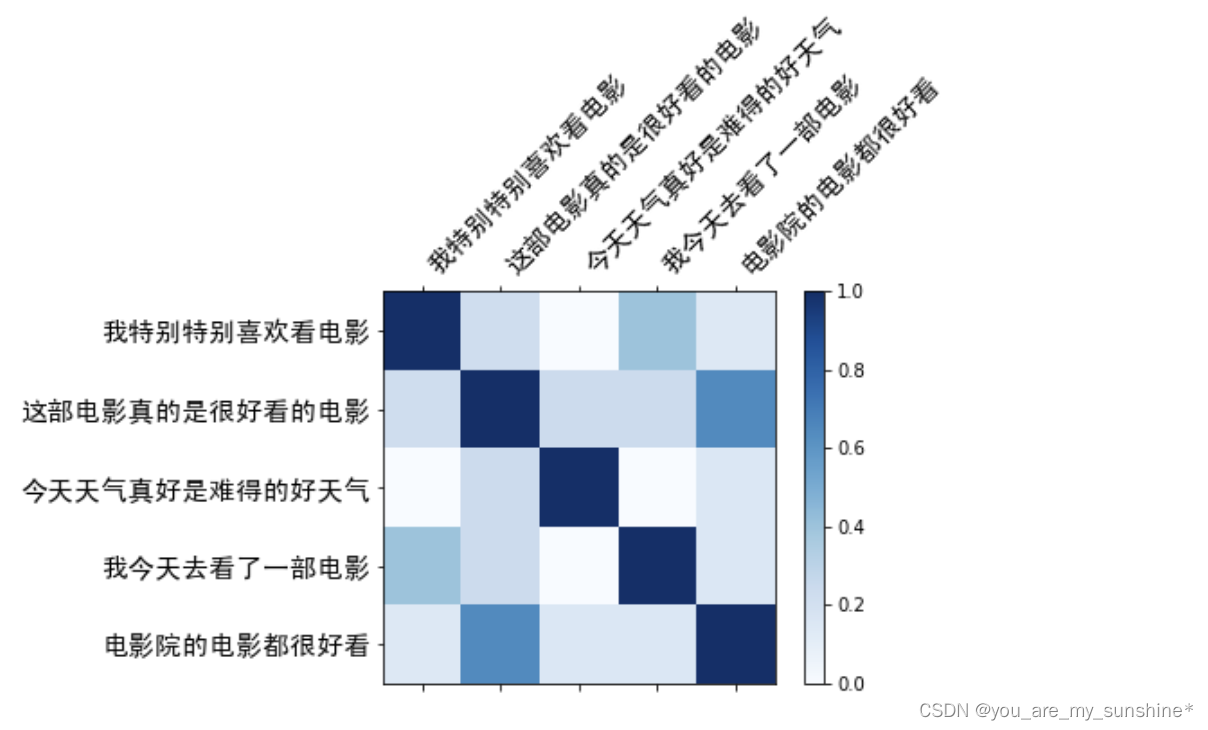
6.可视化余弦相似度
# 导入 matplotlib 库,用于可视化余弦相似度矩阵
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.font_manager import FontProperties
font = FontProperties(fname='SimHei.ttf', size = 15)
#plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
#plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
#plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
fig, ax = plt.subplots() # 创建一个绘图对象
# 使用 matshow 函数绘制余弦相似度矩阵,颜色使用蓝色调
cax = ax.matshow(similarity_matrix, cmap=plt.cm.Blues)
fig.colorbar(cax) # 条形图颜色映射
ax.set_xticks(range(len(corpus))) # x 轴刻度
ax.set_yticks(range(len(corpus))) # y 轴刻度
ax.set_xticklabels(corpus, rotation=45, ha='left', FontProperties = font) # 刻度标签
ax.set_yticklabels(corpus, FontProperties = font) # 刻度标签为原始句子
plt.show() # 显示图形
词袋模型小结
Bag-of-Words则是一种用于文本表示的技术,它将文本看作由单词构成的无序集合,通过统计单词在文本中出现的频次来表示文本。因此,Bag-of-Words主要用于文本分类、情感分析、信息检索等自然语言处理任务中。
- (1) Bag-of-Words是基于词频将文本表示为一个向量,其中每个维度对应词汇表中的一个单词,其值为该单词在文本中出现的次数。
- (2) Bag-of-Words忽略了文本中的词序信息,只关注词频。这使得词袋模型在某些任务中表现出色,如主题建模和文本分类,但在需要捕捉词序信息的任务中表现较差,如机器翻译和命名实体识别。
- (3)Bag-of-Words 可能会导致高维稀疏表示,因为文本向量的长度取决于词汇表的大小。为解决这个问题,可以使用降维技术,如主成分分析(Principal Component Analysis,PCA)或潜在语义分析(Latent Semantic Analysis,LSA)。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…