应用层协议 HTTP HTTPS
目录
应用层
再谈 "协议"
序列化和反序列化
关于 json库
request序列化
request反序列化
response序列化
response反序列化
PS:命令宏
HTTP协议
认识URL
urlencode和urldecode
HTTP协议格式
HTTP请求
HTTP响应
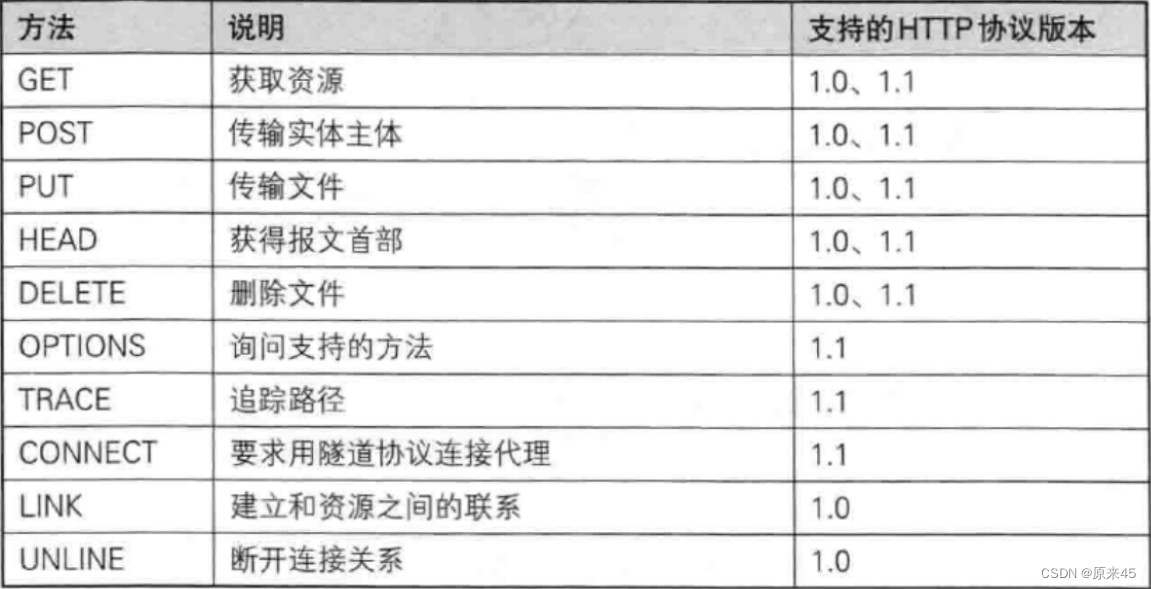
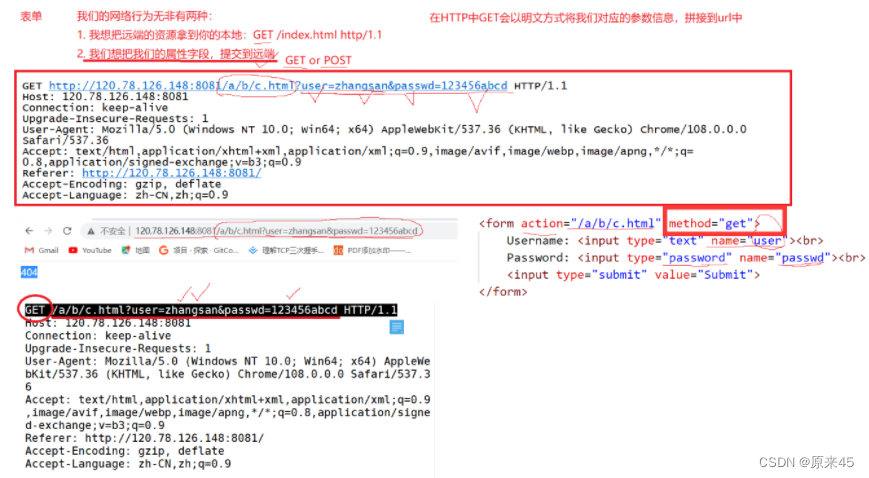
请求方法
编辑
HTTP的请求方法
GET方法
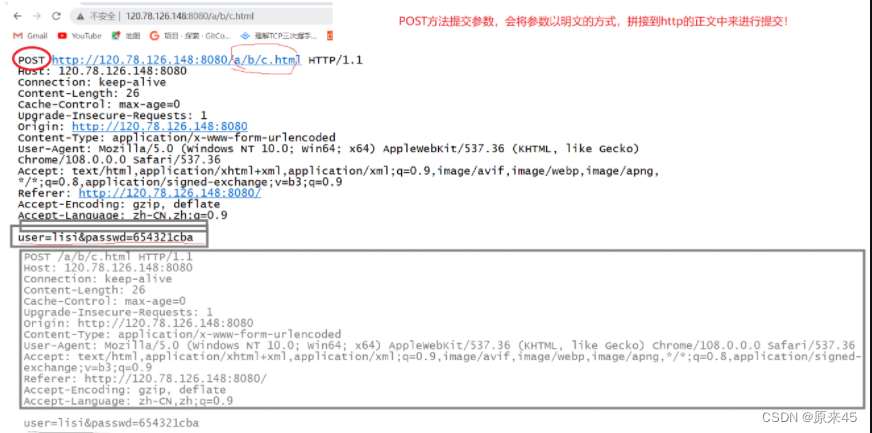
POST方法(浏览器自动选择POST)
GRT VS POST
注意是私密,不是安不安全,GET和POST都是不安全的!
HTTP的状态码
HTTP常见Header
最简单的HTTP服务器
HTTPS协议
HTTPS 是什么
加密
为什么加密
常⻅的加密⽅式
对称加密
⾮对称加密
数据摘要 && 数据指纹
数字签名
引⼊证书
CA认证
CSR
理解数据签名
HTTPS保证安全通信
客⼾端进⾏认证
查看浏览器的受信任证书发布机构
编辑对于常见的问题
中间⼈有没有可能篡改该证书?
中间⼈整个掉包证书?
为什么摘要内容在⽹络传输的时候⼀定要加密形成签名?
为什么签名不直接加密,⽽是要先hash形成摘要?
如何成为中间⼈?
完整流程
C语言总结 在这 常见八大排序 在这
作者和朋友建立的社区: 非科班转码社区-CSDN社区云 💖 💛 💙
期待hxd的支持哈 🎉 🎉 🎉
最后是打鸡血环节: 想多了都是问题,做多了都是答案 🚀 🚀 🚀
最近作者和好友建立了一个公众号
公众号介绍:
专注于自学编程领域。由USTC、WHU、SDU等高校学生、ACM竞赛选手、CSDN万粉博主、双非上岸BAT学长原创。分享业内资讯、硬核原创资源、职业规划等,和大家一起努力、成长。( 二维码在文章底部哈! )
应用层
我们程序员写的一个个解决我们实际问题 , 满足我们日常需求的网络程序 , 都是在应用层
再谈 "协议"
协议是一种 " 约定 ". socket api 的接口 , 在读写数据时 , 都是按 " 字符串 " 的方式来发送接收的 . 如果我们要传输一些 "结构化的数据 " 怎么办呢?例如 , 我们需要实现一个服务器版的加法器 . 我们需要客户端把要计算的两个加数发过去 , 然后由服务器进行计算 , 最后再把结果返回给客户端约定方案一 :客户端发送一个形如 "1+1" 的字符串 ;这个字符串中有两个操作数 , 都是整形 ;两个数字之间会有一个字符是运算符 , 运算符只能是 + ;数字和运算符之间没有空格约定方案二:定义结构体来表示我们需要交互的信息 ;发送数据时将这个结构体按照一个规则转换成字符串 , 接收到数据的时候再按照相同的规则把字符串转化回结构体;这个过程叫做 " 序列化 " 和 " 反序列化 "无论我们采用方案一 , 还是方案二 , 还是其他的方案 , 只要保证 , 一端发送时构造的数据 , 在另一端能够正确的进行解析, 就是 ok 的 . 这种约定 , 就是 应用层协议。
序列化和反序列化
我们把一个结构化数据转换为字符串/字符流的序列称为序列化。
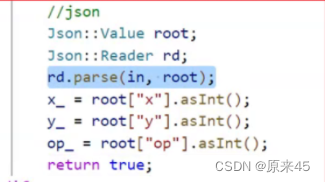
我们把发过来的字符串按照我们的要求转换为服务器所需要的对象我们称为反序列化。关于 json库
request序列化
是有两种方法
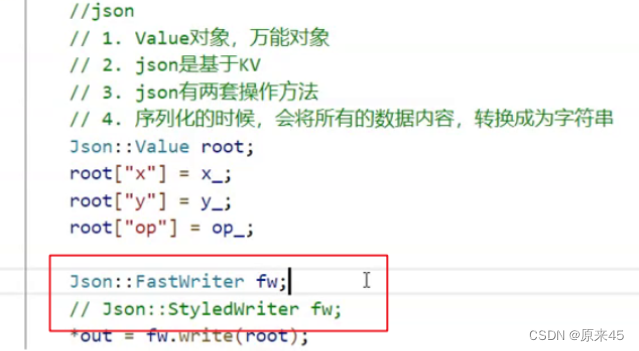
request反序列化
response序列化
response反序列化

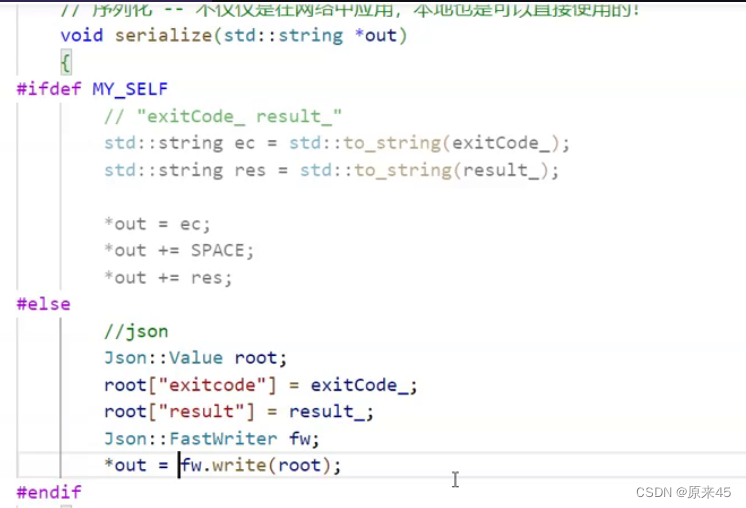
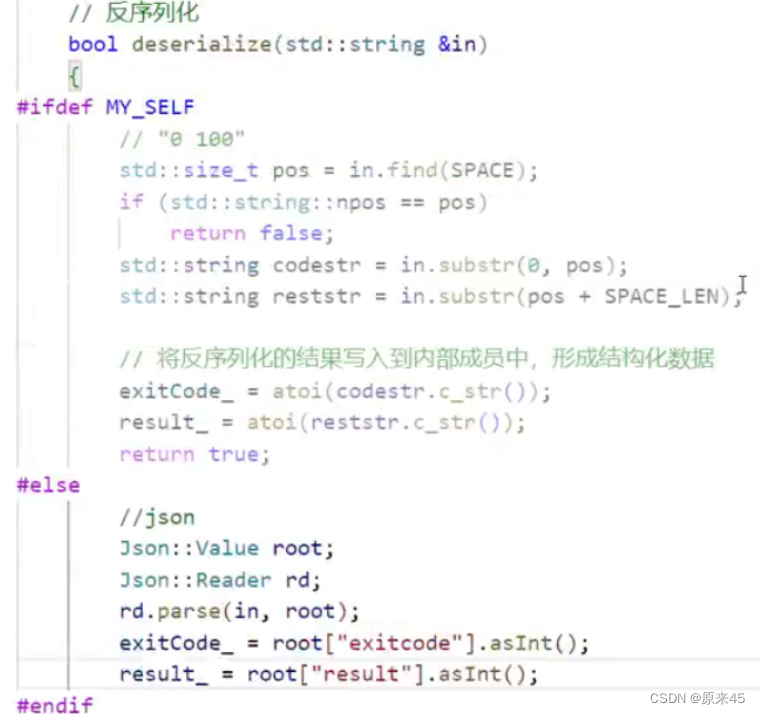
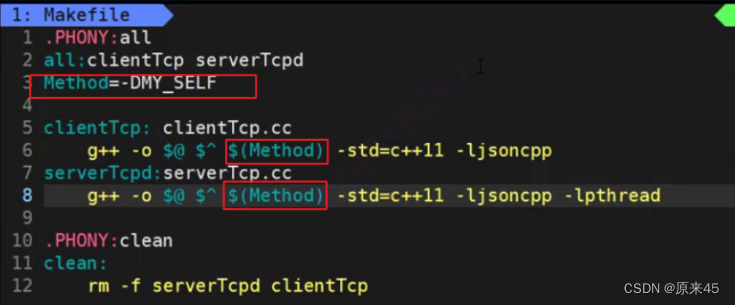
PS:命令宏
-D --> 命令行式去定义宏
这就是定义了一个宏MY_SELF
注释掉Method就是空,就说明MY_SELF没有定义,这样我们就可以通过makefile来去是否定义宏从而选择是否使用json的那部分代码,这样就不用改源代码了 。
HTTP协议
 可以省略端口号是因为这些成熟的协议,端口号和协议是绑定的,知道了协议,也就知道端口号虽然我们说 , 应用层协议是我们程序猿自己定的 .但实际上 , 已经有大佬们定义了一些现成的 , 又非常好用的应用层协议 , 供我们直接参考使用 . HTTP( 超文本传输协议 ) 就是其中之一.
可以省略端口号是因为这些成熟的协议,端口号和协议是绑定的,知道了协议,也就知道端口号虽然我们说 , 应用层协议是我们程序猿自己定的 .但实际上 , 已经有大佬们定义了一些现成的 , 又非常好用的应用层协议 , 供我们直接参考使用 . HTTP( 超文本传输协议 ) 就是其中之一.认识URL
url(unite resource locacte):统一资源定位符
url上面ip+port+路径就定位了全球网络上唯一的一份资源
平时我们俗称的 " 网址 " 其实就是说的 URL
urlencode和urldecode
像 / ? : 等这样的字符 , 已经被 url 当做特殊意义理解了 . 因此这些字符不能随意出现 .比如 , 某个参数中需要带有这些特殊字符 , 就必须先对特殊字符进行转义 .转义的规则如下 :将需要转码的字符转为 16 进制,然后从右到左,取 4 位 ( 不足 4 位直接处理 ) ,每 2 位做一位,前面加上 % ,编码成 %XY格式例如 :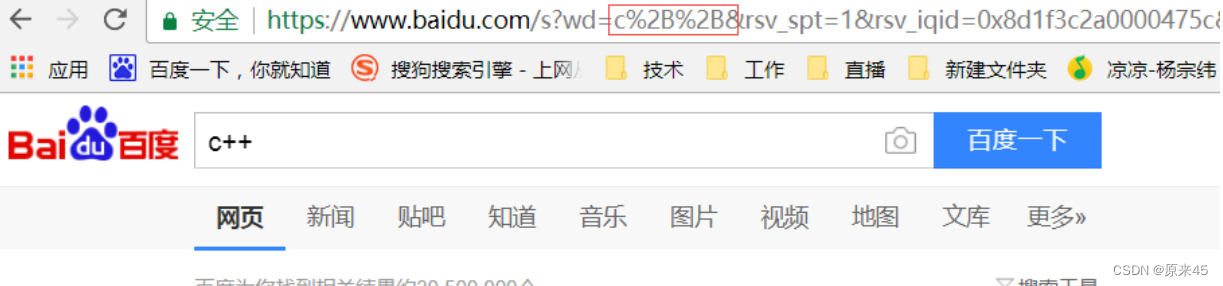 "+" 被转义成了 "%2B"urldecode 就是 urlencode 的逆过程 ;
"+" 被转义成了 "%2B"urldecode 就是 urlencode 的逆过程 ;HTTP协议格式
HTTP请求
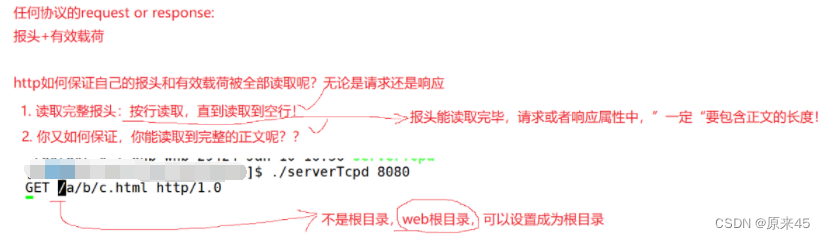
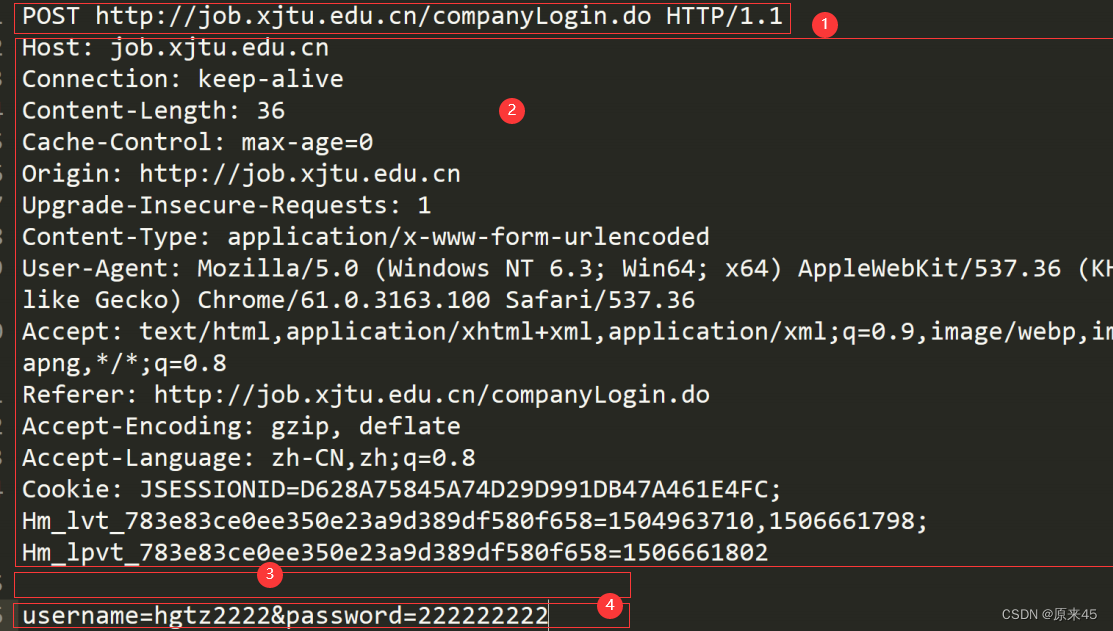 首行 : [ 方法 ] + [url] + [ 版本 ]Header: 请求的属性 , 冒号分割的键值对 ; 每组属性之间使用 \n 分隔 ; 遇到空行表示 Header 部分结束Body: 空行后面的内容都是 Body. Body 允许为空字符串 . 如果 Body 存在 , 则在 Header 中会有一个Content-Length属性来标识 Body 的长度 ;http是基于行的一个协议
首行 : [ 方法 ] + [url] + [ 版本 ]Header: 请求的属性 , 冒号分割的键值对 ; 每组属性之间使用 \n 分隔 ; 遇到空行表示 Header 部分结束Body: 空行后面的内容都是 Body. Body 允许为空字符串 . 如果 Body 存在 , 则在 Header 中会有一个Content-Length属性来标识 Body 的长度 ;http是基于行的一个协议
右边第一个可以叫做状态行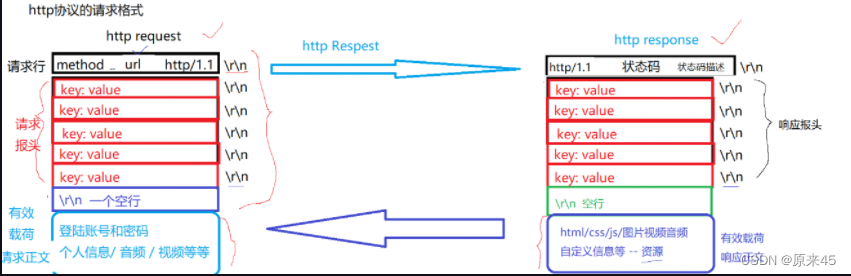
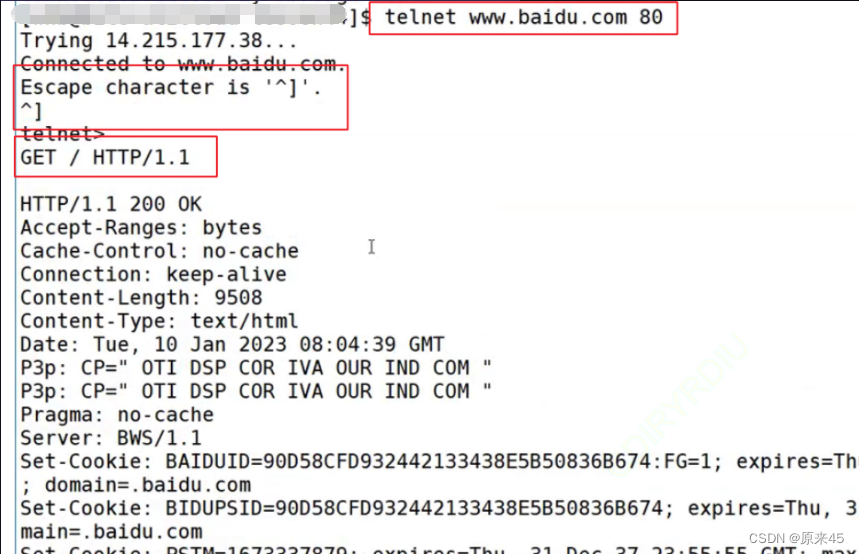
通过命令行获取百度给他的响应
telnet GET / HTTP/1.1
(telnet 远程以协议的方式登录某种服务)
(http在请求时大小写是忽略的)
展现出来的东西和上面画的图是对应的
2是我们的输入,进入telnet命令行
3是GET那行,就是我们去发送 GET / http/1.0
然后给我们返回了HTTP....(得到的响应)HTTP响应
首行 : [ 版本号 ] + [ 状态码 ] + [ 状态码解释 ]Header: 请求的属性 , 冒号分割的键值对 ; 每组属性之间使用 \n 分隔 ; 遇到空行表示 Header 部分结束Body: 空行后面的内容都是 Body. Body 允许为空字符串 . 如果 Body 存在 , 则在 Header 中会有一个Content-Length属性来标识 Body 的长度 ; 如果服务器返回了一个 html 页面 , 那么 html 页面内容就是在body中 .请求方法
HTTP的请求方法
其中最常用的就是GET方法和POST方法.
GET方法
POST方法(浏览器自动选择POST)
GRT VS POST
注意是私密,不是安不安全,GET和POST都是不安全的!
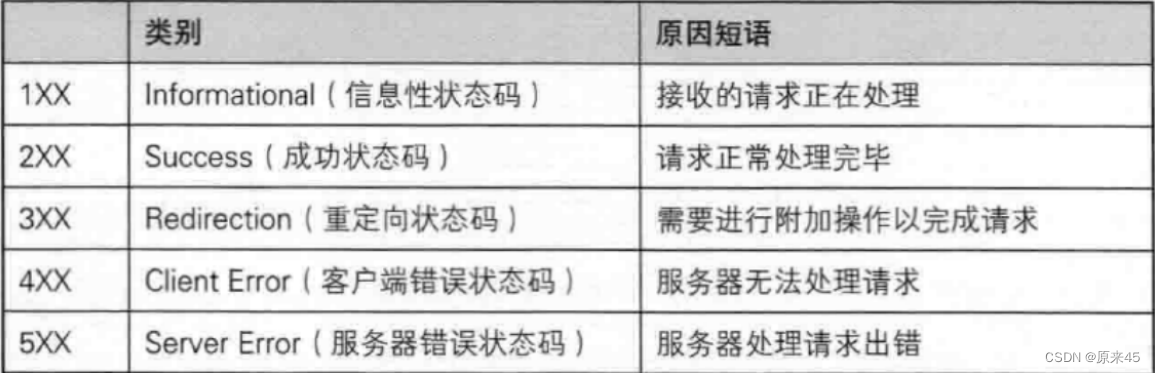
HTTP的状态码
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
HTTP常见Header
Content-Type: 数据类型 (text/html 等 );Content-Length: Body 的长度;Host: 客户端告知服务器 , 所请求的资源是在哪个主机的哪个端口上 ;User-Agent: 声明用户的操作系统和浏览器版本信息 ;referer: 当前页面是从哪个页面跳转过来的 ;location: 搭配 3xx 状态码使用 , 告诉客户端接下来要去哪里访问 ;Cookie: 用于在客户端存储少量信息 . 通常用于实现会话 (session) 的功能;最简单的HTTP服务器
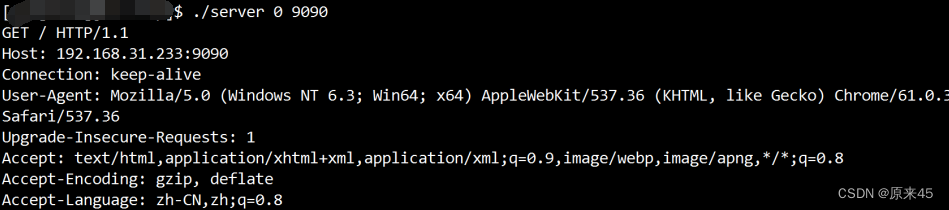
实现一个最简单的 HTTP 服务器 , 只在网页上输出 "hello world"; 只要我们按照 HTTP 协议的要求构造数据 , 就很容易能做到;#include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <unistd.h> #include <stdio.h> #include <string.h> #include <stdlib.h> void Usage() { printf("usage: ./server [ip] [port]\n"); } int main(int argc, char *argv[]) { if (argc != 3) { Usage(); return 1; } // 1 int fd = socket(AF_INET, SOCK_STREAM, 0); if (fd < 0) { perror("socket"); return 1; } // 2 struct sockaddr_in addr; addr.sin_family = AF_INET; addr.sin_addr.s_addr = inet_addr(argv[1]); addr.sin_port = htons(atoi(argv[2])); // 3 int ret = bind(fd, (struct sockaddr *)&addr, sizeof(addr)); if (ret < 0) { perror("bind"); return 1; } // 4 ret = listen(fd, 10); if (ret < 0) { perror("listen"); return 1; } for (;;) { struct sockaddr_in client_addr; socklen_t len; // 5 int client_fd = accept(fd, (struct sockaddr *)&client_addr, &len); if (client_fd < 0) { perror("accept"); continue; } char input_buf[1024 * 10] = {0}; // 用一个足够大的缓冲区直接把数据读完. ssize_t read_size = read(client_fd, input_buf, sizeof(input_buf) - 1); if (read_size < 0) { return 1; } printf("[Request] %s", input_buf); char buf[1024] = {0}; const char *hello = "<h1>hello world</h1>"; sprintf(buf, "HTTP/1.0 200 OK\nContent-Length:%lu\n\n%s", strlen(hello), hello); write(client_fd, buf, strlen(buf)); } return 0; }编译 , 启动服务 . 在浏览器中输入 http://[ip]:[port], 就能看到显示的结果 "Hello World"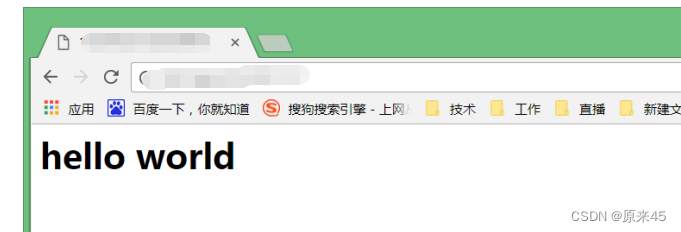
备注:
此处我们使用 9090 端口号启动了 HTTP 服务器 . 虽然 HTTP 服务器一般使用 80 端口 ,但这只是一个通用的习惯 . 并不是说 HTTP 服务器就不能使用其他的端口号 .使用 chrome 测试我们的服务器时 , 可以看到服务器打出的请求中还有一个 GET /favicon.ico HTTP/1.1 这样的请求.




HTTPS协议
HTTPS 是什么
s--SSL/TLS https发送的数据会经过这个s进行加密。
HTTPS 也是⼀个应⽤层协议. 是在 HTTP 协议的基础上引⼊了⼀个加密层.HTTP 协议内容都是按照⽂本的⽅式明⽂传输的. 这就导致在传输过程中出现⼀些被篡改的情况
PS:
我们目前考虑的是传输的问题,客户端属于360等属于桌面级软件的开发,服务端他们公司的机房的硬件和他们的软件都具有工业级安全的能力,所以我们考虑中间人攻击。
加密
加密就是把 明⽂ (要传输的信息)进⾏⼀系列变换, ⽣成 密⽂
解密就是把 密⽂ 再进⾏⼀系列变换, 还原成 明⽂在这个加密和解密的过程中, 往往需要⼀个或者多个中间的数据, 辅助进⾏这个过程, 这样的数据称为 密钥 (正确发⾳ yue 四声, 不过⼤家平时都读作 yao 四声为什么加密
因为http的内容是明⽂传输的,明⽂数据会经过路由器、wifi热点、通信服务运营商、代理服务 器等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传 输的信息且不被双⽅察觉,这就是 中间⼈攻击 ,所以我们才需要对信息进⾏加密。在互联⽹上, 明⽂传输是⽐较危险的事情!!!HTTPS 就是在 HTTP 的基础上进⾏了加密, 进⼀步的来保证⽤⼾的信息安全~常⻅的加密⽅式
对称加密
- 采⽤单钥密码系统的加密⽅法,同⼀个密钥可以同时⽤作信息的加密和解密,这种加密⽅法称为对称加密,也称为单密钥加密,特征:加密和解密所⽤的密钥是相同的。
- 常⻅对称加密算法(了解):DES、3DES、AES、TDEA、Blowfish、RC2等。
- 特点:算法公开、计算量⼩、加密速度快、加密效率⾼。
对称加密其实就是通过同⼀个 "密钥" , 把明⽂加密成密⽂, 并且也能把密⽂解密成明⽂[ ⼀个简单的对称加密, 按位异或假设 明⽂ a = 1234, 密钥 key = 8888则加密 a ^ key 得到的密⽂ b 为 9834.然后针对密⽂ 9834 再次进⾏运算 b ^ key, 得到的就是原来的明⽂ 1234.(对于字符串的对称加密也是同理, 每⼀个字符都可以表⽰成⼀个数字)当然, 按位异或只是最简单的对称加密. HTTPS 中并不是使⽤按位异或.]⾮对称加密
- 需要两个密钥来进⾏加密和解密,这两个密钥是公开密钥(public key,简称公钥)和私有密钥 (private key,简称私钥)。
- 常⻅⾮对称加密算法(了解):RSA,DSA,ECDSA。
- 特点:算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,⽽使得加密解密速度没有对称加密解密的速度快。
⾮对称加密要⽤到两个密钥, ⼀个叫做 "公钥", ⼀个叫做 "私钥"。公钥和私钥是配对的. 最⼤的缺点就是运算速度⾮常慢,⽐对称加密要慢很多。通过公钥对明⽂加密, 变成密⽂通过私钥对密⽂解密, 变成明⽂也可以反着⽤通过私钥对明⽂加密, 变成密⽂通过公钥对密⽂解密, 变成明⽂数据摘要 && 数据指纹
- 数字指纹(数据摘要),其基本原理是利⽤单向散列函数(Hash函数)对信息进⾏运算,⽣成⼀串固定⻓度的数字摘要。数字指纹并不是⼀种加密机制,但可以⽤来判断数据有没有被窜改。
- 摘要常⻅算法:有MD5、SHA1、SHA256、SHA512等,算法把⽆限的映射成有限,因此可能会有碰撞(两个不同的信息,算出的摘要相同,但是概率⾮常低)。
- 摘要特征:和加密算法的区别是,摘要严格意义不是加密,因为没有解密,只不过从摘要很难反推原信息,通常⽤来进⾏数据对⽐。
数字签名
摘要经过加密,就得到数字签名。既然要保证数据安全, 就需要进⾏ "加密"。⽹络传输中不再直接传输明⽂了, ⽽是加密之后的 "密⽂"。加密的⽅式有很多, 但是整体可以分成两⼤类: 对称加密 和 ⾮对称加密。引⼊证书
为了防止中间人攻击,便引入了证书。
CA认证
服务端在使⽤HTTPS前,需要向CA机构申领⼀份数字证书,数字证书⾥含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书⾥获取公钥就⾏了,证书就如⾝份证,证明服务端公钥的权威性。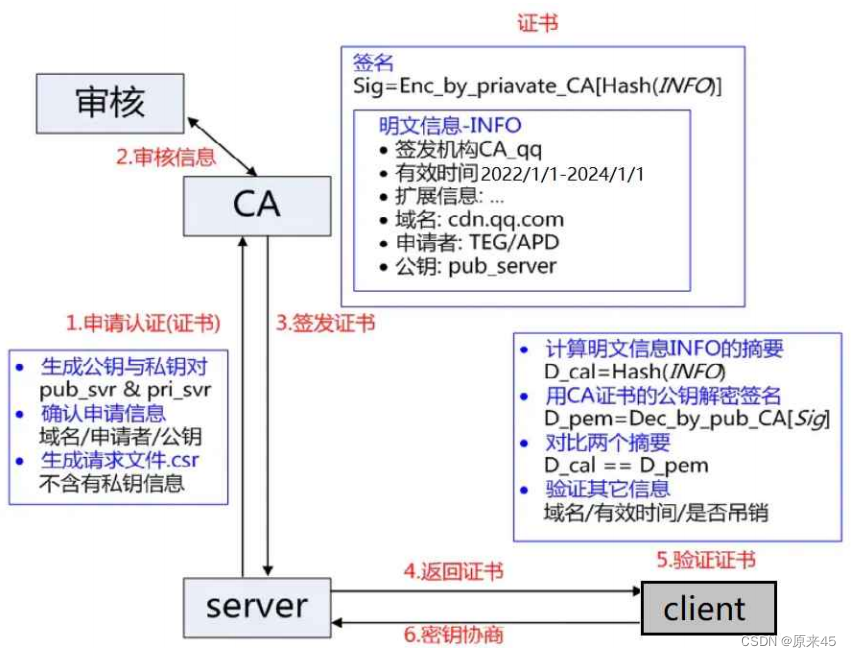
这个 证书 可以理解成是⼀个结构化的字符串, ⾥⾯包含了以下信息:
- 证书发布机构
- 证书有效期
- 公钥
- 证书所有者
- 签名
- ......
需要注意的是:申请证书的时候,需要在特定平台⽣成,会同时⽣成⼀对⼉密钥对⼉,即公钥和私钥。这对密钥对⼉就是⽤来在⽹络通信中进⾏明⽂加密以及数字签名的。其中公钥会随着CSR⽂件,⼀起发给CA进⾏权威认证,私钥服务端⾃⼰保留,⽤来后续进⾏通信(其实主要就是⽤来交换对称秘钥)CSR
可以使⽤在线⽣成CSR和私钥:https://myssl.com/csr_create.html
形成CSR之后,后续就是向CA进⾏申请认证,不过⼀般认证过程很繁琐,⽹络各种提供证书申请的服务商,⼀般真的需要,直接找平台解决就⾏。理解数据签名
签名的形成是基于⾮对称加密算法的,注意,⽬前暂时和https没有关系,不要和https中的公钥私钥搞混了。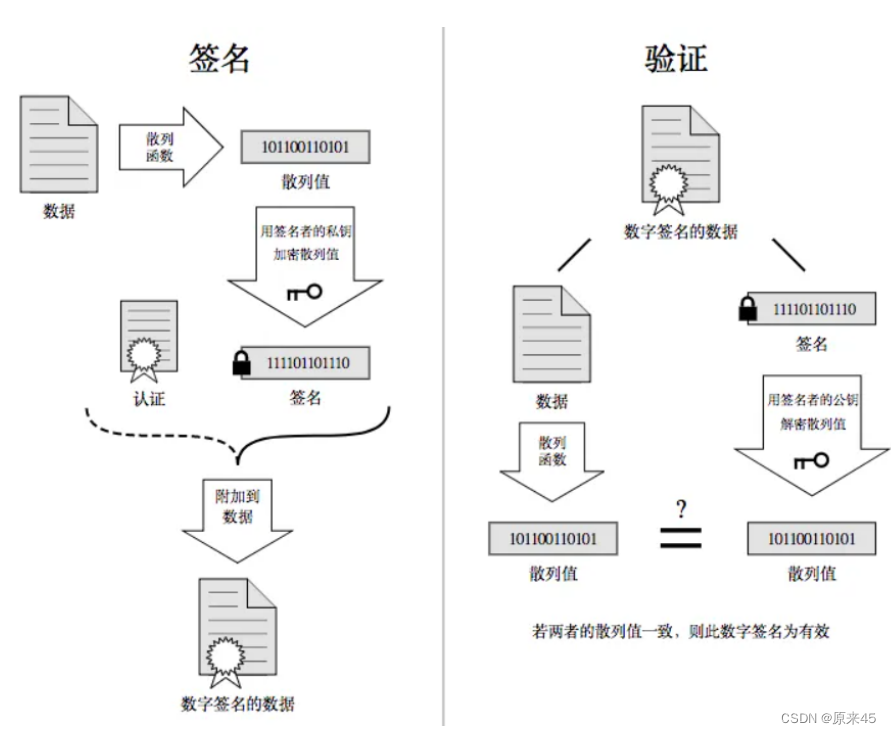 当服务端申请CA证书的时候,CA机构会对该服务端进⾏审核,并专⻔为该⽹站形成数字签名,过程如下:
当服务端申请CA证书的时候,CA机构会对该服务端进⾏审核,并专⻔为该⽹站形成数字签名,过程如下:
- CA机构拥有⾮对称加密的私钥A和公钥A'。
- CA机构对服务端申请的证书明⽂数据进⾏hash,形成数据摘要。
- 然后对数据摘要⽤CA私钥A'加密,得到数字签名S。
服务端申请的证书明⽂和数字签名S 共同组成了数字证书,这样⼀份数字证书就可以颁发给服务端了。HTTPS保证安全通信
⾮对称加密 + 对称加密 + 证书认证
在客⼾端和服务器刚⼀建⽴连接的时候, 服务器给客⼾端返回⼀个 证书,证书包含了之前服务端的公钥, 也包含了⽹站的⾝份信息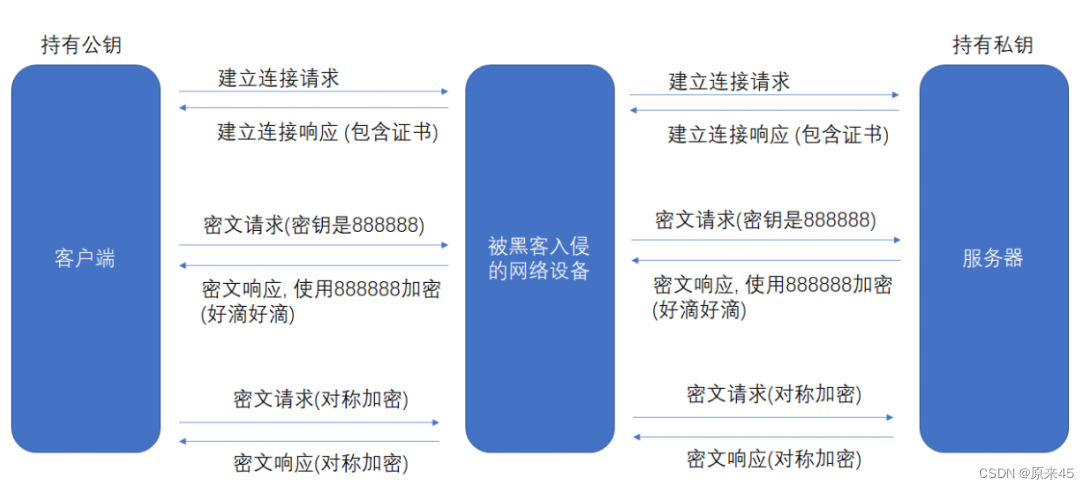
客⼾端进⾏认证
- 当客⼾端获取到这个证书之后, 会对证书进⾏校验(防⽌证书是伪造的).
- 判定证书的有效期是否过期.
- 判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构). 验证证书是否被篡改: 从系统中拿到该证书发布机构的公钥, 对签名解密, 得到⼀个 hash 值(称为数据摘要), 设为 hash1. 然后计算整个证书的 hash 值, 设为 hash2. 对⽐ hash1 和 hash2 是否相等. 如果相等, 则说明证书是没有被篡改过的.
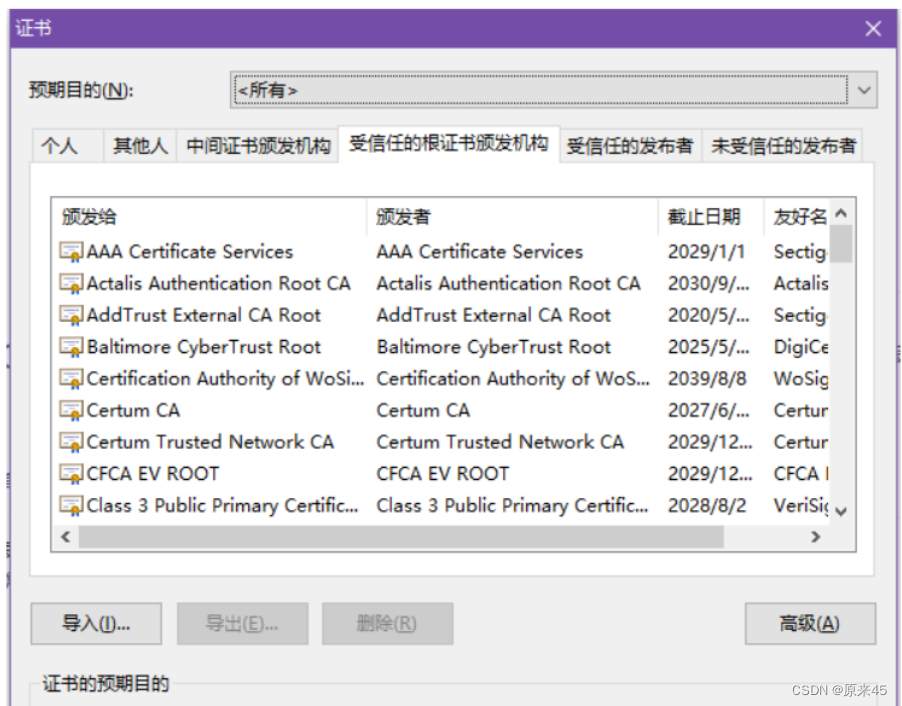
查看浏览器的受信任证书发布机构
Chrome 浏览器, 点击右上⻆的
选择 "设置", 搜索 "证书管理" , 即可看到以下界⾯. (如果没有,在隐私设置和安全性->安全⾥⾯找找)
对于常见的问题
中间⼈有没有可能篡改该证书?
- 中间⼈篡改了证书的明⽂。
- 由于他没有CA机构的私钥,所以⽆法hash之后⽤私钥加密形成签名,那么也就没法办法对篡改后的证书形成匹配的签名。
- 如果强⾏篡改,客⼾端收到该证书后会发现明⽂和签名解密后的值不⼀致,则说明证书已被篡改,证书不可信,从⽽终⽌向服务器传输信息,防⽌信息泄露给中间⼈。
PS:如果中间人是把证书篡改,用的他自己的私钥加密,但是Client不会用他的公钥解密,是用的自己的(CA)公钥解密,这样和明文hash后的数据摘要和解密后的摘要还是匹配不上的!
中间⼈整个掉包证书?
- 因为中间⼈没有CA私钥,所以⽆法制作假的证书。(因为客户端是用CA的公钥解密的)
- 所以中间⼈只能向CA申请真证书,然后⽤⾃⼰申请的证书进⾏掉包。
- 这个确实能做到证书的整体掉包,但是别忘记,证书明⽂中包含了域名等服务端认证信息,如果整体掉包,客⼾端依旧能够识别出来。
- 永远记住:中间⼈没有CA私钥,所以对任何证书都⽆法进⾏合法修改,包括⾃⼰的。
为什么摘要内容在⽹络传输的时候⼀定要加密形成签名?
常⻅的摘要算法有: MD5 和 SHA 系列以 MD5 为例, 我们不需要研究具体的计算签名的过程, 只需要了解 MD5 的特点:
- 定⻓: ⽆论多⻓的字符串, 计算出来的 MD5 值都是固定⻓度 (16字节版本或者32字节版本)
- 分散: 源字符串只要改变⼀点点, 最终得到的 MD5 值都会差别很⼤.
- 不可逆: 通过源字符串⽣成 MD5 很容易, 但是通过 MD5 还原成原串理论上是不可能的.
正因为 MD5 有这样的特性, 我们可以认为如果两个字符串的 MD5 值相同, 则认为这两个字符串相同.理解判定证书篡改的过程: (这个过程就好⽐判定这个⾝份证是不是伪造的⾝份证)假设我们的证书只是⼀个简单的字符串 hello, 对这个字符串计算hash值(⽐如md5), 结果为BC4B2A76B9719D91如果 hello 中有任意的字符被篡改了, ⽐如变成了 hella, 那么计算的 md5 值就会变化很⼤.BDBD6F9CF51F2FD8然后我们可以把这个字符串 hello 和 哈希值 BC4B2A76B9719D91 从服务器返回给客⼾端, 此时客⼾端如何验证 hello 是否是被篡改过?那么就只要计算 hello 的哈希值, 看看是不是 BC4B2A76B9719D91 即可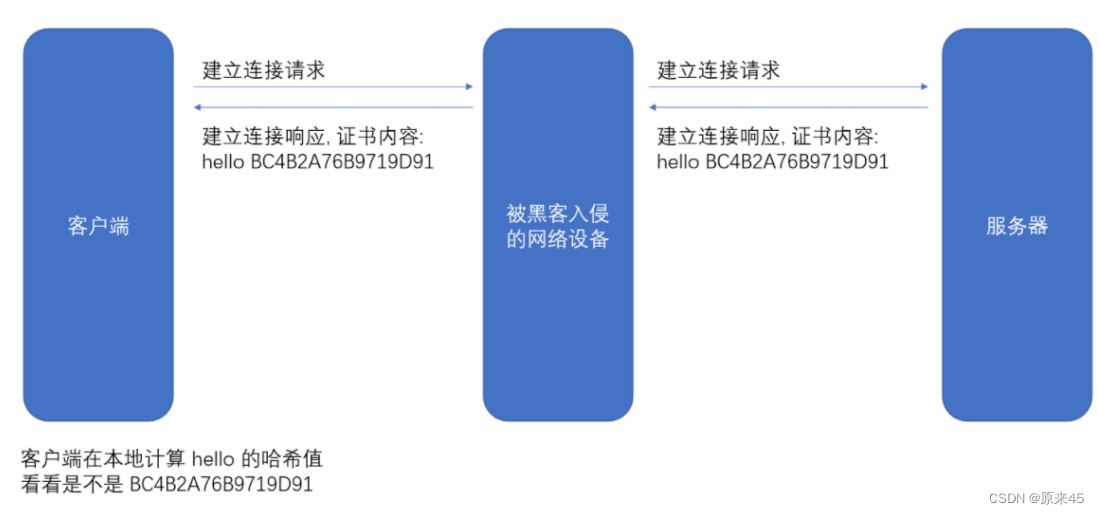
但是还有个问题, 如果⿊客把 hello 篡改了, 同时也把哈希值重新计算下, 客⼾端就分辨不出来了呀.
所以被传输的哈希值不能传输明⽂, 需要传输密⽂.
所以,对证书明⽂(这⾥就是“hello”)hash形成散列摘要,然后CA使⽤⾃⼰的私钥加密形成签名,将hello和加密的签名合起来形成CA证书,颁发给服务端,当客⼾端请求的时候,就发送给客⼾端,中间⼈截获了,因为没有CA私钥,就⽆法更改或者整体掉包,就能安全的证明,证书的合法性。最后,客⼾端通过操作系统⾥已经存的了的证书发布机构的公钥进⾏解密, 还原出原始的哈希值, 再进⾏校验。为什么签名不直接加密,⽽是要先hash形成摘要?
缩⼩签名密⽂的⻓度,加快数字签名的验证签名的运算速度如何成为中间⼈?
- ARP欺骗:在局域⽹中,hacker经过收到ARP Request⼴播包,能够偷听到其它节点的 (IP, MAC)地址。例, ⿊客收到两个主机A, B的地址,告诉B (受害者) ,⾃⼰是A,使得B在发送给A 的数据包都被⿊客截取。
- ICMP攻击:由于ICMP协议中有重定向的报⽂类型,那么我们就可以伪造⼀个ICMP信息然后发送给局域⽹中的客⼾端,并伪装⾃⼰是⼀个更好的路由通路。从⽽导致⽬标所有的上⽹流量都会发送到我们指定的接⼝上,达到和ARP欺骗同样的效果
- 假wifi && 假⽹站等。
完整流程
左侧都是客⼾端做的事情, 右侧都是服务器做的事情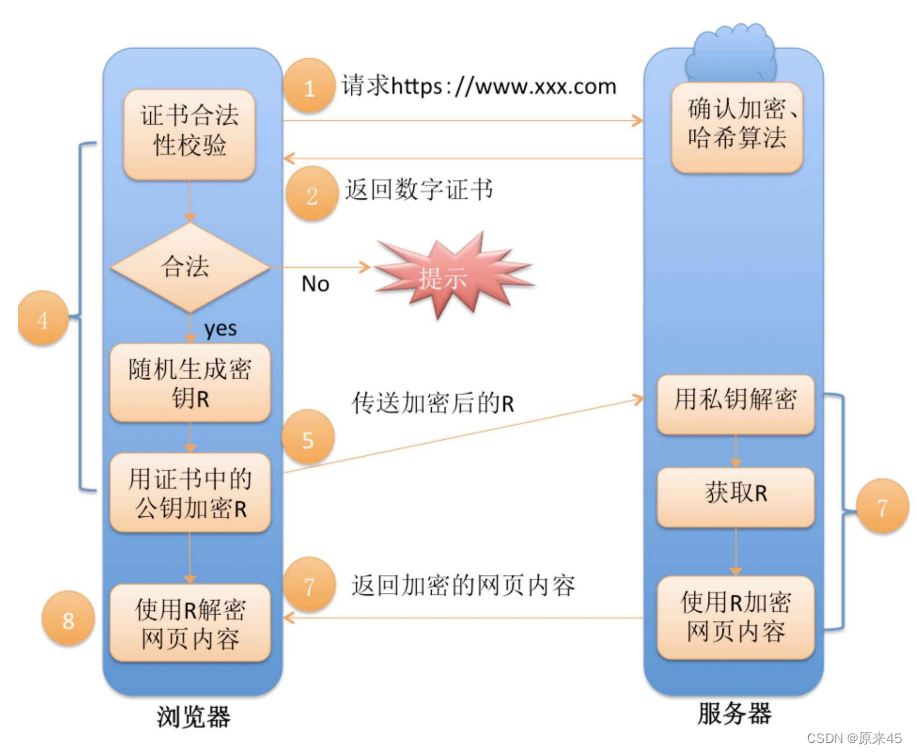
HTTPS ⼯作过程中涉及到的密钥有三组
第⼀组(⾮对称加密): ⽤于校验证书是否被篡改. 服务器持有私钥(私钥在形成CSR⽂件与申请证书时获得), 客⼾端持有公钥(操作系统包含了可信任的 CA 认证机构有哪些, 同时持有对应的公钥). 服务器在客⼾端请求是,返回携带签名的证书. 客⼾端通过这个公钥进⾏证书验证, 保证证书的合法性,进⼀步保证证书中携带的服务端公钥权威性。第⼆组(⾮对称加密): ⽤于协商⽣成对称加密的密钥. 客⼾端⽤收到的CA证书中的公钥(是可被信任的) 给随机⽣成的对称加密的密钥加密, 传输给服务器, 服务器通过私钥解密获取到对称加密密钥。第三组(对称加密): 客⼾端和服务器后续传输的数据都通过这个对称密钥加密解密。其实⼀切的关键都是围绕这个对称加密的密钥. 其他的机制都是辅助这个密钥⼯作的。第⼆组⾮对称加密的密钥是为了让客⼾端把这个对称密钥传给服务器.第⼀组⾮对称加密的密钥是为了让客⼾端拿到第⼆组⾮对称加密的公钥.


最后的最后,创作不易,希望读者三连支持💖
赠人玫瑰,手有余香💖