【GPT-SOVITS-02】GPT模块解析
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。
知乎专栏地址:
语音生成专栏
系列文章地址:
【GPT-SOVITS-01】源码梳理
【GPT-SOVITS-02】GPT模块解析
【GPT-SOVITS-03】SOVITS 模块-生成模型解析
【GPT-SOVITS-04】SOVITS 模块-鉴别模型解析
【GPT-SOVITS-05】SOVITS 模块-残差量化解析
【GPT-SOVITS-06】特征工程-HuBert原理
1.概述
GPT-SOVITS 的 GPT模块式实现从文本到语音编码的过程。
GPT-SOVITS 在原有的SOVITS入口加了一个残差量化层,参考Vall-E,这个量化层的输入是包含音频的文本特征和音色特征的。
AR模块的核心就是训练得到一个可以将文本转换成这个量化器输入的模型。核心代码主要在 AR包下 t2s_model.py 的 Text2SemanticDecoder类中。
训练特征包括:
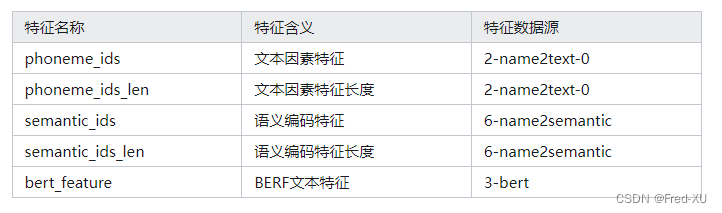
2.训练流程
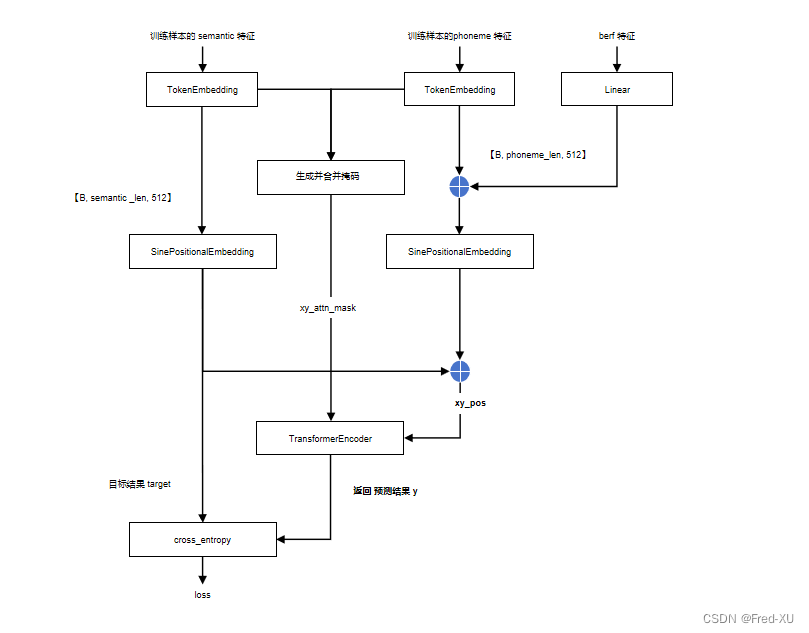
- 这里 semantic 是利用音频的 hubert 自编码信息SSL,进入 sovits
的残差量化层输出的结果,这个特征是包含文本以及音色特征 - phoneme 特征和berf特征是针对文本的音素特征,类似拼音
3.推理流程
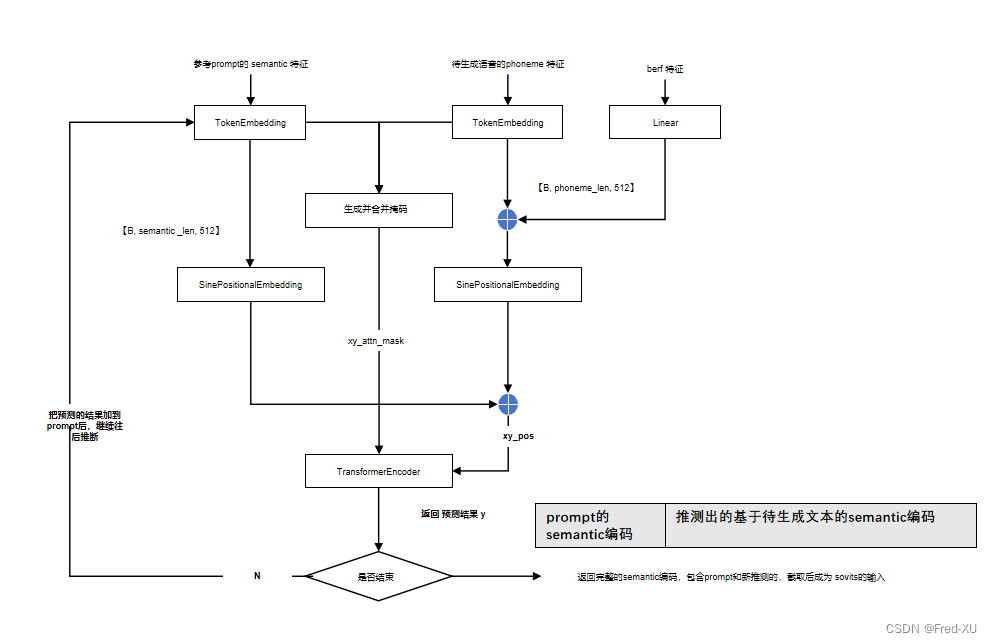
- 推理时,phoneme和berf用的是待生成的文本特征
- semantic 是参考音频生成的编码特征
- 推理时,以参考音频为起点,基于文本特征,逐次向后预测 semantic编码,直到结束
- 因此返回的结果相当于两段的拼接,因此直接截取即可
4.调试代码参考
import os,sys
import yaml,torch
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from vof.ar.model.t2s_model import Text2SemanticDecoder
from vof.ar.data.data_module import Text2SemanticDataModule
now_dir = os.getcwd()
root_dir = os.path.dirname(now_dir)
prj_name = 'project01' # 项目名称
prj_dir = root_dir + '/res/' + prj_name + '/'
with open(root_dir + '/res/configs/s1longer.yaml') as f:
data = f.read()
data = yaml.load(data, Loader=yaml.FullLoader)
s1_dir = prj_dir + 'logs'
os.makedirs("%s/logs_s1" % (s1_dir), exist_ok=True)
data["train"]["batch_size"] = 3
data["train"]["epochs"] = 15
data["pretrained_s1"] = root_dir + '/res/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt'
data["train"]["save_every_n_epoch"] = 5
data["train"]["if_save_every_weights"] = True
data["train"]["if_save_latest"] = True
data["train"]["exp_name"] = prj_name
data["train"]["half_weights_save_dir"] = root_dir + '/res/weight/gpt'
data["train_semantic_path"] = "%s/6-name2semantic.tsv" % s1_dir
data["train_phoneme_path"] = "%s/2-name2text-0.txt" % s1_dir
data["train_bert_path"] = "%s/3-bert" % s1_dir
data["output_dir"] = "%s/logs_s1" % s1_dir
Text2SemanticDataModule = Text2SemanticDataModule(
data,
train_semantic_path = data["train_semantic_path"],
train_phoneme_path = data["train_phoneme_path"],
train_bert_path = data["train_bert_path"])
Text2SemanticDataModule.setup()
print(Text2SemanticDataModule._train_dataset.__getitem__(0))
"""
phoneme_ids: 文本转换为音素后,继续转换为 音素的编码 对应 name2text
phoneme_ids_len:音素数据长度
semantic_ids:语音编码,对应 name2semantic
semantic_ids_len:语音编码数据长度
bert_feature:bert 文本特征
"""
t2smodel = Text2SemanticDecoder(data)
res = Text2SemanticDataModule._train_dataset.__getitem__(0)
phoneme_ids = res.get('phoneme_ids')
phoneme_ids_len = res.get('phoneme_ids_len')
semantic_ids = res.get('semantic_ids')
semantic_ids_len = res.get('semantic_ids_len')
bert_feature = res.get('bert_feature')
# 增加一个batch 维度
x = torch.LongTensor(phoneme_ids).unsqueeze(0)
x_len = torch.LongTensor([phoneme_ids_len])
y = torch.LongTensor(semantic_ids).unsqueeze(0)
y_len = torch.LongTensor([semantic_ids_len])
bert_feature = bert_feature.unsqueeze(0).float()
t2smodel.forward(x,x_len, y, y_len, bert_feature)