综合练习(python)
前言
有了前面的知识积累,我们这里做两个小练习,都要灵活运用前面的知识。
First
需求
根据美国/英国各自YouTube的数据,绘制出各自的评论数量的直方图
第一版
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rc("font",family="FangSong")
# 文件的路径
us_file_path="./youtube_video_data/US_video_data_numbers.csv"
uk_file_path="./youtube_video_data/GB_video_data_numbers.csv"
# 读取文件
t_us=np.loadtxt(us_file_path,delimiter=',',dtype='int')
t_uk=np.loadtxt(uk_file_path,delimiter=',',dtype='int')\
uk_comment = t_uk[:,-1]
d=50000
num = (uk_comment.max()-uk_comment.min())//d
plt.figure(figsize=(20,8),dpi=200)
plt.hist(uk_comment,num)
plt.show()
很明显,这里很多评论都是小于5000甚至3000,很多区间都没什么数据。所以我们要修改,只统计小于3000的数据。
第二版
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rc("font",family="FangSong")
# 文件的路径
us_file_path="./youtube_video_data/US_video_data_numbers.csv"
uk_file_path="./youtube_video_data/GB_video_data_numbers.csv"
# 读取文件
t_us=np.loadtxt(us_file_path,delimiter=',',dtype='int')
t_uk=np.loadtxt(uk_file_path,delimiter=',',dtype='int')
uk_comment = t_uk[:,-1]
temp_uk_comment = uk_comment[uk_comment<3000]
d=300
num = (temp_uk_comment.max()-temp_uk_comment.min())//d
plt.figure(figsize=(20,8),dpi=200)
plt.title("英国YouTube评论分布直方图")
plt.xlabel("评论数")
plt.hist(temp_uk_comment,num)
plt.show()
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rc("font",family="FangSong")
# 文件的路径
us_file_path="./youtube_video_data/US_video_data_numbers.csv"
uk_file_path="./youtube_video_data/GB_video_data_numbers.csv"
# 读取文件
t_us=np.loadtxt(us_file_path,delimiter=',',dtype='int')
t_uk=np.loadtxt(uk_file_path,delimiter=',',dtype='int')
us_comment = t_us[:,-1]
temp_us_comment = us_comment[us_comment<3000]
d=300
num = (temp_us_comment.max()-temp_us_comment.min())//d
plt.figure(figsize=(20,8),dpi=200)
plt.title("美国YouTube评论分布直方图")
plt.xlabel("评论数")
plt.hist(temp_us_comment,num)
plt.show()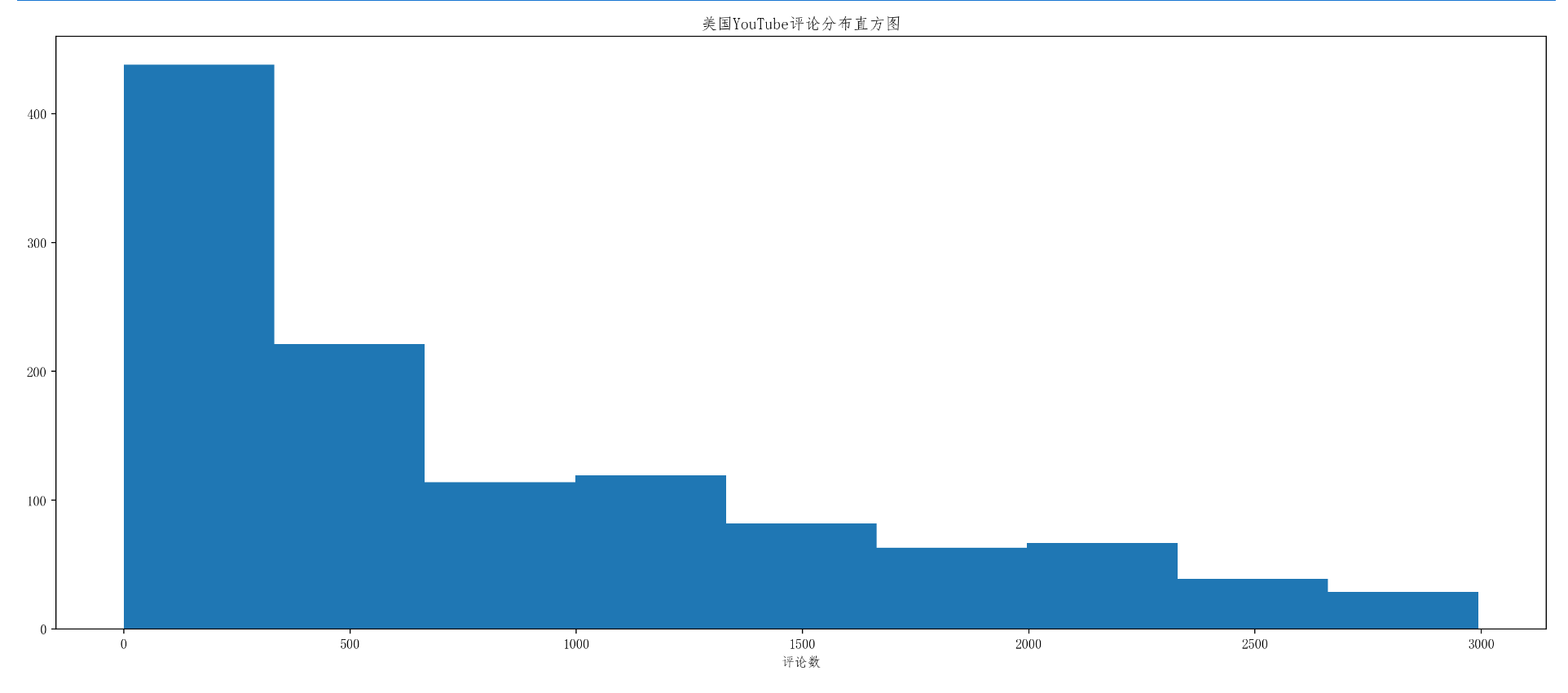
Second
需求
绘制图形来了解英国的YouTube中视频评论和喜欢数的关系.
第一版
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rc("font",family="FangSong")
# 文件的路径
us_file_path="./youtube_video_data/US_video_data_numbers.csv"
uk_file_path="./youtube_video_data/GB_video_data_numbers.csv"
# 读取文件
t_us=np.loadtxt(us_file_path,delimiter=',',dtype='int')
t_uk=np.loadtxt(uk_file_path,delimiter=',',dtype='int')
uk_like = t_uk[:,1]
uk_comment=t_uk[:,-1]
plt.figure(figsize=(20,8),dpi=200)
plt.scatter(uk_comment,uk_like)
plt.show()
很明显,数据分布在0-3000太密集了,而在>3000的部分分布的太稀疏了,所以我们就要调整。
但是,这次和上面的有点一些不一样,不能直接对uk_like或者uk_comment切片,因为我们画的是散点图,两种变量的要一一对应。所以我们只能对原数据t_uk进行切片。
第二版
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rc("font",family="FangSong")
# 文件的路径
us_file_path="./youtube_video_data/US_video_data_numbers.csv"
uk_file_path="./youtube_video_data/GB_video_data_numbers.csv"
# 读取文件
t_us=np.loadtxt(us_file_path,delimiter=',',dtype='int')
t_uk=np.loadtxt(uk_file_path,delimiter=',',dtype='int')
temp_uk=t_uk[t_uk[:,-1]<3000]
temp_uk_comment=temp_uk[:,-1]
temp_uk_like=temp_uk[:,1]
plt.figure(figsize=(20,8),dpi=200)
plt.xlabel("评论")
plt.ylabel("点赞数")
plt.title("英国YouTube--点赞与评论的关系")
plt.scatter(temp_uk_comment,temp_uk_like)
plt.show()
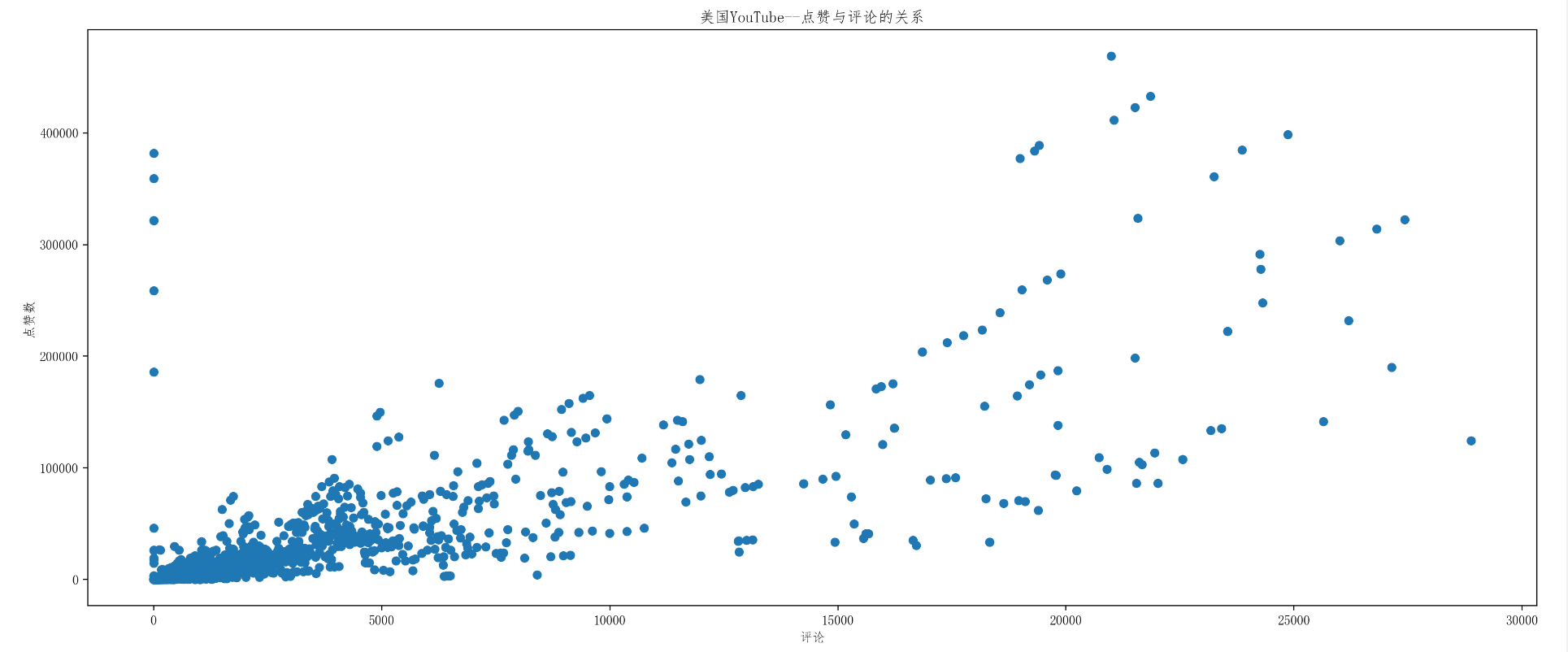
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rc("font",family="FangSong")
# 文件的路径
us_file_path="./youtube_video_data/US_video_data_numbers.csv"
uk_file_path="./youtube_video_data/GB_video_data_numbers.csv"
# 读取文件
t_us=np.loadtxt(us_file_path,delimiter=',',dtype='int')
t_uk=np.loadtxt(uk_file_path,delimiter=',',dtype='int')
temp_us=t_us[t_us[:,-1]<30000]
temp_us_comment=temp_us[:,-1]
temp_us_like=temp_us[:,1]
print(temp_uk_comment,temp_uk_like)
plt.figure(figsize=(20,8),dpi=200)
plt.xlabel("评论")
plt.ylabel("点赞数")
plt.title("美国YouTube--点赞与评论的关系")
plt.scatter(temp_us_comment,temp_us_like)
plt.show()