MySQL索引-聚簇索引和非聚簇索引
MySQL的InnoDB索引数据结构是B+树,主键索引叶子节点的值存储的就是MySQL的数据行,普通索引的叶子节点的值存储的是主键值,这是了解聚簇索引和非聚簇索引的前提
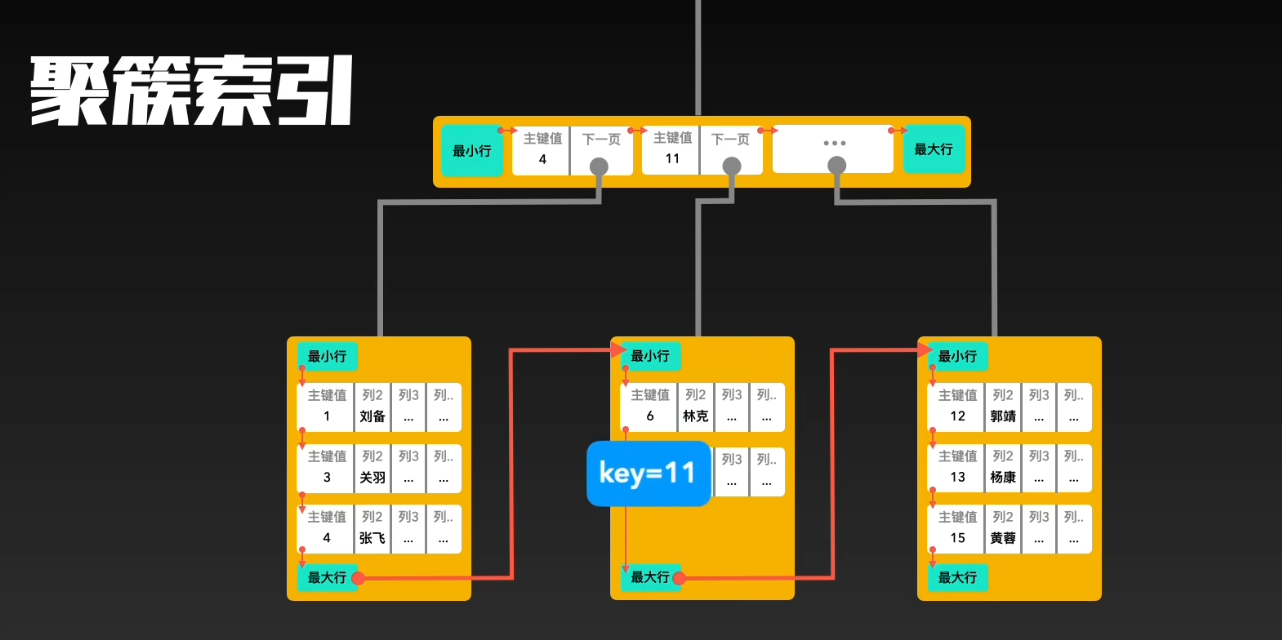
什么是聚簇索引?
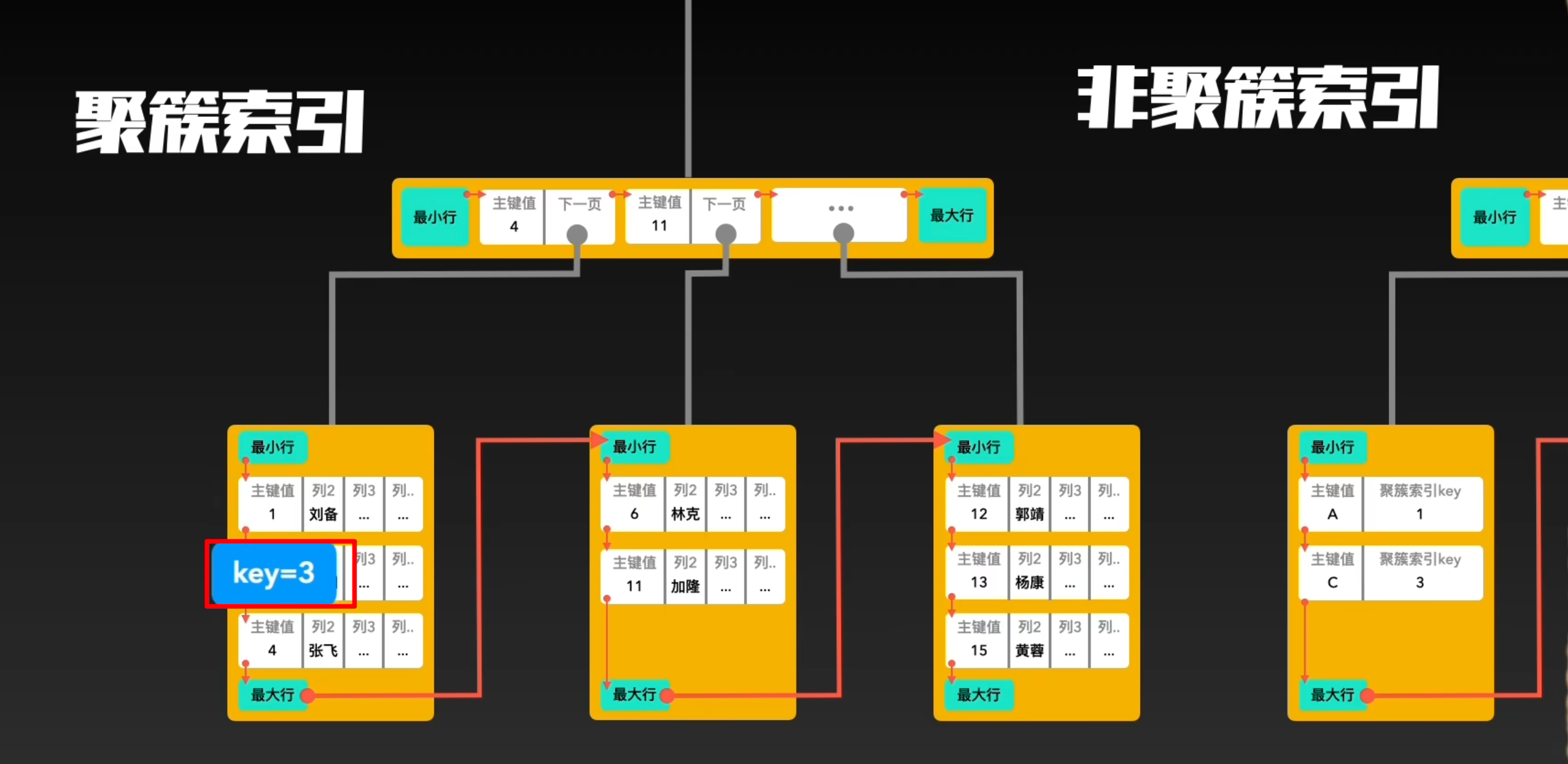
很简单记住一句话:找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键。
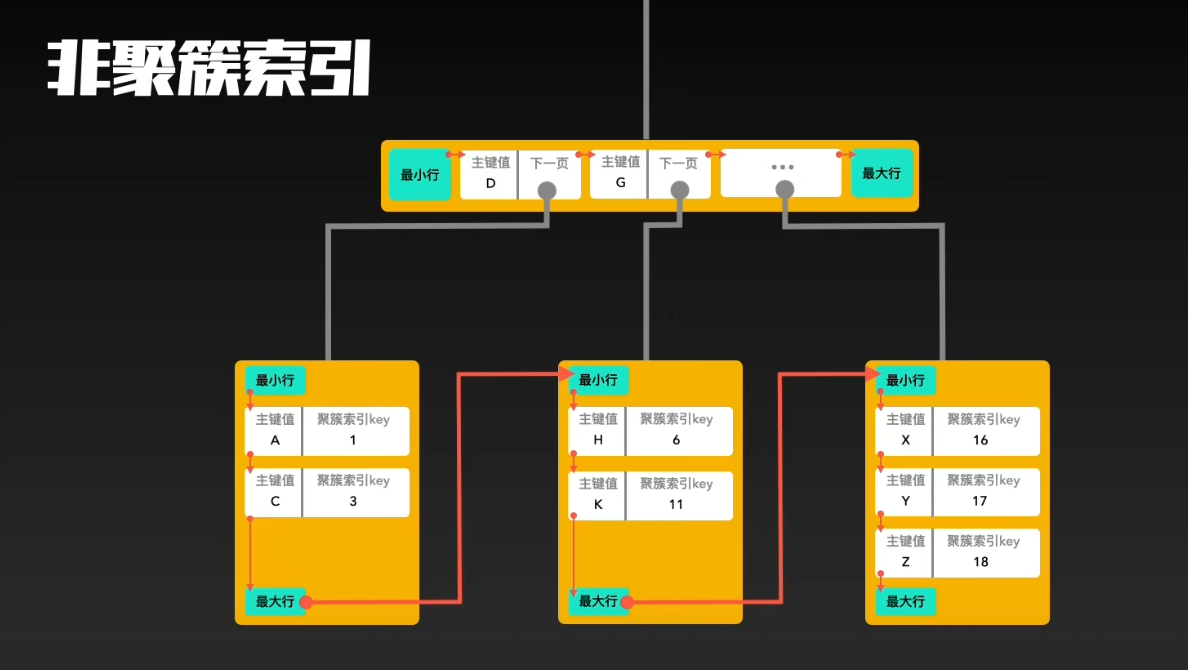
什么是非聚簇索引?
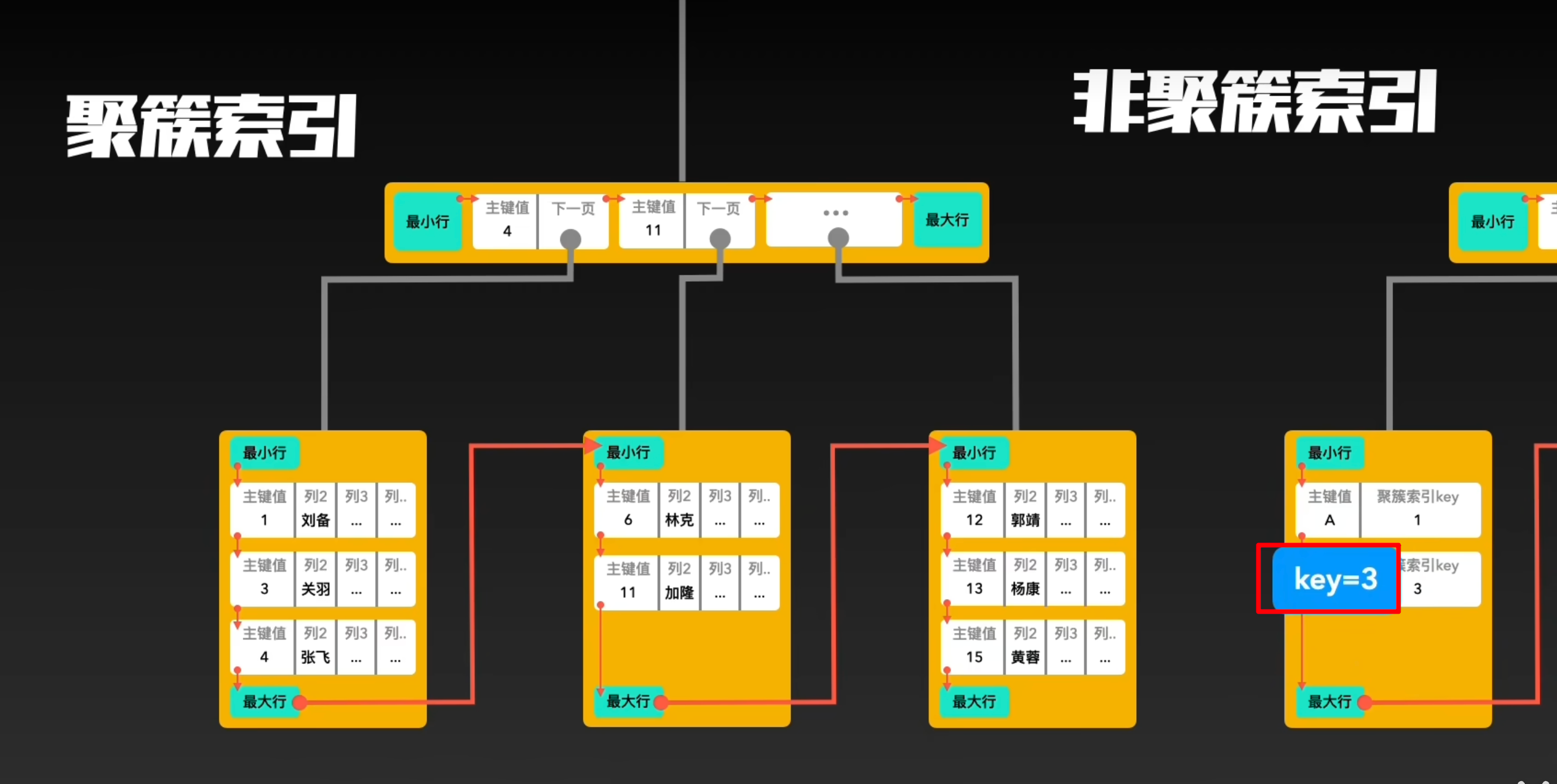
索引的存储和数据的存储是分离的,也就是说找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。
clustered index(MySQL官方对聚簇索引的解释)
The InnoDB term for a primary key index. InnoDB table storage is organized based on the values of the primary key columns, to speed up queries and sorts involving the primary key columns. For best performance, choose the primary key columns carefully based on the most performance-critical queries. Because modifying the columns of the clustered index is an expensive operation, choose primary columns that are rarely or never updated.
注意标黑的那段话,聚簇索引就是主键的一种术语
一、聚簇索引
定义与存储结构
- 聚簇索引也称为主键索引,它是一种按照数据的物理存储顺序来组织的索引。在 InnoDB 存储引擎中,表的数据行实际上是存储在聚簇索引的叶子节点中。
- 这意味着,通过聚簇索引可以直接定位到表中的数据行,而不需要进行额外的查找。
特点与优势
- 数据访问高效:由于数据和索引存储在一起,聚簇索引对于主键的查询和范围查询非常高效。一旦找到了索引,就可以直接获取到对应的数据行,减少了磁盘 I/O 操作。
- 插入和更新的顺序性:如果插入和更新操作是按照聚簇索引的顺序进行的,那么可以提高数据的存储效率。因为数据的存储位置相对固定,不需要频繁地移动数据。
限制与注意事项
- 一个表只能有一个聚簇索引:通常情况下,表的主键会自动成为聚簇索引。如果表没有明确指定主键,InnoDB 会尝试选择一个唯一且非空的索引作为聚簇索引。如果找不到合适的唯一索引,InnoDB 会隐式地创建一个内部的唯一标识符来作为聚簇索引。
- 修改聚簇索引成本高:修改聚簇索引实际上就是修改主键,这可能会涉及到大量的数据移动和索引重建,成本较高。
二、非聚簇索引
定义与存储结构
- 非聚簇索引也称为辅助索引,它是一种独立于数据存储的索引结构。在非聚簇索引中,叶子节点存储的是索引列的值和对应的主键值。
- 通过非聚簇索引进行查询时,首先找到索引,但是此时并没有找到实际的数据,而是需要根据索引上存储的主键值再次进行回表查询,通过主键值在聚簇索引中找到对应的数据行。
特点与优势
- 提高特定查询性能:非聚簇索引可以提高特定查询的性能。例如,对于经常基于非主键列进行查询的场景,可以创建非聚簇索引来加速查询。
- 减少对聚簇索引的影响:对于频繁更新的列,可以创建非聚簇索引,避免对聚簇索引的频繁修改,从而提高性能。
限制与注意事项
- 回表查询的开销:由于非聚簇索引需要进行回表查询,因此在查询性能上可能不如聚簇索引。特别是在大量数据的情况下,回表查询可能会导致较多的磁盘 I/O 操作。
- 存储成本增加:非聚簇索引需要额外的存储空间来存储索引列的值和主键值,增加了存储成本。