「数据科学」清洗数据,真实数据集中缺失值的查看与处理
在数据科学的工作过程中,我们通过查看数据的基本要素和元数据之后,需要根据查看的结果,考虑是否需要清洗数据。缺失值的查看与处理,就是清洗数据的一部分。如果我们的数据集中,存在缺失值的话,就需要考虑如何处理缺失值。
缺失数据的产生
那么,缺失值是怎么产生的呢?
在我们收集数据的过程中,不管是通过手工收集,还是通过信息系统,录入数据的方式收集。可能会存在两种产生缺失值的情况,一种就是人为原因,导致数据没有录入,或者是没有收集到,形成缺失值。另外一种,可能是汇总组合数据的时候,由于算法设计的问题,或者是系统处理数据环节存在问题,也可能导致产生缺失值。
查看缺失数据
我们先来看,在我们的原始数据集中,如何来查看是否存在缺失值。
先导入必要的包,设置数据集,行和列显示的数目。
这里,我们通过ucimlrepo库的fetch_ucirepo函数,获取bank_marketing的真实数据集。
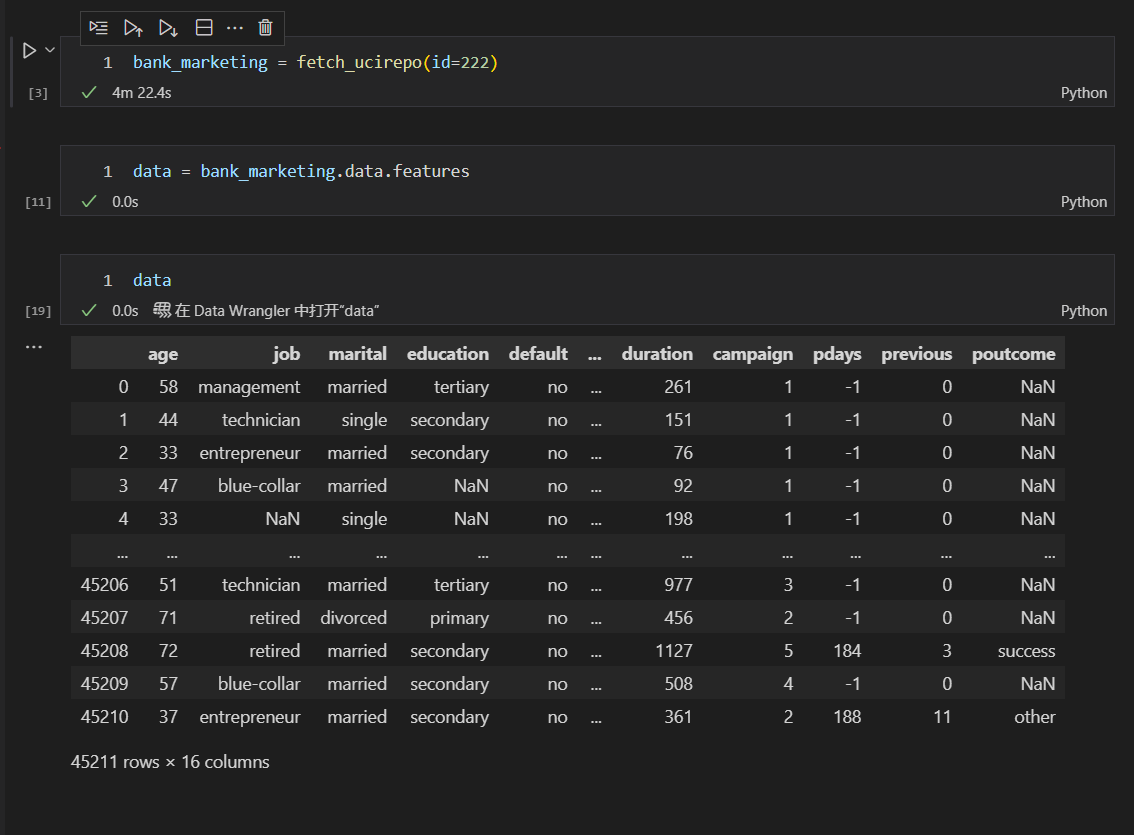
bank_marketing数据集,是葡萄牙一家银行机构的直接营销活动数据,营销活动是基于电话实现的。用来预测银行客户,是否会订阅银行产品(定期存款)。
从上图可以大致看出,有NaN的列,就是存在缺失值的变量。
我们还可以通过isnull函数,查看数据集的所有变量的缺失值情况,通过sum聚合函数,汇总存在缺失值变量的数据总数。

为0的变量,是不存在缺失值的变量。不为0的变量,则是存在缺失值的变量,需要考虑处理缺失值。
处理缺失数据
处理缺失数据的方式,一种是直接丢弃存在缺失值的行,一种是填充缺失值所在的单元格数据。
我们先来看直接丢弃存在缺失值的行。为了不影响原始数据集,我们复制一个新数据集data1。

通过dropna函数,直接丢弃存在缺失值的行。可以看出,操作完成后,数据从45211行,减少到了7842行。
这里,我还可以给dropna函数加上参数,来对整行都是缺失值的行,进行丢弃,语句如下所示。
df.dropna(how='all')
对整列都是缺失值的列,进行丢弃的话,语句如下所示。
df.dropna(how='all', axis=1)
我们再来看,如何填充缺失值数据。当具体的单元格中的缺失值数据,我们在现实中,找到合适的值的话,就可以直接填充缺失值数据。
我们可以对整个数据集,用0来填充缺失值。

这样,缺失值的地方,就用0进行了替代。
我们也可以考虑用缺失值前面或后面的值来填充。
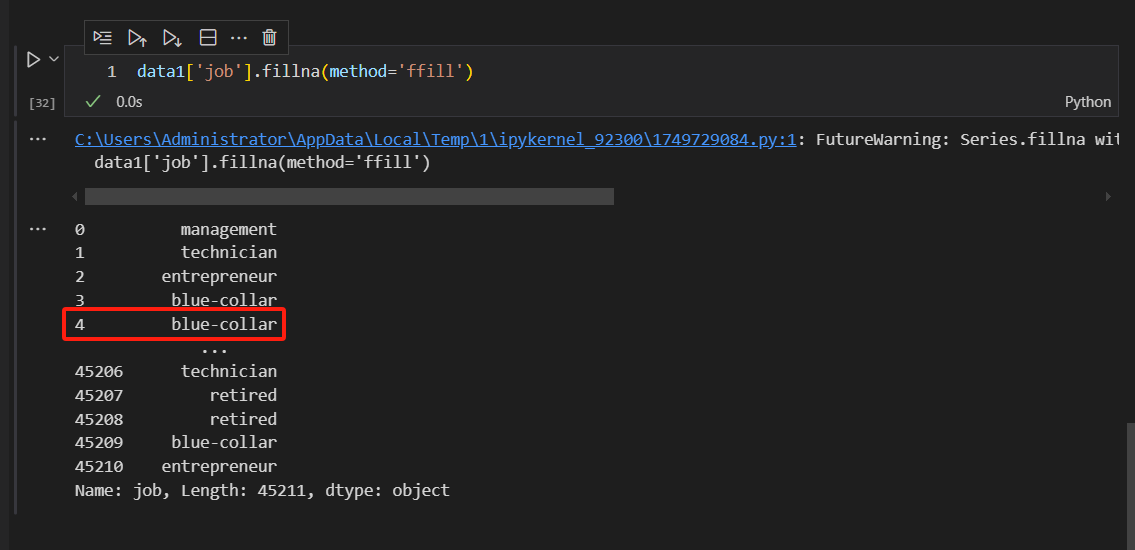
如果是用后面的值进行填充的话,语句如下所示。
data1['job'].fillna(method='bfill')
如果要对某个单元格进行填充的话,只要查询到这个单元格,然后对这个单元格进行赋值操作,就可以填充新的数据值。

缺失值的填充,在现实的数据清洗过程中,用处非常大。我们收集到的数据,往往需要反复修改,不管是对缺失值的处理,还是对其他异常情况的处理,都需要用到缺失值填充的操作。
以上就是本篇文章的全部内容。