【linux】基础IO(上)

1. 共识原理
- 文件 = 内容 + 属性
- 文件分为 打开的文件 + 没打开的文件
- 打开的文件 : 是进程打开的 ----- 本质是要研究文件和进程的关系
- 没打开的文件 : 没打开的文件储存在磁盘上,由于没打开的文件很多,所以需要分门别类的防止好,才能快速找到文件
- 文件被打开,必须先加载到内存
- 进程打开文件的比例是按 1 : 多进行的,所以在操作系统内部,一定存在大量被打开的文件,我们需要去管理 ----------- 先描述再组织 ----------- 在内核中,一个被打开的文件都需要自己的文件打开对象,包含文件的很多属性
- C语言程序默认在启动的时候,会打开三个标准输入输出流(文件)
stdin : 键盘文件
stdout : 显示器文件
stderr : 显示器文件
- 文件在磁盘上,磁盘是外部设备,访问磁盘文件其实是访问硬件
- 几乎所有的库只要是访问硬件设备,必要封装系统调用 (如 fwirte , fprintf , fread)
2. 系统文件I/O
操作文件,除了上述C接口(当然,C++也有接口,其他语言也有),我们还可以采用系统接口来进行文件访问
注意:(有关C接口的一些IO流知识)
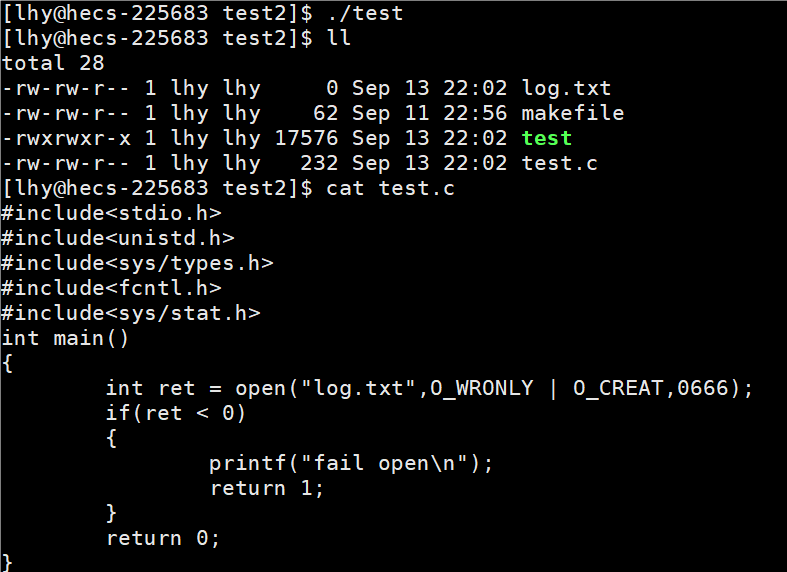
- C语言的 fopen 第一个参数如果只传文件名,如果没有该文件,则在当前进程的工作路径下 cwd 创建一个文件
- fopen 第二次参数如果是 w : 写入之前,都会对文件进行清空,再从头开始写入, a : 是在原内容后面追加写
代码举例
3. 接口介绍
open :
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname: 要打开或创建的目标文件
flags:
打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags
O_RDONLY: 只读打开 , O_WRONLY: 只写打开(只有这个选项,写入是覆盖写) , O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND: 追加写
O_TRUNC : 先清空文件内的内容
mode:
决定新文件的访问权限
返回值:
成功:新打开的文件描述符
失败:-1
注意:
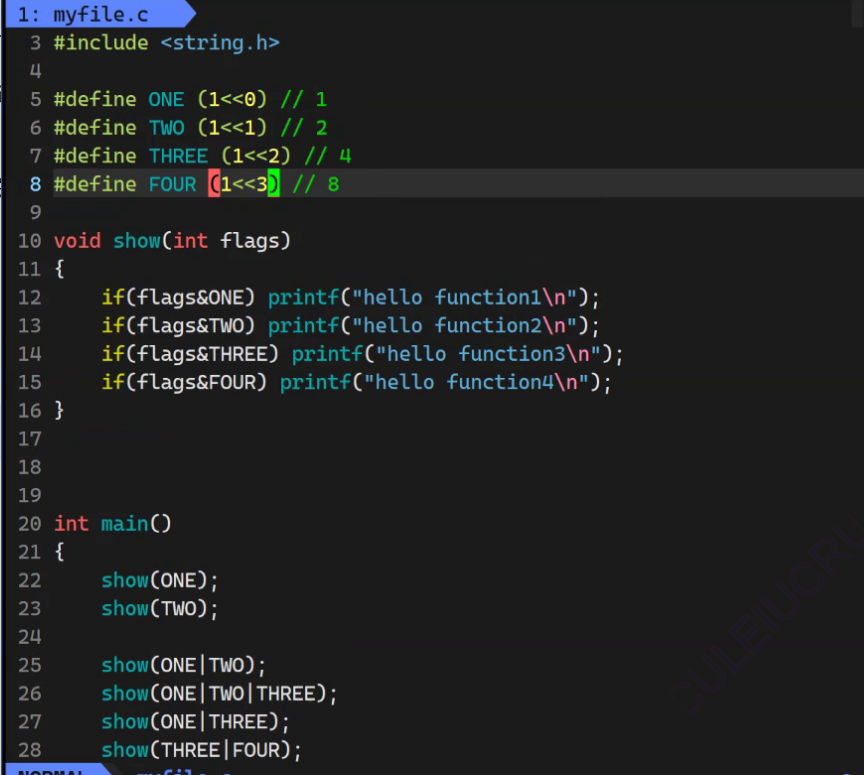
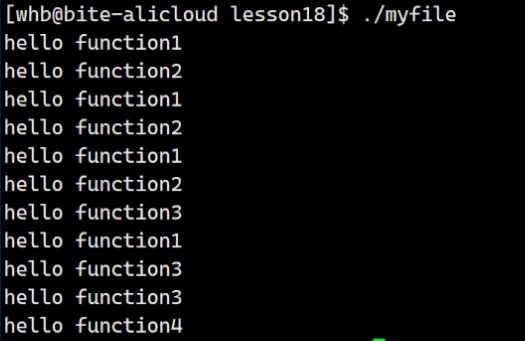
- flags 实际上是运用了比特位方式的标志位传递方式(大致类似以下)
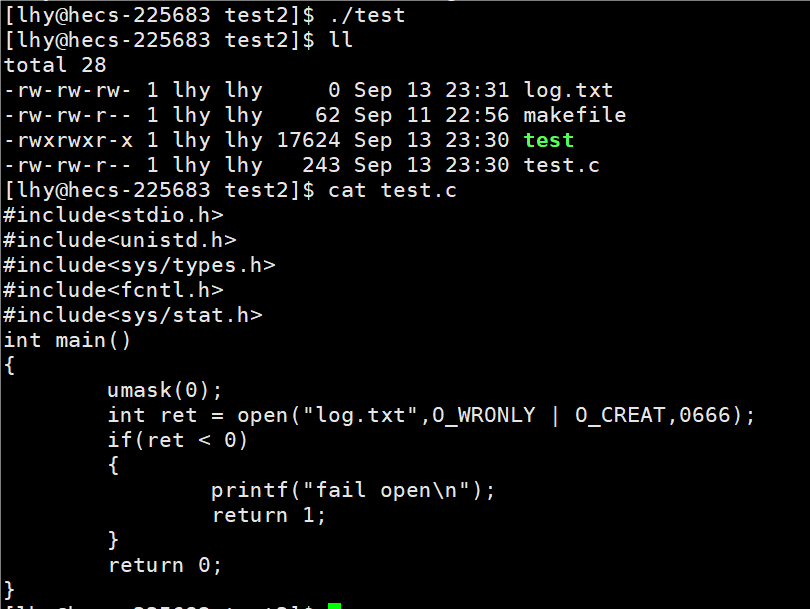
- mode 参数可以决定文件访问权限,但是这是起始权限,最终权限跟 umask有关,如果想要最终权限等于起始权限,进程内部调用 umask(0) , 虽然有系统内部的 umask,但是这里会采用进程里面设置的umask
4. 文件标识符fd
(一)认识文件标识符
我们先来认识一下两个概念: 系统调用 和 库函数
像 fopen fclose fread fwrite 都是C标准库当中的函数,我们称之为库函数
而 open close read write lseek 都属于系统提供的接口,称之为系统调用接口
实际上,上述的库函数是封装了这些系统调用接口 ,而C语言里的File是一个结构体,由于要封装系统调用接口,这个结构体里面一定要存的信息是文件描述符 fd (其他语言也是如此)
由于文件需要被管理起来,所以我们对其先描述,再组织

(二)文件描述符 0 ,1 , 2
Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2.
fd 0,1,2对应的物理设备一般是:键盘,显示器,显示器
代码 验证 fd = 1 fd = 2对应的文件
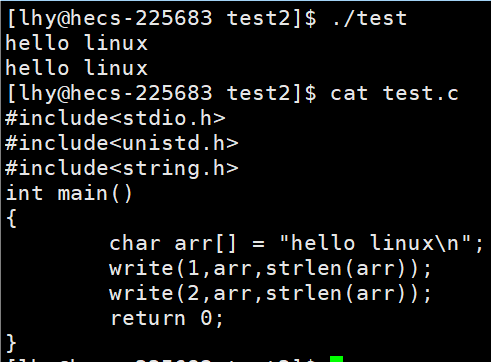
注意
关闭 标准输出1 不影响 标准错误2,即使是不同的fd,也可鞥是同一个被打开的文件,这里实际上用到了计数引用(智能指针有提到),即当关闭其中一个,count--,文件描述表里面的指针数组,相应下标对应的内容置空即可,只有当 count = 0 , 这个文件才不被打开
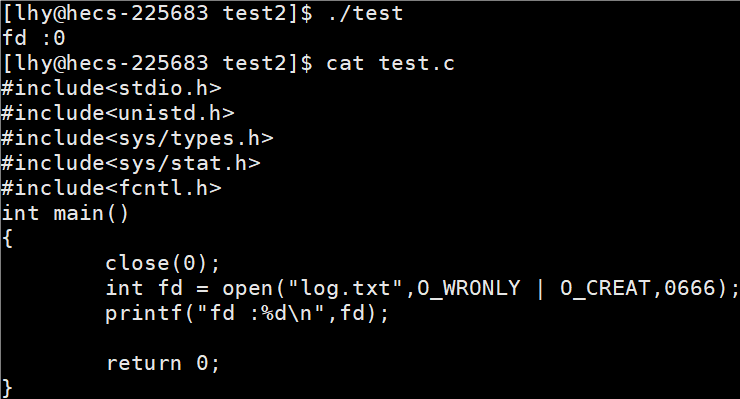
(三)文件描述符的分配规则
在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符
代码举例
5. 重定向
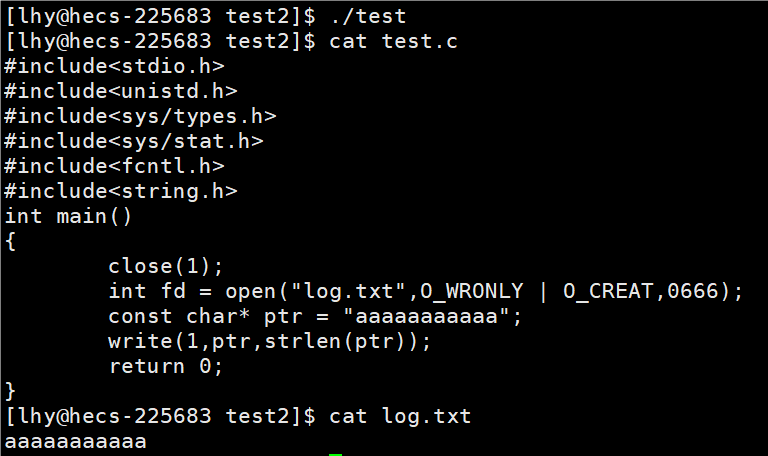
重定向的原理和上述差不多
注意:
进程历史打开的文件与进行的各种重定向关系都和未来进行程序替换无关,程序替换,并不影响文件访问
6. 使用 dup2 系统调用
#include <unistd.h>
int dup2(int oldfd, int newfd);
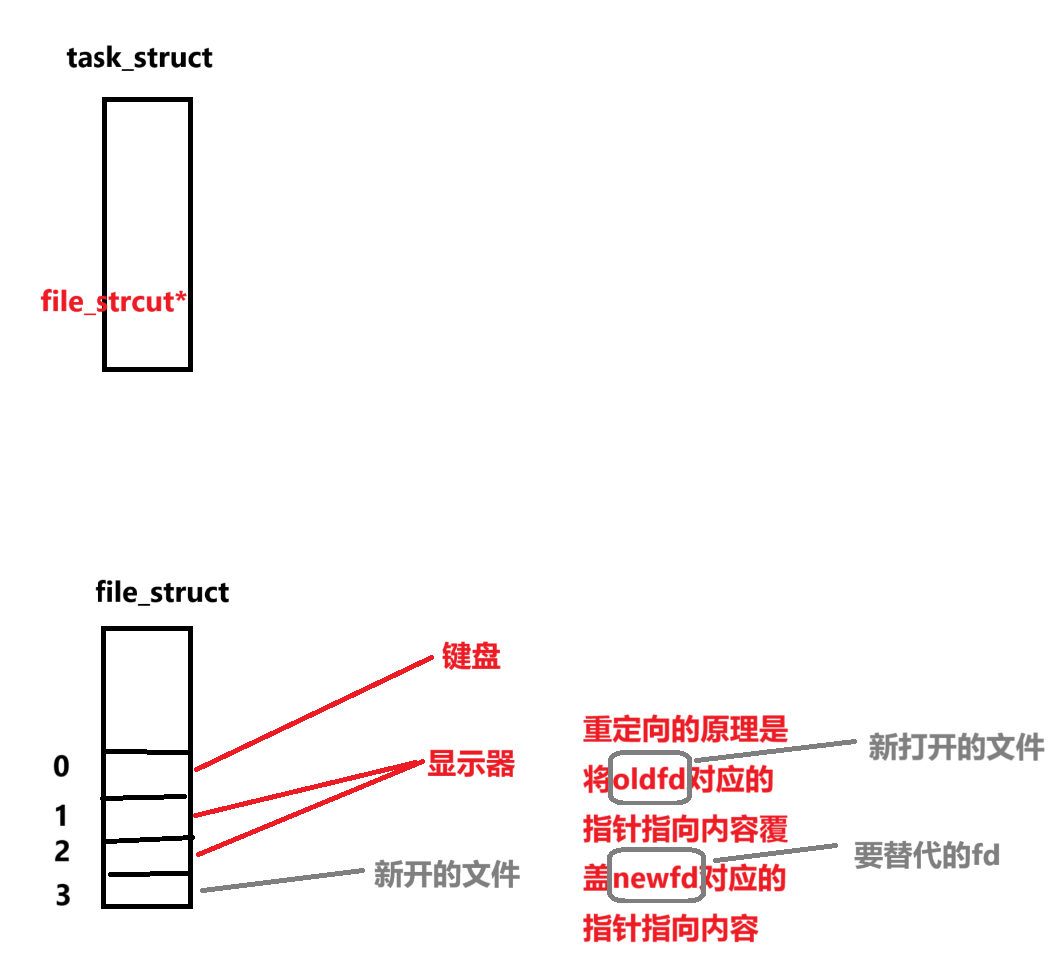
代码举例1
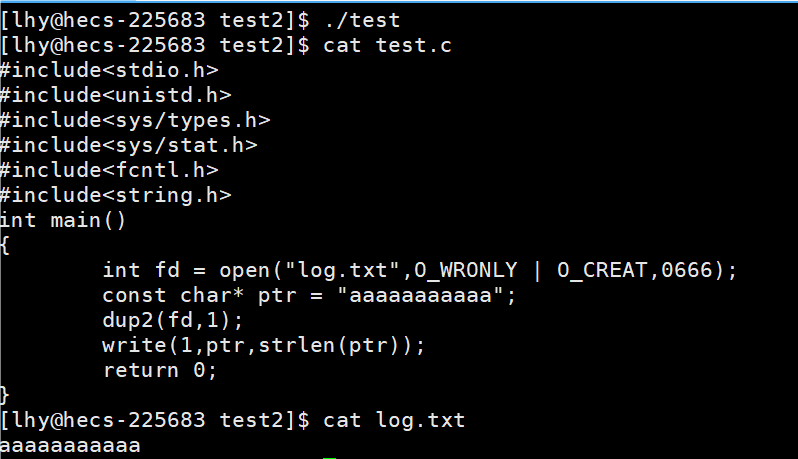
dup2(fd,1)
将fd文件描述所指向的内容覆盖到1文件描述所指向的内容
7. FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访
问的
FILE结构体里面还有对应打开文件的缓冲区和维护信息
所以C库当中的FILE结构体内部,必定封装了fd
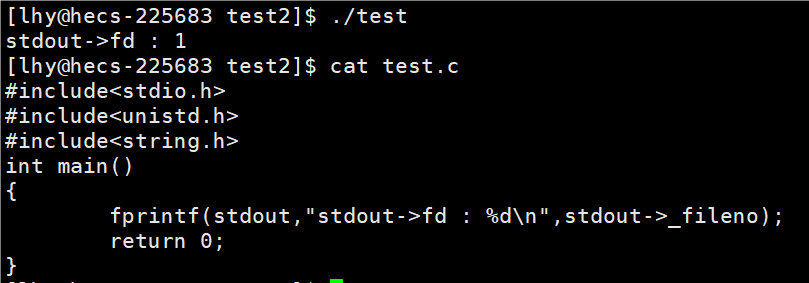
代码 验证File结构体中有 fd
代码(必看,有关缓冲区)
代码一
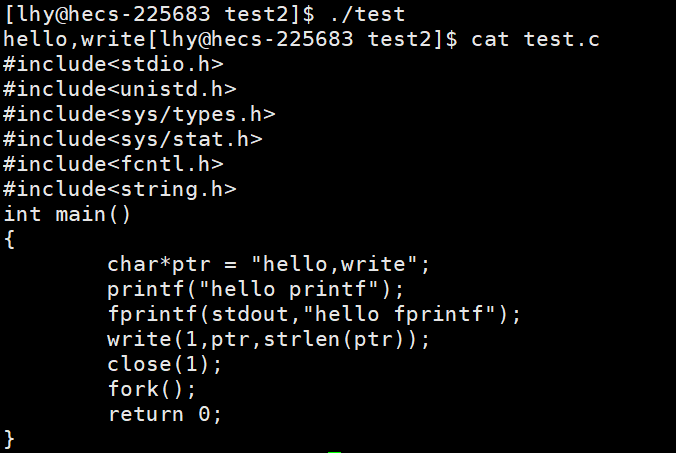
首先,我们先理解一下缓冲区
printf , fprintf 这些都是库函数,属于C语言提供的,且它们都需要将数据放到缓冲区内(这个缓冲区指代的是C语言提供的缓冲区,每一个进程都有自己的一个缓冲区),对于显示器采取的一般是行缓冲,即碰到 '\n',才把数据刷新到系统提供的缓冲区,最后交给磁盘
write 是属于系统调用接口的函数,调入时,将数据写入系统提供的缓冲区
代码二
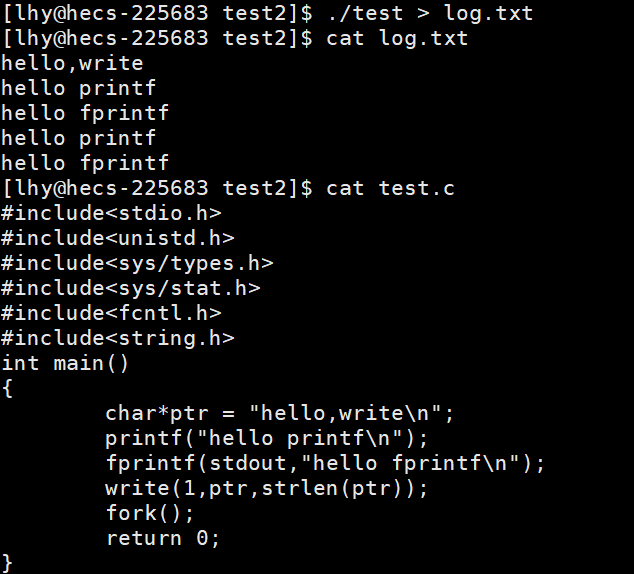
对文件采取的一般是全缓冲,即C语言提供的缓冲区满了,才刷新到系统提供的缓冲区
所以 printf,fprintf写入的数据只是放到C语言提供的缓冲区,并没有刷新,当进程退出时,需要刷新C语言提供的缓冲区,这个时候,无论父进程和子进程谁先退出,必然发生写实拷贝,从而造成printf,fprintf写入的内容,父子进程各有一份,且都要刷新
缓冲区刷新问题
三层刷新方式:
- 无缓冲 ----- 直接刷新
- 行缓冲 ----- 碰到'\n'刷新(一般对应显示器)
- 全缓冲 ----- 缓冲区满了才刷新 (一般对应普通文件写入)
还有一种情况,缓冲区也会刷新:
进程退出
为什么要有缓冲区:
- 解决效率问题
- 配合格式化(实际上的读取,都是当作字符来看待)
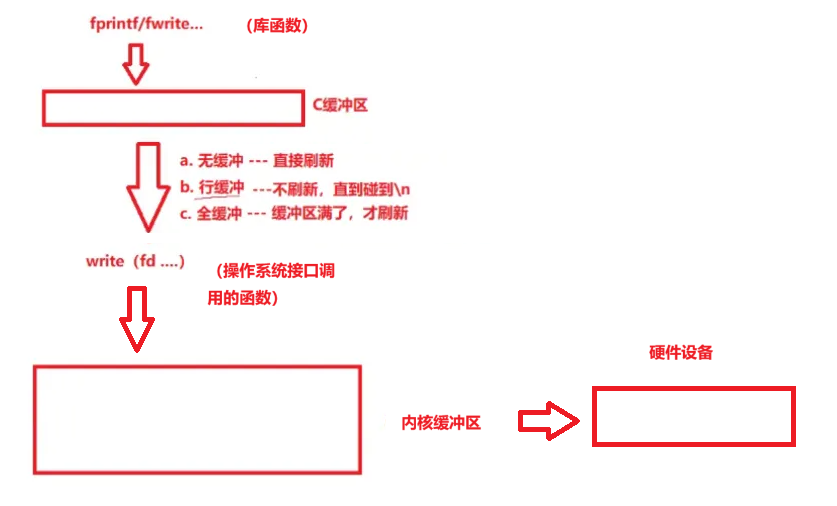
目前我们认为,只要将数据刷新到了内核,数据就可以到硬件了