探索 Web Speech API:实现浏览器语音识别与合成
引言
Web Speech API 是一项由 W3C 开发的 Web 标准,为开发者提供了在 Web 应用程序中实现语音识别和语音合成的能力。通过 Web Speech API,我们可以让网页与用户进行语音交互,实现更加智能化和便捷的用户体验。本文将深入探讨 Web Speech API 的原理、用法和实际应用,帮助开发者了解如何利用这一技术为自己的 Web 应用增添语音功能。
一、Web Speech API 的概述
Web Speech API 是一组用于实现语音识别和语音合成的 JavaScript 接口,包括 SpeechRecognition 和 SpeechSynthesis 两个主要接口。SpeechRecognition 接口用于实现语音识别,让浏览器可以识别用户的语音输入;SpeechSynthesis 接口用于实现语音合成,允许浏览器生成人工语音。
二、使用 SpeechRecognition 实现语音识别
-
初始化 SpeechRecognition 对象:通过创建
SpeechRecognition对象来初始化语音识别器。 -
设置识别参数:可以设置语言、连续识别与单次识别、识别回调等参数。
-
开始识别:调用
start()方法开始识别用户的语音输入。 -
处理识别结果:通过监听
result事件获取识别结果,并对识别的文本进行后续处理。
三、使用 SpeechSynthesis 实现语音合成
-
初始化 SpeechSynthesis 对象:通过创建
SpeechSynthesis对象来初始化语音合成器。 -
创建合成语音:
SpeechSynthesisUtterance对象来创建要合成的语音。 -
设置语音参数:可以设置语言、音调、音量、速率等语音参数。
-
播放语音:调用
speak()方法开始播放合成的语音。
四、实际应用场景
-
语音搜索:实现网页的语音搜索功能,让用户通过语音口令来进行检索。
-
语音交互:创建具有语音导航和语音提示的网页应用,提升用户体验。
-
语音输入:实现语音转文字输入框,让用户可以通过语音输入文本。
Web Speech API 提供了将语音合成和语音识别添加到 Web 应用程序的功能。使用此 API,我们将能够向 Web 应用程序发出语音命令,就像在 Android 上通过其 Google Speech 或在 Windows 中使用 Cortana 一样。
下面来看一个简单的例子,使用 Web Speech API 实现文字转语音和语音转文字:
<body>
<header>
<h2>Web APIs<h2>
</header>
<div class="web-api-cnt">
<div id="error" class="close"></div>
<div class="web-api-card">
<div class="web-api-card-head">
Demo - Text to Speech
</div>
<div class="web-api-card-body">
<div>
<input placeholder="Enter text here" type="text" id="textToSpeech" />
</div>
<div>
<button onclick="speak()">Tap to Speak</button>
</div>
</div>
</div>
<div class="web-api-card">
<div class="web-api-card-head">
Demo - Speech to Text
</div>
<div class="web-api-card-body">
<div>
<textarea placeholder="Text will appear here when you start speeaking." id="speechToText"></textarea>
</div>
<div>
<button onclick="tapToSpeak()">Tap and Speak into Mic</button>
</div>
</div>
</div>
</div>
</body>
<script>
try {
var speech = new SpeechSynthesisUtterance()
var SpeechRecognition = SpeechRecognition;
var recognition = new SpeechRecognition()
} catch(e) {
error.innerHTML = "此设备不支持 Web Speech API"
error.classList.remove("close")
}
function speak() {
speech.text = textToSpeech.value
speech.volume = 1
speech.rate=1
speech.pitch=1
window.speechSynthesis.speak(speech)
}
function tapToSpeak() {
recognition.onstart = function() { }
recognition.onresult = function(event) {
const curr = event.resultIndex
const transcript = event.results[curr][0].transcript
speechToText.value = transcript
}
recognition.onerror = function(ev) {
console.error(ev)
}
recognition.start()
}
</script>
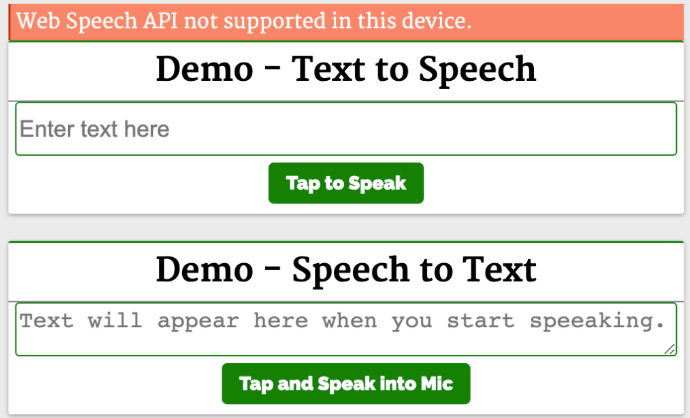
第一个演示 Demo - Text to Speech 演示了使用这个 API 和一个简单的输入字段,接收输入文本和一个按钮来执行语音操作。
function speak() {
const speech = new SpeechSynthesisUtterance();
speech.text = textToSpeech.value;
speech.volume = 1;
speech.rate = 1;
speech.pitch = 1;
window.speechSynthesis.speak(speech);
}
它实例化了 SpeechSynthesisUtterance() 对象,将文本设置为从输入框中输入的文本中朗读。然后,使用 speech 对象调用 SpeechSynthesis#speak 函数,在扬声器中说出输入框中的文本。
第二个演示 Demo - Speech to Text 将语音识别为文字。点击 Tap and Speak into Mic 按钮并对着麦克风说话,我们说的话会被翻译成文本输入框中的内容。
点击 Tap and Speak into Mic 按钮会调用 tapToSpeak 函数:
function tapToSpeak() {
var SpeechRecognition = SpeechRecognition;
const recognition = new SpeechRecognition();
recognition.onstart = function () {};
recognition.onresult = function (event) {
const curr = event.resultIndex;
const transcript = event.results[curr][0].transcript;
speechToText.value = transcript;
};
recognition.onerror = function (ev) {
console.error(ev);
};
recognition.start();
}
这里实例化了 SpeechRecognition,然后注册事件处理程序和回调。语音识别开始时调用 onstart,发生错误时调用 onerror。每当语音识别捕获一条线时,就会调用 onresult。
在 onresult 回调中,提取内容并将它们设置到 textarea 中。因此,当我们对着麦克风说话时,文字会出现在 textarea 内容中。
五、Web Speech API 的兼容性与注意事项
-
兼容性:Web Speech API 在现代浏览器(如 Chrome、Firefox)中得到广泛支持,但在一些旧版本浏览器上可能会有兼容性问题。
-
隐私考虑:使用语音别和合成功能时,要注意用户隐私和数据安全,避免敏感信息泄露。
结语
Web Speech API 为开发者提供了强大的语音识别和语音合成能力,可以为 Web 应用增添智能化和便捷的用户交互。本文深入探讨了 Web Speech API 的概述、使用方法和实际应用场景,希望可以帮助开发者更好地利用这一技术。随着 Web 技术的不断发展,语音交互将会成为未来 Web 应用的重要趋势之一。
参考资料
-
MDN 文档: https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Speech_API
