Kafka 面试题
参考:
- https://javabetter.cn/interview/kafka-40.html
- https://javaguide.cn/high-performance/message-queue/kafka-questions-01.html
Kafka 架构

名词概念
-
Producer(生产者) : 产生消息的一方。
-
Consumer(消费者) : 消费消息的一方。
-
Broker(代理) : 可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个 Kafka Cluster。
-
Topic(主题) : Producer 将消息发送到特定的主题,Consumer 通过订阅特定的 Topic(主题) 来消费消息。同一 Topic 下的 Partition 可以分布在不同的 Broker 上。
-
Partition(分区) : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition 。
Kafka 中的 Partition(分区) 实际上可以对应成为消息队列中的队列。

-
zookeeper在 Kafka 中的作用?
-
Broker 注册:在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到
/brokers/ids下创建属于自己的节点。 -
Topic 注册:在 Kafka 中,同一个Topic 的消息会被分成多个分区并将其分布在多个 Broker 上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。
比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:
/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1。 -
负载均衡:上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition,各个 Partition 可以分布在不同的 Broker(Kafka实例)上**。对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上**。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
Kafka 中可以不要 zookeeper 吗?
答:可以,在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构,让你可以以一种轻量级的方式来使用 Kafka。
Kafka 的消息模型?知道队列模型吗?
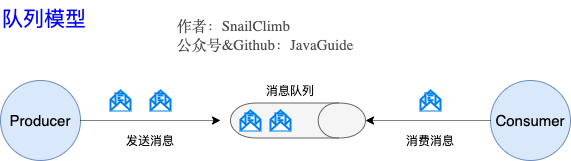
1、早期的消息模型:队列模型。使用队列(Queue)作为消息通信载体,满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。存在的问题:
- 不能将一条消息发送给多个消费者。
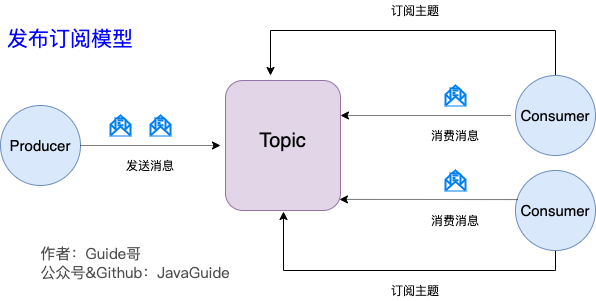
2、Kafka 消息模型:发布-订阅模式。这种模式可以让一条消息发送给多个消费者。
- 发布订阅模型(Pub-Sub) 使用主题(Topic) 作为消息通信载体,类似于广播模式;
- 发布者发布一条消息,该消息通过主题传递给所有的订阅者。(在一条消息广播之后才订阅的用户则是收不到该条消息的)
Kafka 多副本机制
Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。
- 我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。
- 生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
Kafka 用途
Kafka 是一个分布式流式处理平台。流平台具有三个关键功能:
-
消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
-
容错的持久方式存储记录消息流:Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
-
流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库,可以实时处理数据。
例如,一个传感器的数据被消费者读取后可以进行处理。比如:,可以进行过滤、转换、聚合、窗口操作等。在检测异常情况的场景中,可能会对传感器数据进行实时分析,比如检查温度是否超过某个阈值、压力是否突然变化等。
Kafka 优势(与 其他消息中间件对比)
Kafka 与 RocketMQ、RabbitMQ 对比。Kafka 具有哪些优势:
- 极致的性能:基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
- 生态系统兼容性无可匹敌:Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
问
Kafka 为什么要把消息分区(partition)?如何分区?
答:
1、把消息分区有利于:
-
提高吞吐量:一个Topic可以有多个Partition组成,那么就可以实现并行处理,提高吞吐量。多个消费者可同时处理不同分区的消息。
-
增强容错性:一个分区故障不影响其他分区,且分区有副本可保证数据可用性。
-
便于实现负载均衡。可根据消费者数量自动分配分区,确保处理均衡。
当有多个消费者同时订阅一个主题时,Kafka 会根据消费者的数量自动分配主题的分区给这些消费者。
2、如何分区的:
-
指明 Partition 的情况:如果生产者在发送消息时明确指定了 Partition 值,那么 Kafka 就直接将该指定的值作为消息要发送到的 Partition。
-
有 key 但无指定 Partition 的情况:当没有明确指定 Partition 但消息有 key 时,Kafka 会计算 key 的哈希值,然后与该Topic 的分区数量取余,得到的余数就是要放入分区的ID。
这样可以确保具有相同 key 的消息被分配到同一个 Partition,方便后续的处理和消费。
-
既无 Partition 也无 key 的情况:在既没有指定 Partition 也没有 key 的情况下,第一次发送消息时,Kafka 会随机生成一个整数。之后每次发送消息,在这个整数上自增,然后将这个值与主题可用的 Partition 总数取余,得到消息要被发送到的 Partition。
这种方式类似于轮询(round-robin)算法,确保消息在各个 Partition 之间相对均衡地分布。
Kafka 如何保证消息的消费顺序?
答:
具体的分析:Kafka 中 Partition(分区)是真正保存消息的地方,我们发送的消息都被放在了这里。而我们的 Partition(分区) 又存在于 Topic(主题) 这个概念中,并且我们可以给特定 Topic 指定多个 Partition。每次添加消息到 Partition(分区) 的时候都会采用尾加法,如下图所示。 Kafka 只能为我们保证 Partition(分区) 中的消息有序。
消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。Kafka 通过偏移量(offset)来保证消息在分区内的顺序性。

因此,常用的 Kafka 保证消息消费的顺序,有两种方式:
-
1 个 Topic 只对应一个 Partition。(但是这种办法效率不高)
-
(推荐)发送消息的时候指定
key/Partition:Kafka 中发送 1 条消息的时候,可以指定topic,partition,key,data(数据)4 个参数。如果你发送消息的时候指定了 Partition 的话,所有消息都会被发送到指定的 Partition。并且,同一个 key 的消息可以保证只发送到同一个 partition。例如,在一个电商系统中,如果以订单 ID 作为 “key”,那么所有与同一个订单相关的操作消息(如订单创建、支付、发货等)在发送时都带有相同的订单 ID 这个 “key”。根据 Kafka 的规则,这些具有相同 “key” 的消息会被分配到同一个分区。
Kafka 如何发现消息丢失?
这需要根据消息丢失的位置,具体分析:
- 生产者端消息丢失
- 消费者端消息丢失
- Kafka(broker)服务之间消息同步时,消息丢失
生产者丢失消息、如何知道是否丢失?
丢失情况:生产者(Producer) 调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。
得知消息丢失:通过send()方法返回值查看消息是否发送成功。
-
方式1:同步方式,生产者将消息发送出去之后,需要等待消息发送的结果返回。
// 使用get()方法,是同步的方式 SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get(); if (sendResult.getRecordMetadata() != null) { logger.info("生产者成功发送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendRe sult.getProducerRecord().value().toString()); } -
方式2:异步回调的方式。可以采用异步回调的方式,获取消息发送的结果,从而得知消息是否丢失。
// send()方法默认的是异步方式 ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o); future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()), ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
生产者端尽量避免消息丢失的方法
设置重试次数、重试间隔(注意重试机制 生产者、消费者都可以用)。这是一种尽可能的避免消息丢失的策略。即当消息发送失败时,可以多重试几次,增加发送成功的几率。
具体方法:
- 为 Producer 的
retries(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。 - 另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你 3 次一下子就重试完了。
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "your_kafka_bootstrap_servers");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 设置重试次数和重试间隔
RetryTemplate retryTemplate = new RetryTemplate();
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy();
retryPolicy.setMaxAttempts(10);
retryTemplate.setRetryPolicy(retryPolicy);
FixedBackOffPolicy backOffPolicy = new FixedBackOffPolicy();
backOffPolicy.setBackOffPeriod(1000); // 重试间隔为 1 秒
retryTemplate.setBackOffPolicy(backOffPolicy);
configProps.put(ProducerConfig.RETRIES_CONFIG, retryTemplate);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
消费者丢失消息的情况,如何知道丢失?
消费者端丢失消息的情况:当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。此时会有问题,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
得知消息丢失的办法:手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset 。
弊端:这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
Kafka服务端消息丢失,如何避免丢失?
Kafka 为分区(Partition)引入了多副本(Replica)机制。假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。
如何避免丢失?这需要通过以下参数共同起作用:
-
acks:生产者发送消息后要求的确认机制级别。-
acks=0:产者发送消息后,不需要等待任何来自服务器的响应。种设置下,生产者发送消息的速度最快,但消息可能会在网络传输等过程中丢失,因为没有任何确认机制来保证消息已经被成功接收和存储。 -
acks=1:生产者发送消息后,只要集群中的 leader 成功接收到消息,就会向生产者发送确认响应,而不会管follower 是否接收成功。 -
acks=all(也可以用acks=-1表示):生产者发送消息后,需要等待所有的同步副本(In-Sync Replicas,ISR)都成功接收到消息后,才会收到来自服务器的确认响应。也就是 该分区的 leader、和与leader数据时同步的followers 都接收消息成功。
-
-
replication.factor >= 3:指定了一个主题(topic)的副本因子数量,即一个分区(partition)有多少个副本(这里设置为每个分区有一个 leader 副本和3个 follower 副本)。虽然造成了数据冗余,但是带来了数据的安全性。 -
min.insync.replicas > 1:指定了为了被认为是 “已同步” 的,一个分区(partition)中最少需要保持同步状态的副本数量。这样配置代表消息至少要被写入到 2 个副本才算是被成功发送。 -
unclean.leader.election.enable=false:控制是否允许非同步副本(不在 ISR 中的副本,即与leader数据时同步的followers)成为 leader。当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
Kafka 如何保证消息不重复消费?
参考:https://www.cnblogs.com/yangyongjie/p/14675119.html
先说为什么 Kafka 会重复消费消息?
答:主要有如下情况
-
消费者宕机、重启等。导致消息已经消费但是没有提交offset。
-
消费者在处理耗时的任务,处理时间超过Kafka服务器设置的
max.poll.interval.ms时间,Kafka 会误认为这个消费者死掉,会触发再均衡(rebalance)。(在重平衡过程中,其他消费者可能会被分配到之前由该问题消费者处理的分区,而由于偏移量未正确处理,可能会导致重复消费之前已经处理过的消息)max.poll.interval.ms参数用于控制消费者在两次调用poll()方法之间的最大时间间隔。超过这个间隔时间这个消费者就会被认为挂掉了。
解决办法:
-
幂等校验:消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。【推荐】
比如,消费者在本地存储(如数据库、缓存等)中检查(比如通过订单ID)是否已经处理过具有相同订单号的消息,处理过就不会再次处理了。
-
关闭自动提交 offset,改为手动提交 offset。但这种方式可能会有两个问题:
- 如果是处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
- 如果是拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底
Kafka 的重试机制?
Kafka 的重试机制
Kafka 的重试机制既可以针对生产者,也可以针对消费者。
- 当生产者发送消息到 Kafka 集群时,如果出现网络问题、Broker 故障等情况导致消息发送失败,生产者可以配置重试机制来自动重新发送消息,以提高消息发送的成功率。
- 消费者在消费消息时,如果处理消息的过程中出现异常,也可以通过一定的方式进行重试,以确保消息能够被正确处理。
重试机制默认最多重试10次,每次重试的时间间隔为 0,即立即进行重试。如果在 10 次重试后仍然无法成功消费消息,则不再进行重试,消息将被视为消费失败。当然也可以自定义重试次数、重试间隔。
重试失败后,如何告警?
答:自定义重试失败后逻辑,需要手动实现,以下是一个简单的例子,重写 DefaultErrorHandler 的 handleRemaining 函数,加上自定义的告警等操作。
@Slf4j
public class DelErrorHandler extends DefaultErrorHandler {
public DelErrorHandler(FixedBackOff backOff) {
super(null,backOff);
}
@Override
public void handleRemaining(Exception thrownException, List<ConsumerRecord<?, ?>> records, Consumer<?, ?> consumer, MessageListenerContainer container) {
super.handleRemaining(thrownException, records, consumer, container);
log.info("重试多次失败");
// 自定义操作
}
}
重试失败后的数据如何再次处理?-- 死信队列
当达到最大重试次数后,数据会直接被跳过,继续向后进行。当代码修复后,如何重新消费这些重试失败的数据呢?
答:当 Kafka 中的数据重试失败后,可以使用**死信队列(Dead Letter Queue,DLQ)**来进行再次处理。
- 死信队列(Dead Letter Queue,DLQ):未被正常消费的消息 会被放入死信队列中,在死信队列中,可以进一步分析、处理这些无法正常消费的消息,以便定位问题、修复错误,并采取适当的措施。
- 在实际使用过程中,可以使用
@DltHandler注解处理。
消费者消息消费时,失败之后会怎么样?
在默认配置下,当消费异常会进行重试,重试多次后会跳过当前消息,继续进行后续消息的消费,不会一直卡在当前消息。
因此,即使某个消息消费异常,Kafka 消费者仍然能够继续消费后续的消息,不会一直卡在当前消息,保证了业务的正常进行。