论文阅读:OpenSTL: A Comprehensive Benchmark of Spatio-Temporal Predictive Learning
论文地址:arxiv
摘要
由于时空预测没有标准化的比较,所以为了解决这个问题,作者提出了 OpenSTL,这是一个全面的时空预测学习基准。它将流行的方法分为基于循环和非循环模型两类。OpenSTL提供了一个模块化且可扩展的框架,实现了各种最先进的方法。
正文
当前的时空预测模型可以分别循环型与非循环型。而在该领域,有一个问题:是否有必要使用循环神经网络架构来捕捉时间依赖关系。所以作者为了公平的评估,提出了一个全面的基准。
贡献点
- 构建了 OpenSTL,包含了 14 种代表性算法与 24 个模型的时空预测学习的综合基准。
- 在多样化的任务进制了实验。
- 重新思考了非循环模型的潜力,提出了类似 MetaFormer 的架构来促进非循环时空预测学习。
问题定义
给定一系列视频帧 X t , T = x i t − T + 1 t X_{t,T}={x_i}^t_{t-T+1} Xt,T=xit−T+1t,涵盖了过去 T T T 帧,从时间 t − T + 1 t-T+1 t−T+1 到时间 t t t,目标是预测随后的 T ′ T' T′ 帽 Y t + 1 , T ′ = x i t + 1 t + 1 + T ′ Y_{t+1,T'}={x_i}^{t+1+T'}_{t+1} Yt+1,T′=xit+1t+1+T′,即从时间 t + 1 t+1 t+1 开始的未来 T ′ T' T′ 帧。其中每一帧 x i x_i xi 通常包含 C C C 个通道,高度为 H H H 像素,宽度为 W W W 像素。而在实际操作中,通道将输入帧序列表示为 X t , T ∈ R T ∗ C ∗ H ∗ W X_{t,T} \in R^{T*C*H*W} Xt,T∈RT∗C∗H∗W,而输出序列通常表示为 Y t + 1 , T ′ ∈ R T ′ ∗ C ∗ H ∗ W Y_{t+1,T'} \in R^{T'*C*H*W} Yt+1,T′∈RT′∗C∗H∗W
具有可学习参数
Θ
\Theta
Θ 的模型通过利用空间与时间依赖关系学习映射
F
Θ
:
X
t
,
T
↦
Y
t
+
1
,
T
′
F_{\Theta}:X_{t,T} \mapsto Y_{t+1,T'}
FΘ:Xt,T↦Yt+1,T′。而最优参数
Θ
∗
\Theta^*
Θ∗ 由下式给出:
Θ
∗
=
a
r
g
m
i
n
Θ
L
(
F
Θ
(
X
t
,
T
)
,
Y
t
+
1
,
T
′
)
\Theta^*=argmin_\Theta L(F_\Theta(X_{t,T}),Y_{t+1,T'})
Θ∗=argminΘL(FΘ(Xt,T),Yt+1,T′)
L
L
L 为表示量化这种差异的损失函数。
对于基于循环的模型,映射
F
Θ
F_\Theta
FΘ 包含若干循环交互:
F
Θ
:
f
θ
(
x
t
−
T
+
1
,
h
t
−
T
+
1
)
∘
…
∘
f
θ
(
x
t
,
h
t
)
∘
…
∘
f
θ
(
x
t
+
T
′
−
1
,
h
t
+
T
′
−
1
)
F_\Theta : f_\theta(x_{t-T+1}, h_{t-T+1}) \circ \ldots \circ f_\theta(x_t, h_t) \circ \ldots \circ f_\theta(x_{t+T'-1}, h_{t+T'-1})
FΘ:fθ(xt−T+1,ht−T+1)∘…∘fθ(xt,ht)∘…∘fθ(xt+T′−1,ht+T′−1)
其中
h
i
h_i
hi 表示包含历史信息的记忆状态,
f
θ
f_\theta
fθ 表示每对相信帧之间的映射。参数
θ
\theta
θ 在每个状态间共享。所以,预测过程可以表示为:
x
t
+
1
=
f
θ
(
x
i
,
h
i
)
,
∀
i
∈
{
t
+
1
,
…
,
t
+
T
′
}
x_{t+1} = f_\theta(x_i, h_i), \quad \forall i \in \{t + 1, \ldots, t + T'\}
xt+1=fθ(xi,hi),∀i∈{t+1,…,t+T′}
而对于无循环模型,预测过程直接将整个观察到的帧序列输入模型,并一次性输出完整预测帧。
支持的方法
OpenSTL 在一个统一的框架下实现了 14 种具有代表性的时空预测学习方法,包括 11 种基于循环神经网络和 3 种不基于循环神经网络。如下所示:
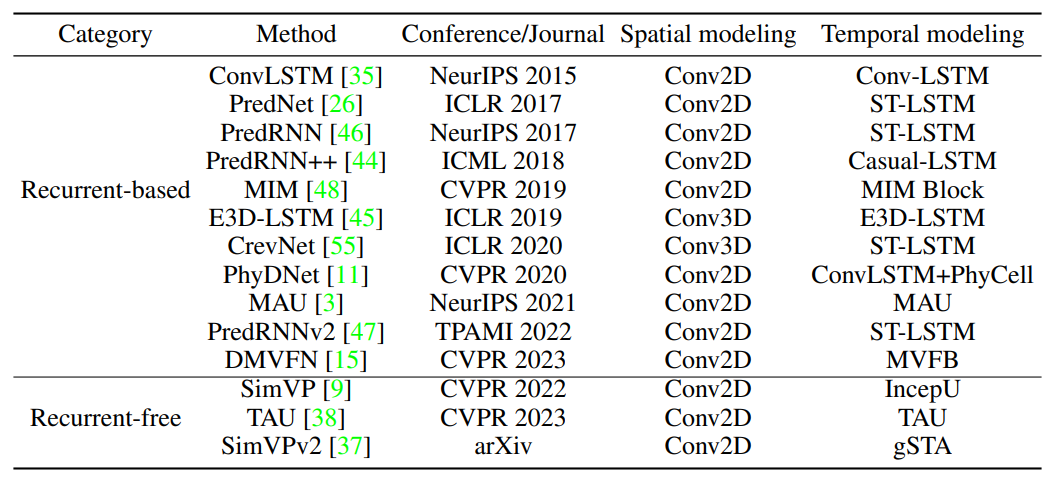
这些方法的主要区别在于它们如何使用其提出的模块来建模时间依赖性。
非循环时空预测学习模型具有相似的架构,如下所示。编码器由几个二维卷积网络组成,将高维输入数据投射到低维潜在空间。给定一批输入观察帧 B ∈ R B ∗ T ∗ C ∗ H ∗ W B \in R^{B*T*C*H*W} B∈RB∗T∗C∗H∗W,编码器专注于帧内空间相关性,忽略时间建模。随后,中间时间模块将低维表示沿时间维度䨺,以确定时间依赖性。最后,解码器由几个二维卷积上采样网络组成,从学习的潜在表示中重建后续帧。
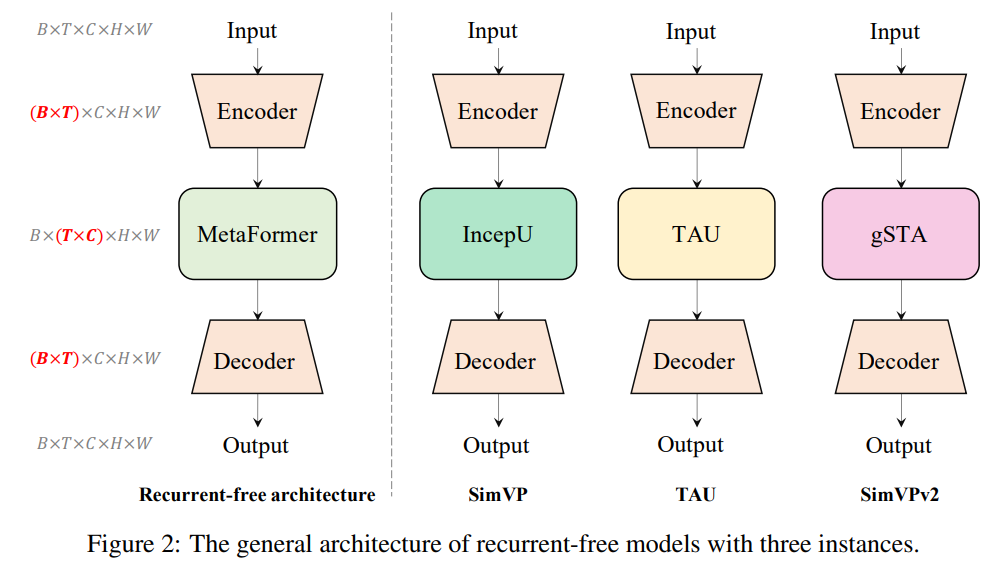
编码器和解码器通过在低维潜在空间中建模时间依赖性来实现高效的时间学习。非循环模型的核心组件是时间模块。然而,作者认为这种能力主要源自通用的非循环架构,而不是特定的时间模块。
支持的任务
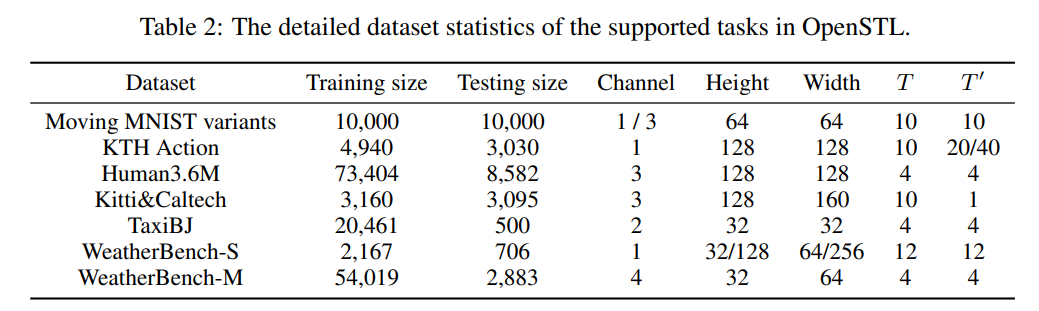
OpenSTL 支持五种不同的任务,这些任务涵盖了从合成模拟到各种规模的现实世界场景。任务包括合成移动物体轨迹、现实世界的人体动作捕捉、驾驶场景、交通流和天气预报。以下是提供的数据集的统计摘要。
支持的评估指标
- 误差指标:使用均方误差(MSE)和平均绝对误差(MAE)来评估预测结果与真实目标之间的差异。在天气预报中,还使用了均方根误差(RMSE)。
- 相似性指标:使用结构性指数(SSIM)和峰值信噪比(PSRN)来评估预测结果与真实目标之间的相似度。这些指标广泛用于图像处理与计算机视觉领域。
- 感知指标:实现了感知图像补偿误差(LPIPS),用于评估人类视觉系统中预测结果与真实目标之间的感知差异。LPIPS 提供了视觉任务的感知对齐评估。作者在现实世界的视频预测任务中使用这一指标。
- 计算指标:通过参数数量和浮点运算次数(FLOPs)来评估模型的计算复杂度。
代码库结构
OpenSTL 遵循 OpenMMLab 的设计原则,吸收了 OpenMixup 和 USB 的代码元素。
预测结果
合成的移动物体轨迹预测
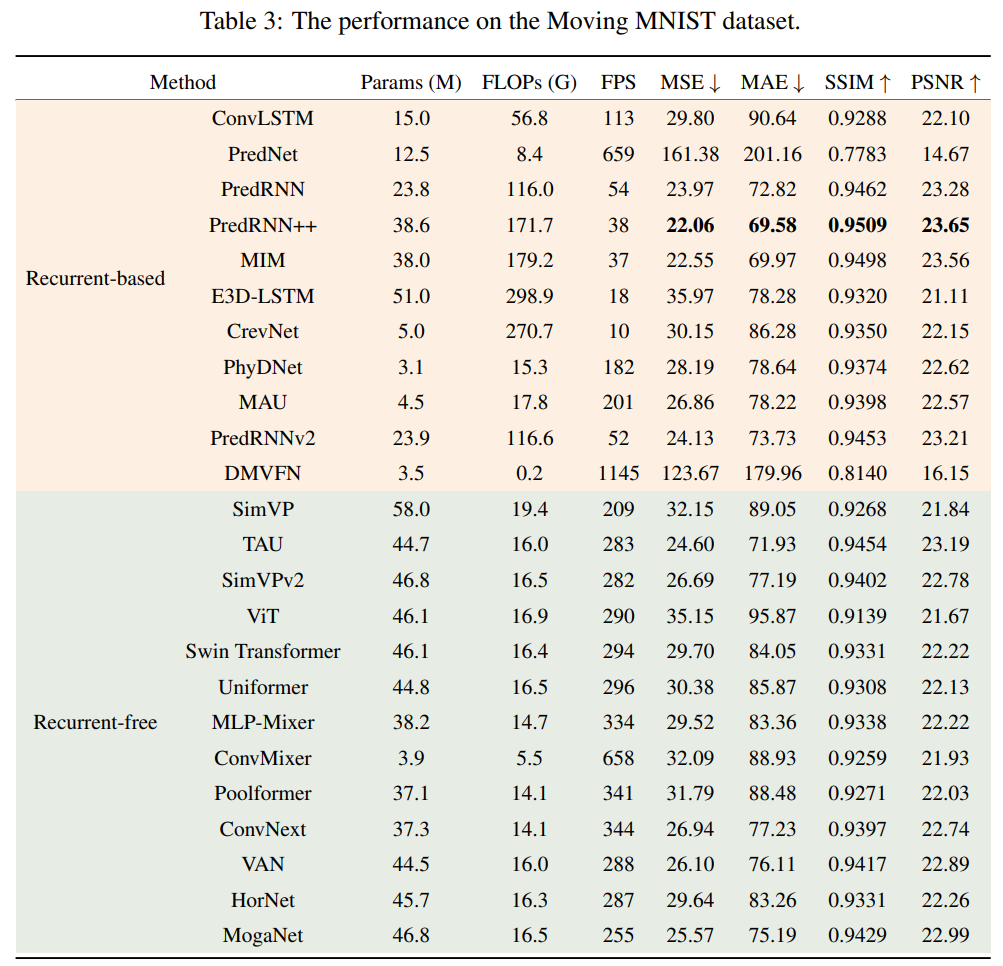
在 Moving MNIST,Moving FashionMNIST 和 Moving MNIST-CIFAR。上评估了所有的模型。以下是在三个数据集上的结果。
Moving MNIST:
Moving FashionMNIST:
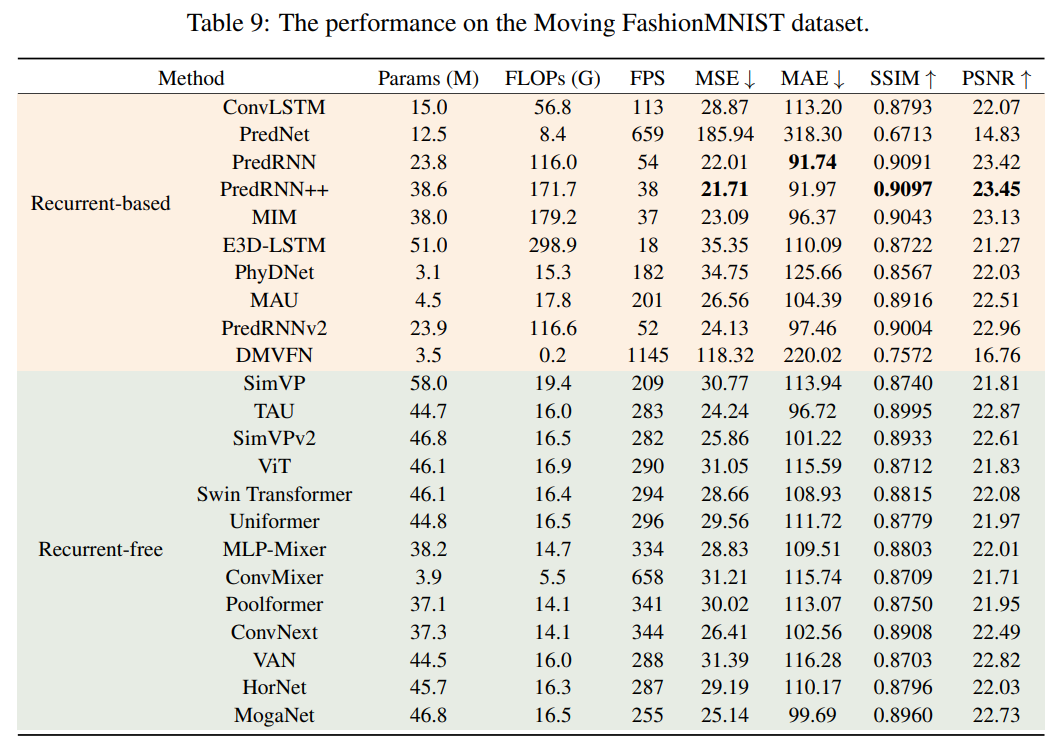
Moving MNIST-CIFAR:
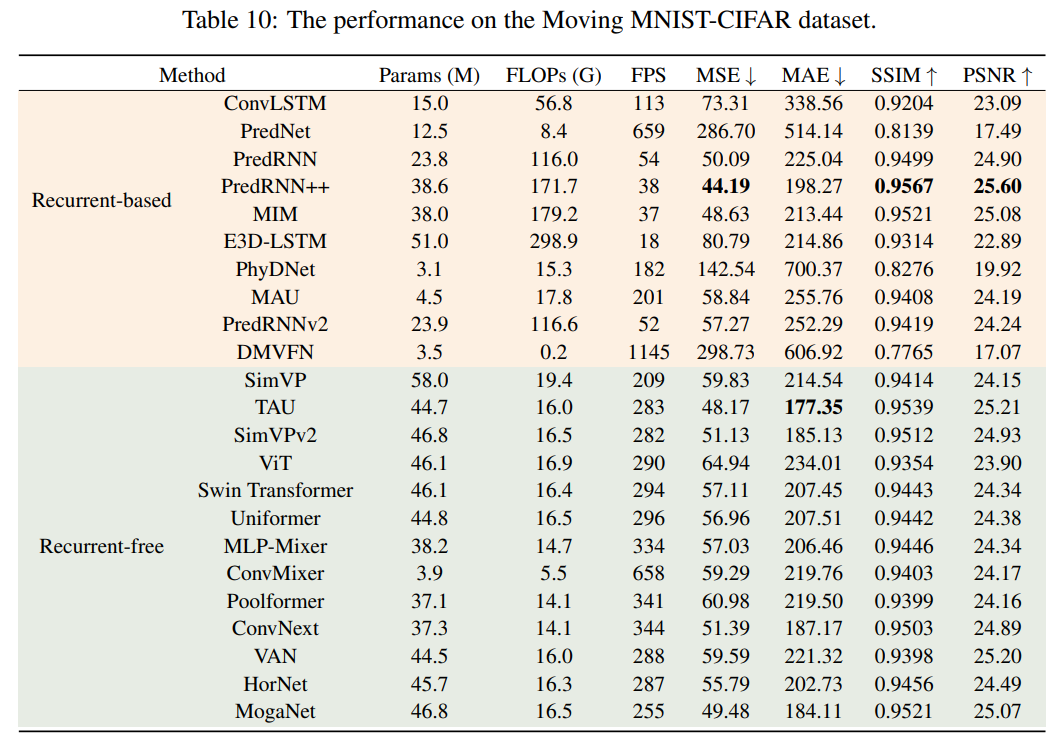
可以观察到:
- 基于循环(recurrent-based)模型的结果不一致,并不总是优于无循环(recurrent-free)模型
- 基于循环的模型推理速度总是比无循环模型慢。
这进一步证明了无循环模型在表现上相当,但效率显著更高。
作者还做了可视化示例,这里给出 Monving MNIST 的结果。为方便排版,作者将帧从下到上垂直排列。可以观察到,大多数基于循环神经网络(recurrent-based)的模型产生了高质量的预测结果,除了PredNet和DMVFN以外。无循环神经网络(recurrent-free)的模型取得了可比的结果,但在最后几帧中表现出模糊现象。这一现象表明,基于循环神经网络的模型在捕捉时间依赖性方面表现出色。

真实视频预测
使用了 KTH 和 Human3.6M 数据集捕捉人类运动以及用 Kitti & Caltech 数据集进行驾驶场景预测。
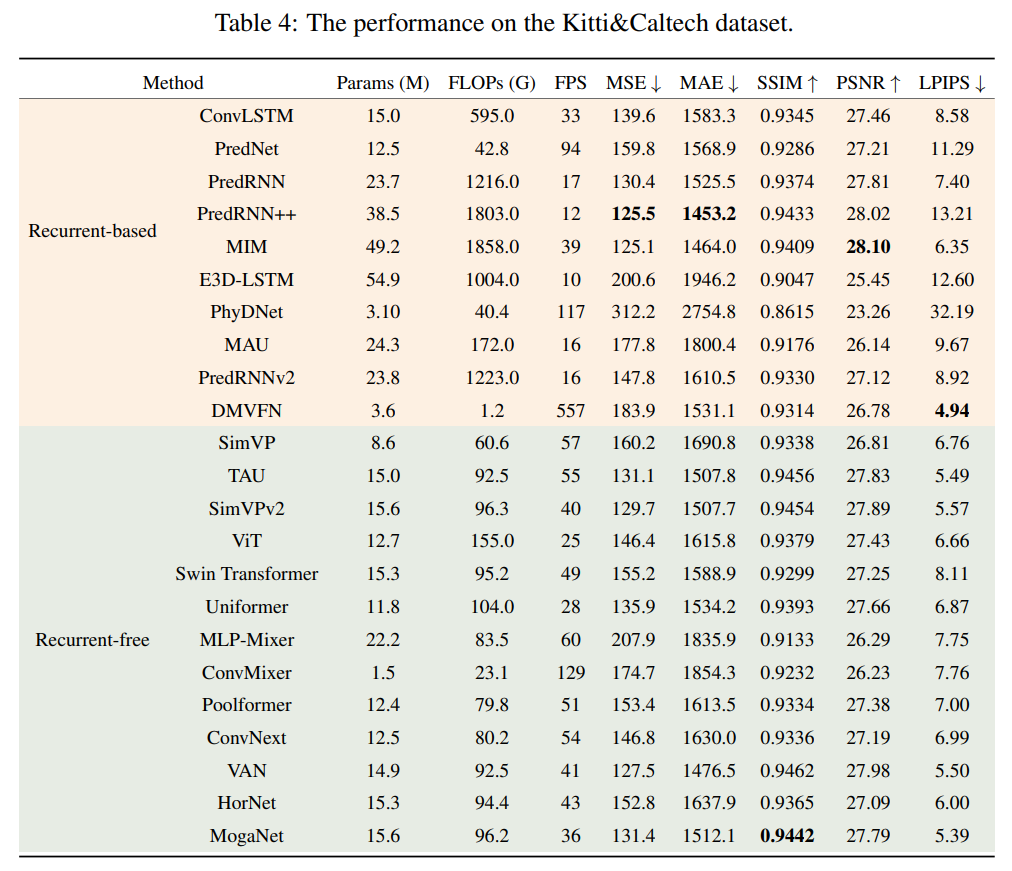
以下是 Kitti & Caltech 的结果:
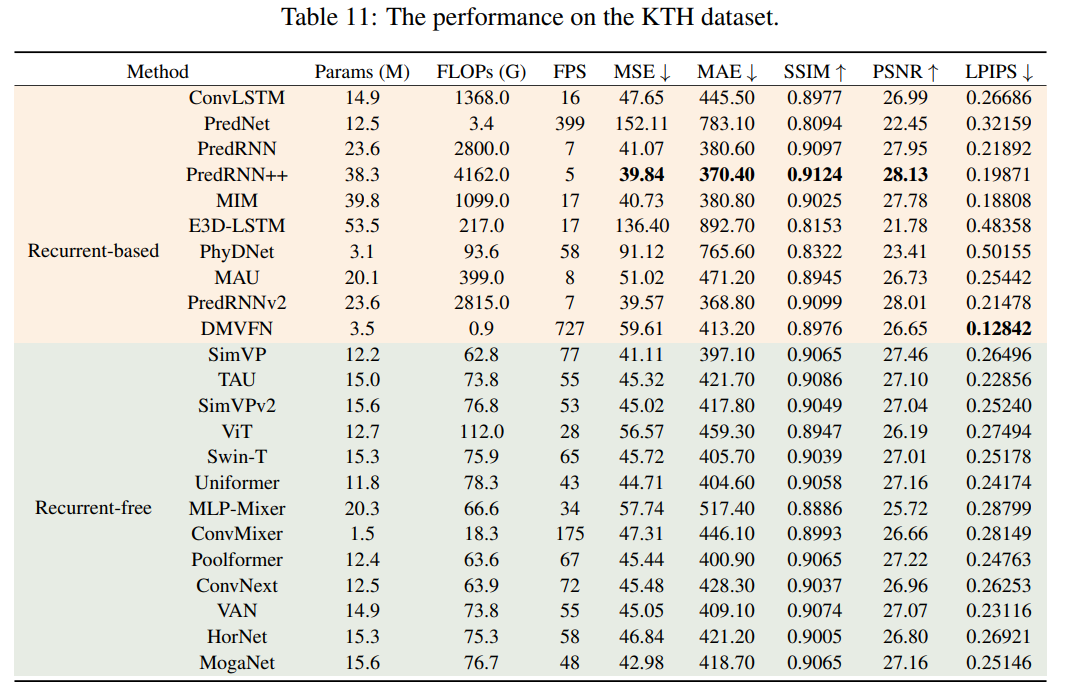
KTH:
Human3.6M:

可以观察到,随着分辨率的增加,基于循环的模型的计算复杂度显著增加。相反,无循环模型实现了效率和性能之间的优良平衡。值得注意的是,虽然一些基于循环的模型达到了更低的 MSE 和 MAE,每秒浮点运算(FLOPs)几乎比无循环模型高出20倍。这突显了无循环模型的效率优势,特别是在高分辨率场景中。
交通和天气预测
在 TaxiBJ 和 WeatherBench 数据集上进行了实验。作者对低分辨率单变量天气因素预测的代表方法进行 MAE 和 RMSE 指标比较。
TaxiBJ 数据集上的结果:

可以看到,无循环神经网络的模型在处理低频交通流数据时表现出了有希望的结果。
WeatherBench 数据集上:
以下展示了四个气候因素的结果,即温度、湿度、风向和云量。显著的是,所有天气因素中,无循环模型均优于基于循环的模型,表明其在宏观任务中应用时空预测学习的潜力,而不是仅依赖基于循环的模型。这些发现强调了无循环模型的前景,表明它们可以在天气预报中成为现有基于循环的模型的可行替代方案。
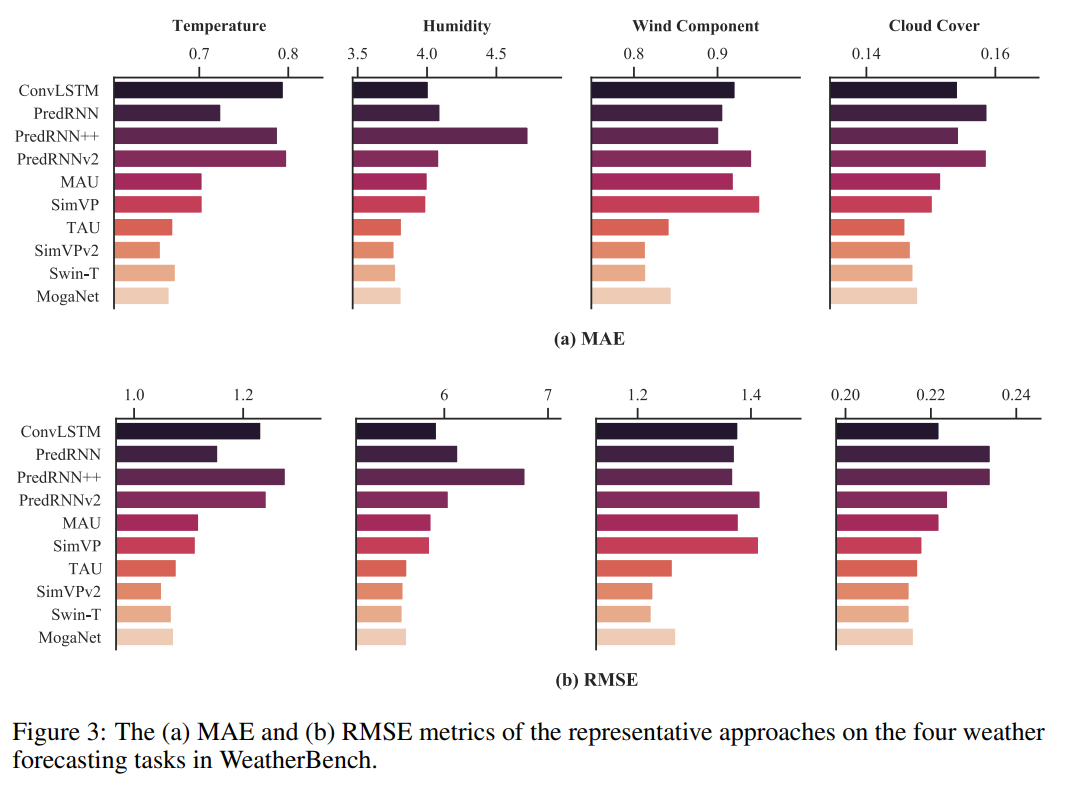
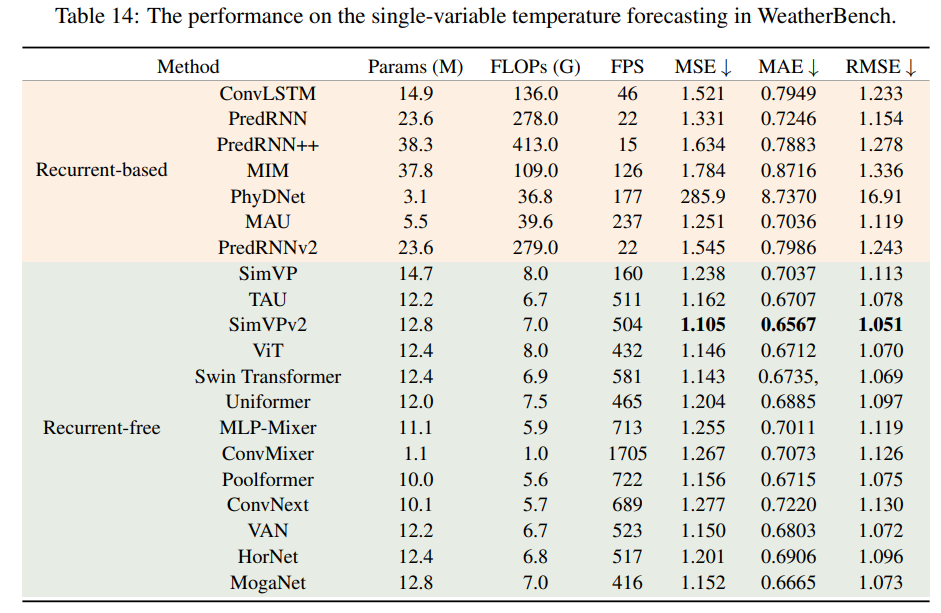
单变量温度预测
无循环神经网络模型在性能和效率方面明显优于基于循环神经网络的模型,取得了压倒性的胜利。
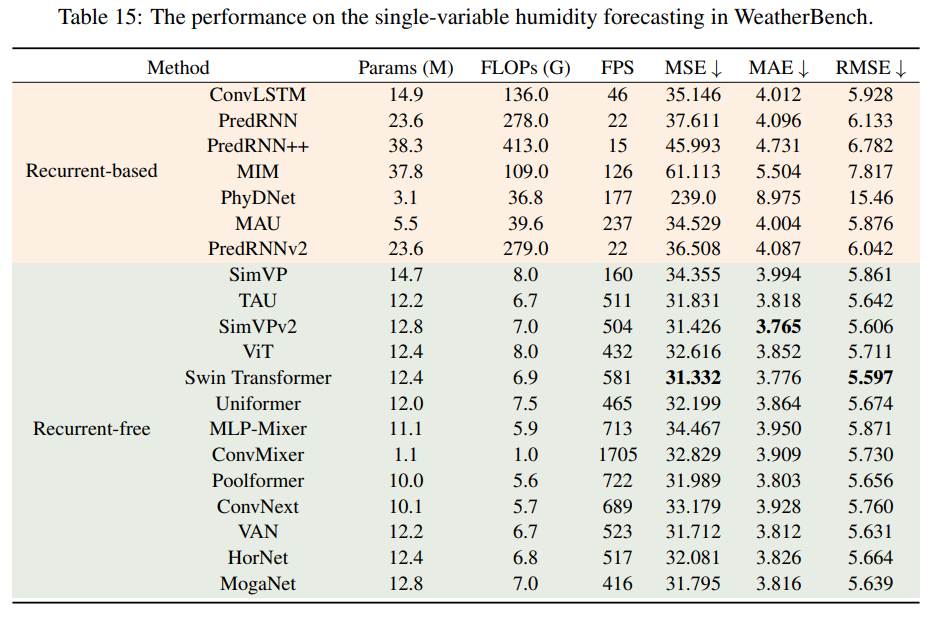
单变量湿度预测
结果与温度预测几乎一致
单变量风分量预测
可以看到:大多数无循环神经网络模型的表现优于基于循环神经网络的模型。

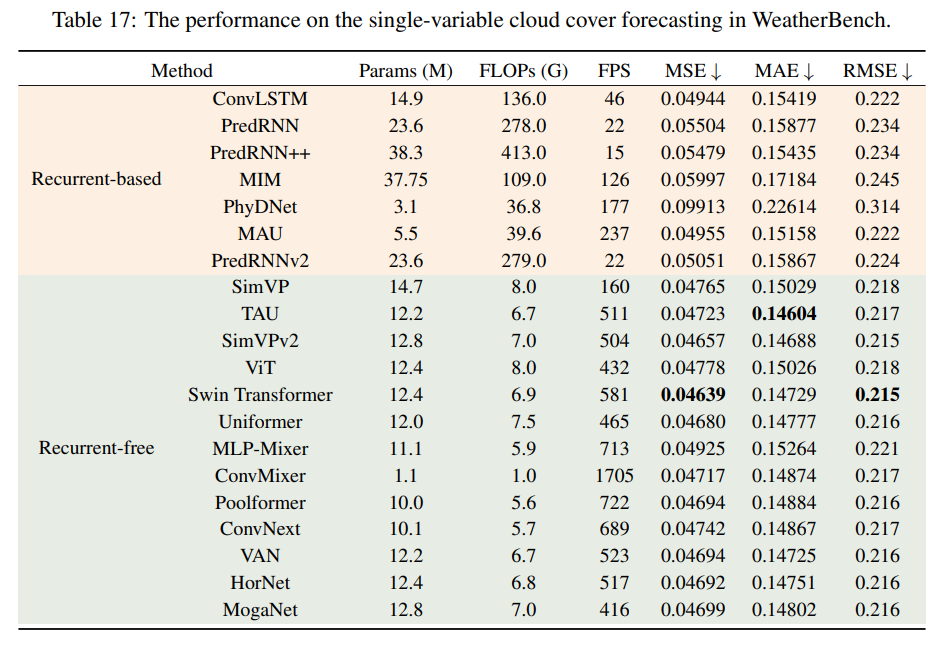
单变量云量预测
可以看到:所有无循环神经网络模型都比它们的对手表现得更好。
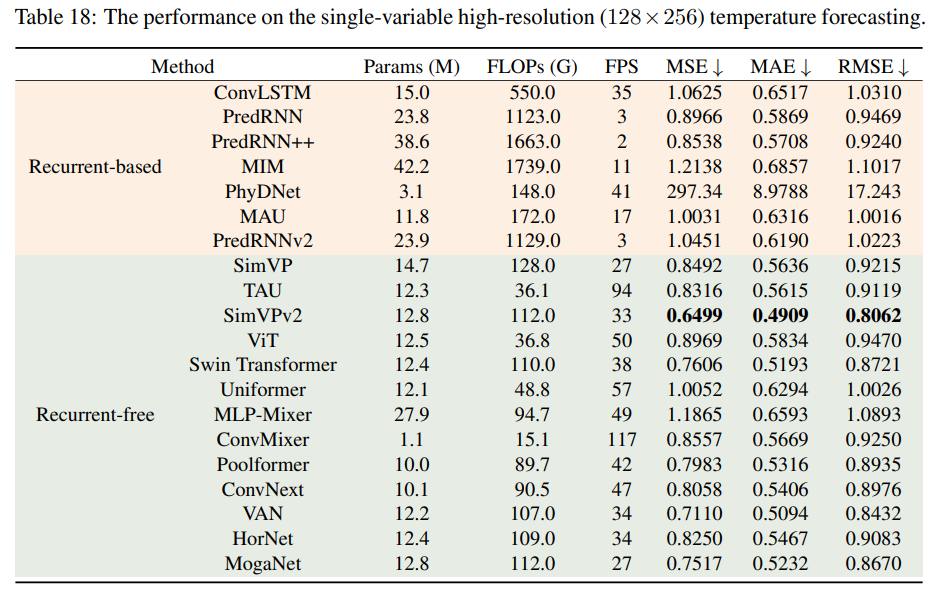
高分辨率单变量温度预测
高分辨率(128*256)。SimVPv2实现了卓越的性能,远远超过了基于循环神经网络的模型。
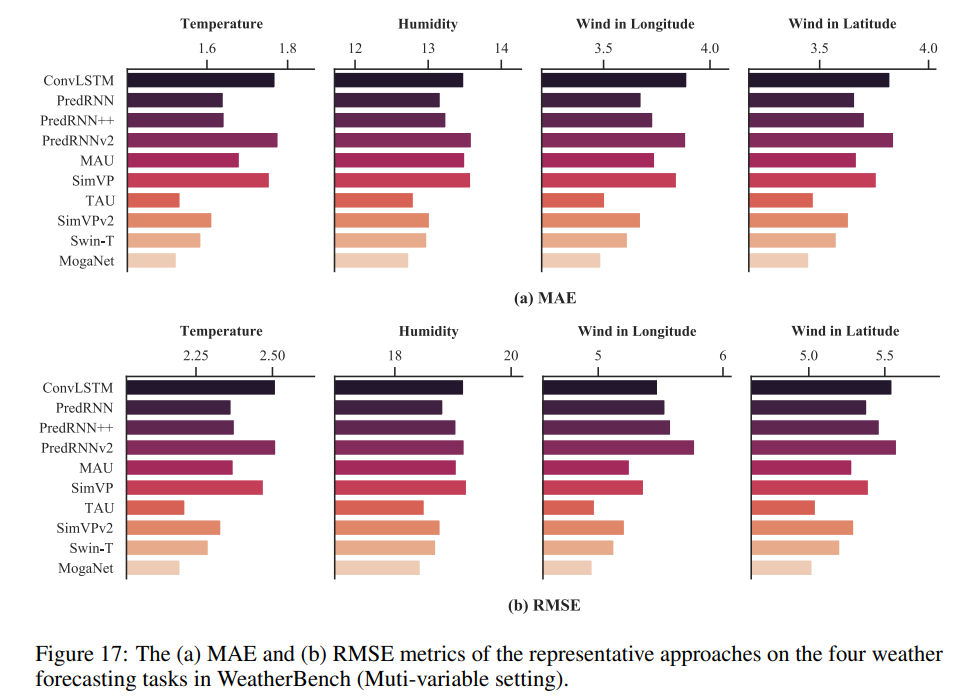
多变量预测
此任务侧重于多因素气候预测。在预测过程中包含了温度、湿度、纬度风和经度因素。

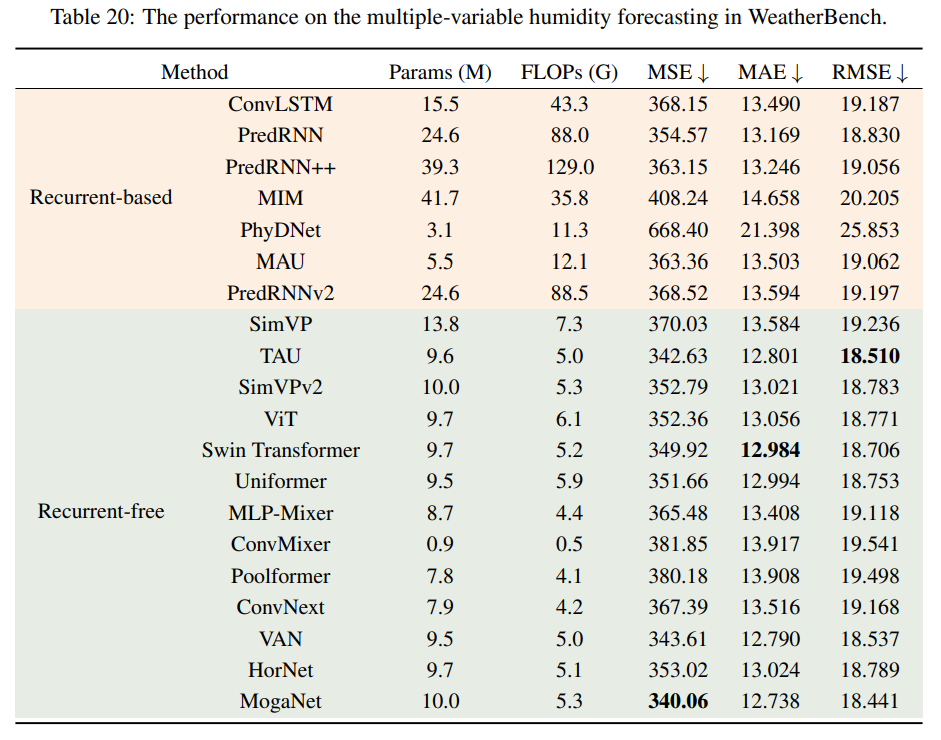
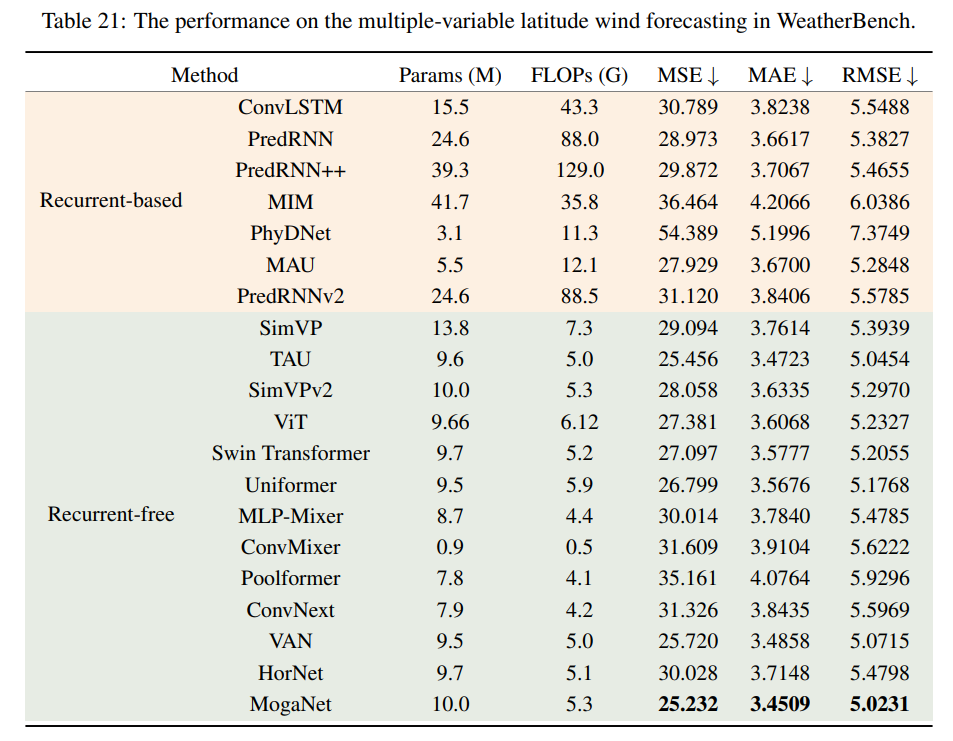

鲁棒性分析
作者设计了三个实验:
- Moving MNIST - 缺失,即处理缺失帧的输入帧,我们将随机缺失帧的概率设为20%;
- Moving MNIST - 动态,即为每个数字的速度添加随机高斯噪声,使其运动速度不规律;
- Moving MNIST - 感知,即随机遮挡输入帧,使用大小为24×24的黑色补丁遮挡。
作者选择了三种代表性的基于循环和三种无循环方法进行评估。以下是结果:
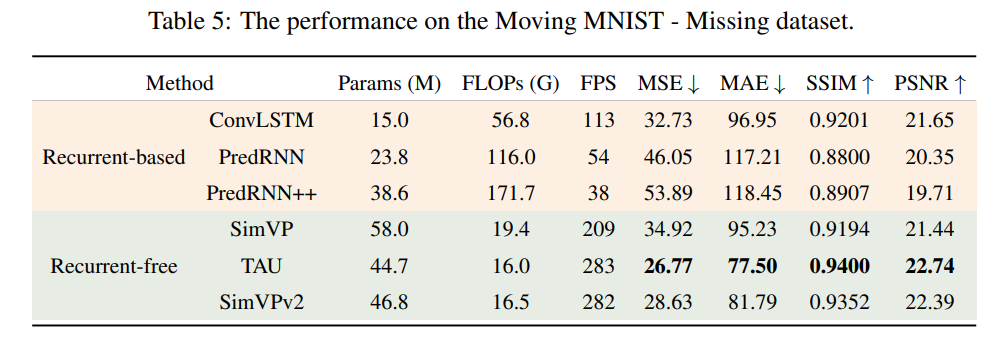
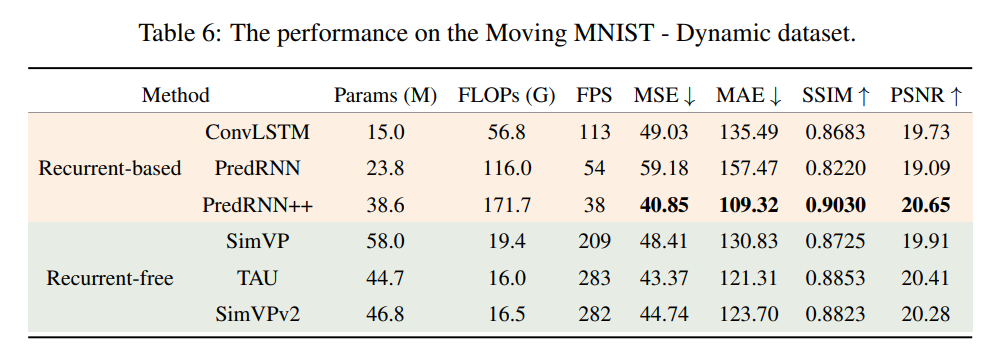
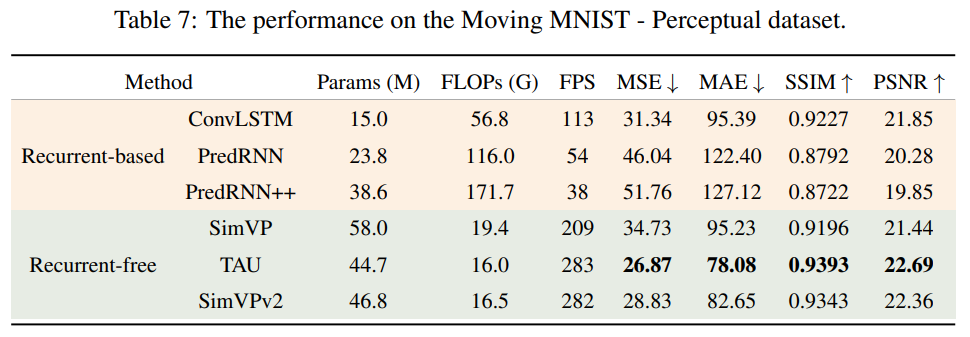
可以观察到,无循环方法在缺失和感知噪声情境下表现出显著的鲁棒性。即使与无噪声的情况相比,性能下降也较小,因为它们关注全局信息。相反,基于循环的方法表现出显著的性能下降。它们过于关注单帧之间的关系,导致过拟合。在动态噪声的情况下,所有方法均面临显著的性能下降,因为数字的速度变得不规律且难以预测。
总结
作者观察到,循环架构在捕捉时间依赖性方面具有优势,但也不是必须的,尤其是在计算开销较大的任务中。非循环模型可以作为一种可行的替代方案,在效率和性能之间取得良好的平衡。基于循环的模型在捕捉高频空间-时间依赖性方面的有效性可以归因于其对逐帧变化的顺序跟踪,提供了一种局部时间归纳偏差。而非循环模型则结合了多个帧,展现出一种适合低频空间-时间依赖性的全局时间归纳偏差。