一个功能强大的文档解析和转换工具,支持PDF、DOCX、PPTX和Markdown等
大家好,今天给大家分享一个用于处理文档的项目Docling,旨在帮助用户轻松快速地解析文档并将其转换为所需格式,为使用生成式人工智能(gen AI)准备文档。
项目介绍
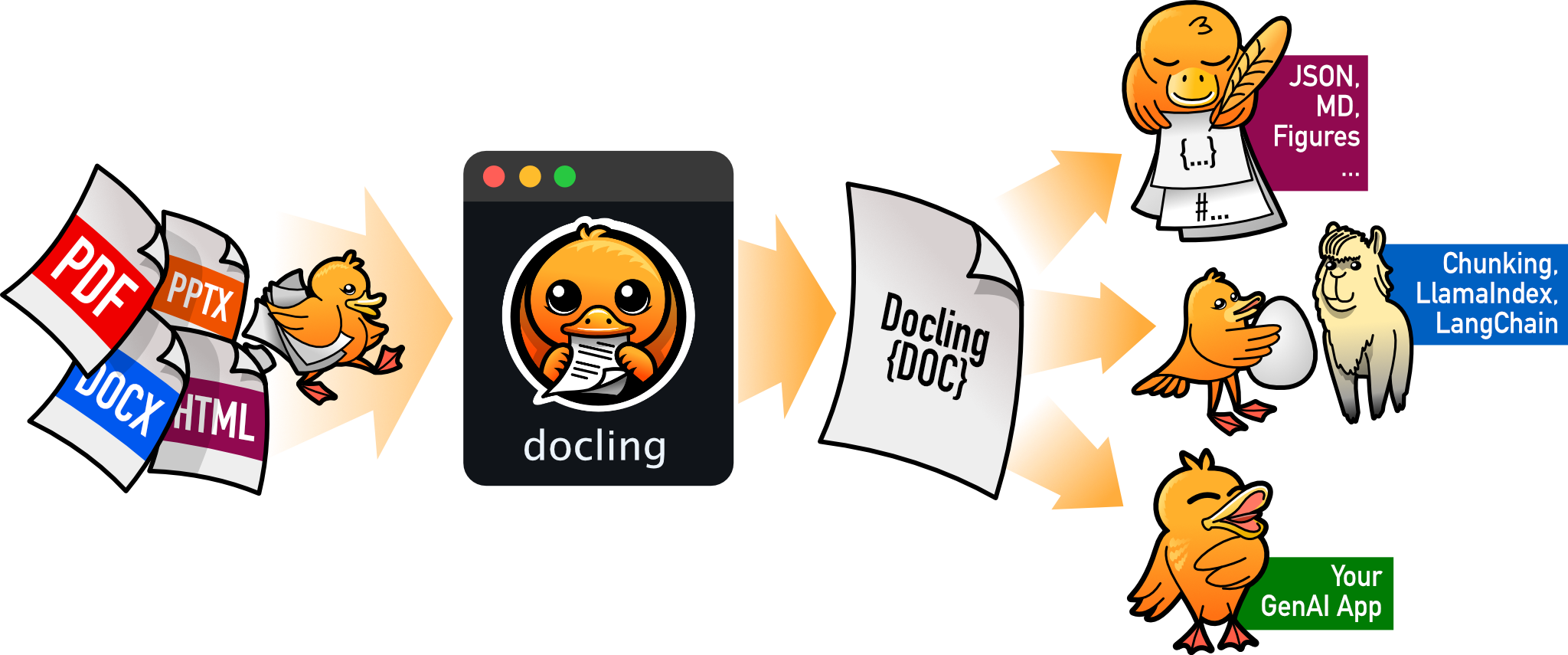
Docling是一个功能强大的文档解析和转换工具,支持多种文档格式,提供先进的PDF理解功能,并允许用户将文档转换为Markdown和JSON格式。它还具有元数据提取、OCR支持、无缝集成以及其他高级功能,非常适合需要处理和分析大量文档的用户。
功能特性
文档格式支持广泛:能够读取多种流行的文档格式,包括 PDF、DOCX、PPTX、图像(如 JPEG、PNG 等)、HTML、AsciiDoc 和 Markdown 等。并且可以将这些文档导出为 Markdown 和 JSON 格式,方便在不同的应用场景中使用。例如,将 PDF 格式的研究报告转换为 Markdown 格式,以便于在文本编辑器中进行编辑和分析。
高级 PDF 文档理解:在处理 PDF 文档时,具有高级的理解能力,包括解析页面布局、确定阅读顺序以及识别表格结构等。这使得从复杂的 PDF 文档中提取和转换信息更加准确和有效,例如在处理包含多栏排版、图表和表格的学术论文 PDF 时,能够准确地将内容转换为结构化的格式。
统一的文档表示格式:采用统一且富有表现力的 DoclingDocument 表示格式,方便对文档进行处理和操作,无论是在文档转换过程中还是在与其他工具或系统集成时,都能提供一致的文档数据结构。
元数据提取功能:可以提取文档的元数据,如标题、作者、参考文献和语言等信息。这些元数据在文档管理、搜索和分析等方面具有重要价值,例如在构建文档库时,可以根据元数据对文档进行分类和检索。
与其他工具集成:能够无缝集成 LlamaIndex 和 LangChain,为强大的检索增强生成(RAG)和问答(QA)应用提供支持。通过与这些工具的结合,可以构建出更智能的文档处理和问答系统,例如基于文档知识库进行智能问答,为用户提供准确的信息。
支持 OCR 技术(光学字符识别):对于扫描的 PDF 文档,提供 OCR 支持,能够将扫描图像中的文字识别并转换为可编辑的文本,进一步扩大了可处理文档的范围,使纸质文档数字化后也能方便地进行处理和分析。
简单便捷的命令行界面(CLI):提供了简单易用的命令行工具,用户可以通过命令行操作快速执行文档转换等任务,方便在脚本或自动化流程中使用 Docling,提高工作效率。
安装使用
安装
可以使用常见的包管理器(如 pip)进行安装。
pip install docling该项目适用于 macOS、Linux 和 Windows 环境,并且支持 x86_64 和 arm64 架构。
更详细的安装说明,请阅读安装文档。
使用
转换单个文件
from docling.document_converter import DocumentConverter
source = "https://arxiv.org/pdf/2408.09869" # PDF path or URL
converter = DocumentConverter()
result = converter.convert(source)
print(result.document.export_to_markdown()) # output: "### Docling Technical Report[...]"命令行界面(CLI)
# 将单个文件转换为 Markdown(默认)
docling myfile.pdf
# 转换为 Markdown 和 JSON 格式且不使用 OCR
docling myfile.pdf --to json --to md --no-ocr
# 转换输入目录中的 PDF 文件为 Markdown(默认)
docling ./input/dir --from pdf
# 转换输入目录中的 PDF 和 Word 文件为 Markdown 和 JSON
docling ./input/dir --from pdf --from docx --to md --to json --output ./scratch
# 转换输入目录中所有支持的文件为 Markdown,遇到第一个错误时中止
docling ./input/dir --output ./scratch --abort-on-error项目地址
https://github.com/DS4SD/docling一个功能强大的文档解析和转换工具,支持PDF、DOCX、PPTX和Markdown等 - BTool博客 - 在线工具软件,为开发者提供方便