ChatGPT背后的技术和多模态异构数据处理的未来展望——我与一位资深工程师的走心探讨
上周,我和一位从业三十余年的工程师聊到ChatGPT。
作为一名人工智能领域研究者,我也一直对对话式大型语言模型非常感兴趣,在讨论中,我向他解释这个技术时,他瞬间被其中惊人之处所吸引🙌,我们深入探讨了ChatGPT的关键技术,他对我所说的内容产生了浓厚的兴趣,我们开始交流并分享了各自的经验。我发现,与这位资深工程师的讨论不仅加深了我的理解,也让我更加了解了这项技术的前沿发展🌱。
后续我也下面我将分享一些我在与工程师的讨论中和自己学习中所了解的ChatGPT的关键技术,希望对您有所帮助。
一、大规模语言模型
大规模语言模型(Large Language Models)是一类基于机器学习的自然语言处理技术,它能够对大量文本数据进行学习,从而生成一种对语言的抽象表示。
谈到大规模语言模型时,Transformers是一个不可避免的话题,可以说,大规模语言模型是自然语言处理领域的“流量入口”,而Transformer则是这一领域的“基石”。它们是如何相互作用的呢?
熟悉我的粉丝朋友们可能看过,我在早些时候总结的Transformer基础:横扫NLP 脚踏CV界的Transformer到底是什么 和 Transformer之十万个为什么。
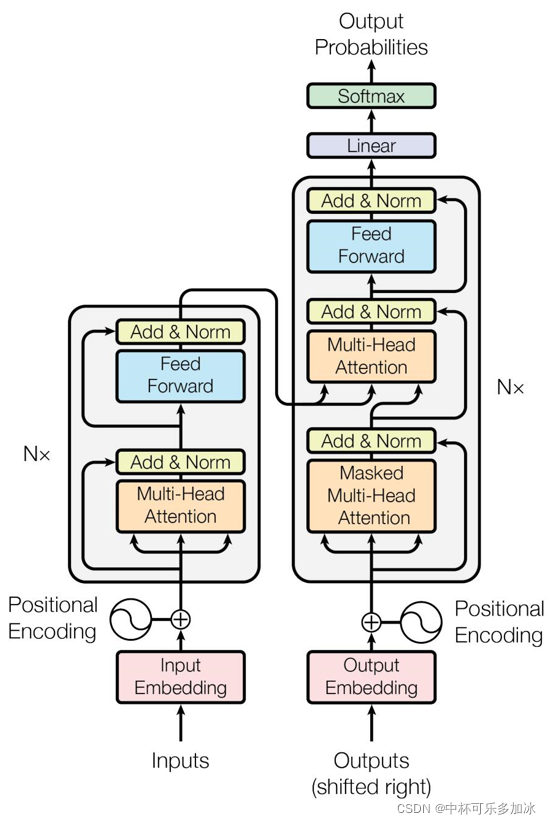
总结来说:Transformer是一种用于处理序列数据的神经网络架构,传统的CNN、RNN(或者LSTM,GRU)计算是顺序的、迭代的、串行的,即只能从左向右依次计算或者从右向左依次计算,而Transformer使用了位置嵌入 (Positional Encoding) 来理解语言的顺序,使用自注意力机制(Self Attention Mechanism)和全连接层进行计算,所有字都是同时训练,具有更好的并行性。
大规模语言模型通常采用深度学习算法,通过大量的语料库来预训练模型,使其能够“理解”自然语言中的语义、语法和上下文等信息。而Transformer则是一种特殊的深度学习模型,核心是自注意力机制(self-attention)。在传统的RNN或LSTM模型中,每个元素的表示只能从之前的元素获得信息,这就存在信息流动的局限性,而自注意力机制允许每个元素能够获得来自序列中其他元素的信息,从而更全面地捕捉序列之间的依赖关系。
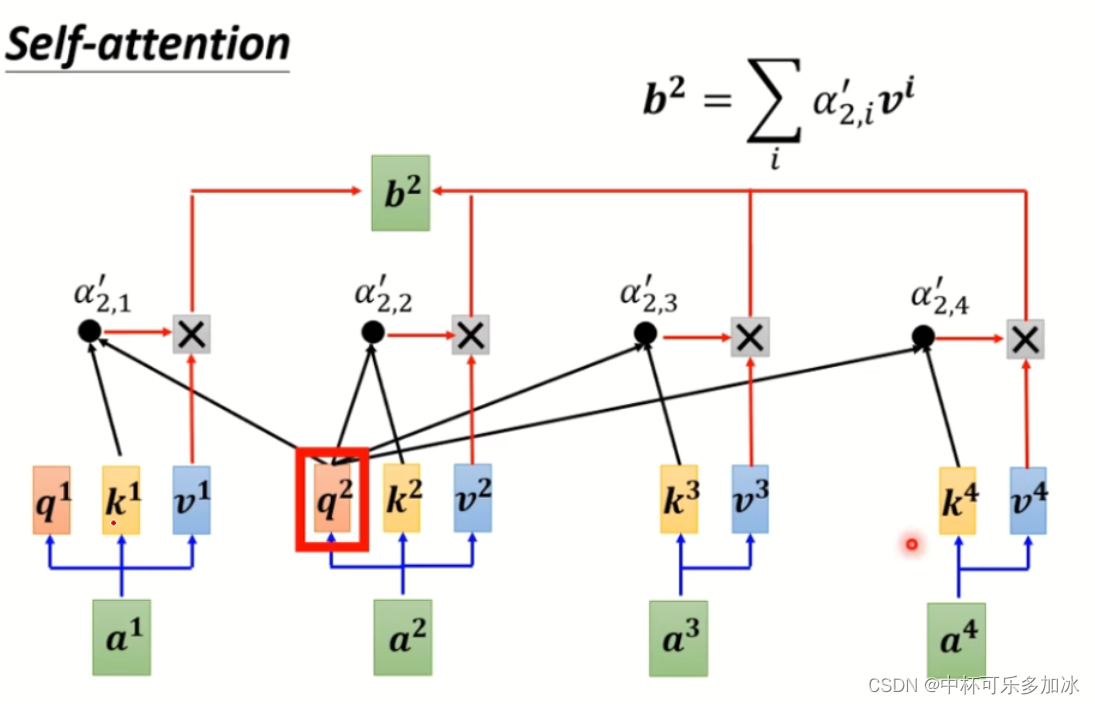
除了自注意力机制,Transformer还包括了一些其他的创新性组件,如多头自注意力、位置编码等。这些组件相互配合,使得Transformer模型能够在大规模语料上取得优秀的表现。
GPT 模型使用了 Transformer 的 Encoder 部分,Encoder 包括多个堆叠的自注意力机制(self-attention mechanism)层和前馈神经网络层。通过使用 Transformer 的自注意力机制,GPT 模型能够学习输入序列的上下文信息,并生成符合上下文的自然语言文本。
二、思维链
在聊天中,ChatGPT带给那位工程师另一项细思极恐的地方就是思维链。
思维链是指人们在思考或解决问题时,从一个概念或想法出发,逐步延伸联想,形成的一系列有机衔接的思维过程,基于大规模语言模型的自然语言处理技术。
它通过对文本数据进行训练,建立起词汇与概念之间的联系,每个词汇都被映射为一个高维向量,而这些向量之间的关系就是思维链的基础。通过对大量文本进行训练,模型学习到了不同词汇之间的关系,从而可以在输入一个词汇时,输出与之相关联的概念或其他词汇,进而构成一个完整的思维链。
试验时,我出了一道小学数学应用题,交给ChatGPT处理,可以看到,其不仅能够理解语言,更难得的是其能学习到应用数学的逻辑关系,并通过推理解决一定的问题。

可以说,ChatGPT作为一种基于Transformer结构的大规模语言模型,在构建思维链方面具有很高的优势。Transformer结构通过多层自注意力机制实现了文本序列中信息的交互和迭代,从而使得模型可以学习到更为复杂的词汇关系和语义表示。ChatGPT使用了非常大规模的训练数据和深度网络结构,可以处理大量的文本输入,从而更加精确地建立思维链。
三、强化学习
为了训练 ChatGPT 让其给出的答案更贴近人类,它在发布前采取了一种叫做“基于人类反馈的强化学习”的训练策略,当我们在使用ChatGPT这样的大规模语言模型进行对话时,我们的目标是让模型能够理解我们的意图,并作出合适的回应。这个过程中,模型需要从已有的数据中学习到哪些回应更能够符合用户的期望,这就是强化学习的策略。
智能体通过不断地试错学习,更新其策略,以最大化其获得累积奖励的期望值。这种学习过程可以通过价值函数来实现,价值函数可以分为状态价值函数和动作价值函数。在训练过程中,智能体通过对状态价值函数和动作价值函数进行更新来提高策略的性能。
强化学习是机器学习中的另一种学习方式,目标是让机器能够在与环境交互的过程中通过试错来学习如何最大化奖励,从而达到特定的目标。在强化学习中,机器不会像监督学习那样依赖于已有的标注数据,而是通过与环境的交互来获取实时的反馈和奖励,并根据这些反馈和奖励来调整自己的行为。
强化学习的核心思想是基于马尔可夫决策过程(Markov Decision Process,MDP)。在MDP中,智能体与环境交互的过程可以用一个五元组(S,A,R,P,γ)来描述。
M D P = ( S , A , P , R , γ ) \mathrm{MDP}=(\mathrm{S}, \mathrm{A}, \mathrm{P}, \mathrm{R}, \gamma) MDP=(S,A,P,R,γ)其中,S是状态(state)集,A是行为(action)集 ,R是奖励函数,P是状态转移概率(state transference概率)矩阵,γ是衰减因子。
在强化学习中,有两种基本的学习方法:值函数学习和策略梯度学习。值函数学习通过学习一个值函数来估计每个状态的价值,并选择具有最高值的操作。策略梯度学习直接优化策略函数,即在给定状态下采取的操作。这两种方法都有各自的优缺点,可以根据应用场景选择合适的方法。
那么在与ChatGPT这样的大规模语言模型进行对话时,强化学习可以如何应用呢?一个常见的例子是使用强化学习来优化聊天机器人的回答质量。在这个过程中,机器会与用户进行多轮对话,每一轮都会根据用户的意图和回答的质量获得相应的奖励,同时机器也会根据自己的行为和环境的变化调整自己的策略,以期望获得更高的奖励。
除了自然语言处理方面,强化学习在图像处理、游戏玩法和机器人控制等领域都有广泛的应用。
四、未来展望——多模态异构数据处理
模态是指某件事情发生或经历的方式。每一种信息的来源或者形式,都可以称为一种模态。人类对世界的体验是多模态的例如触觉,听觉,视觉,嗅觉;而人类获取信息的媒介,有语音、视频、文字等;
为了让人工智能在理解我们周围的世界方面取得进展,它需要能够一起解释这种多模态信号。多模态机器学习旨在建立能够处理和关联来自多种模态的信息的模型。
当今的社交媒体中,包含了海量非合作、异构化、跨模态的数据,既蕴藏了大量的人类知识与高价值信息,也包含了各种自然与人为的噪声,对其分析与处理需要融合类脑计算、计算机视觉、自然语言处理等多个维度的智能技术。
谈及多模态异构数据处理,我们不得不提到现代数据处理中的一个热点领域——图文智能处理与多场景应用技术。近年来,这一领域得到了快速发展,应用也在不断拓展。
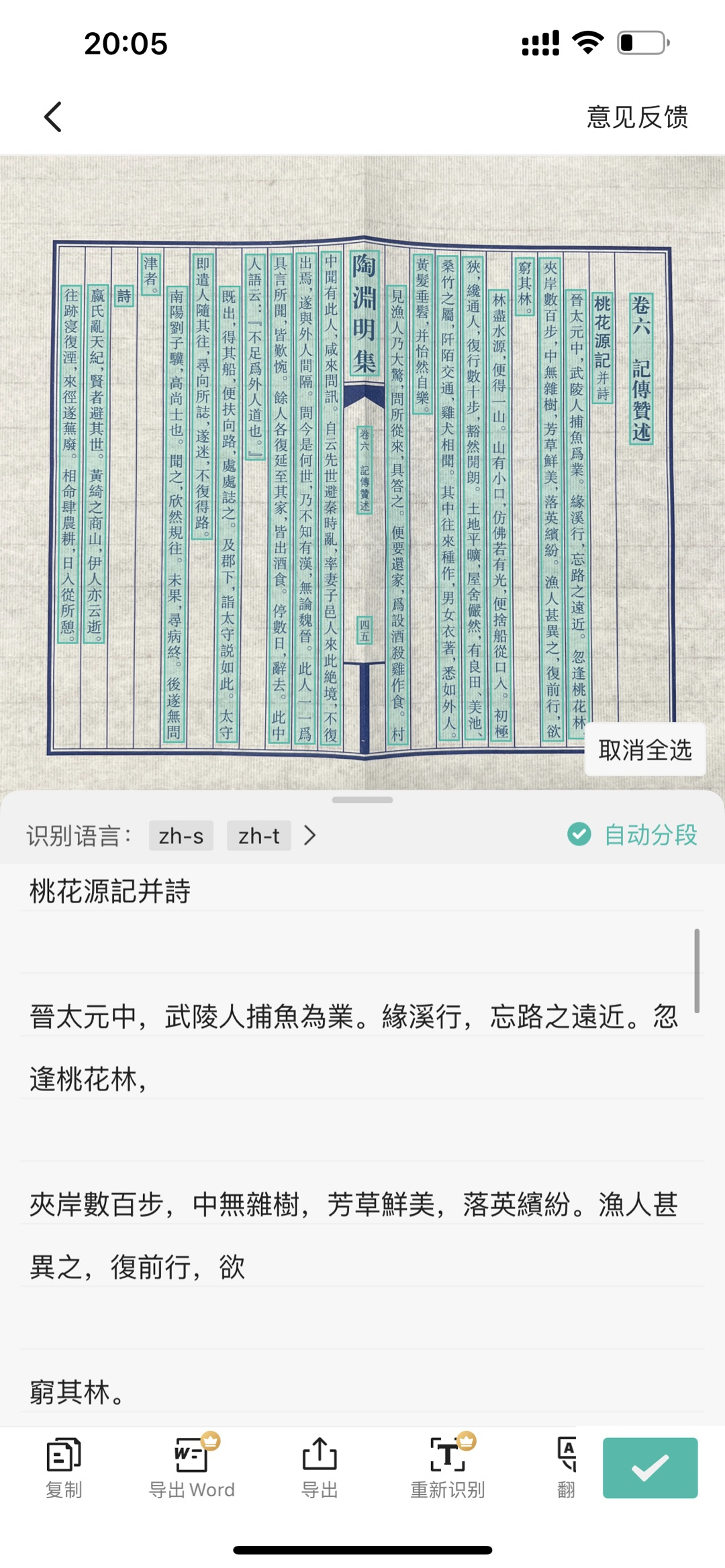
图像和文本是我们最常接触的两种模态,随着OCR技术应用的不断深入,面向图像文档中复杂结构(如汉字结构,表格结构,文档总体结构等)的建模问题也已经逐渐成为研究热点之一,如上图,用扫描全能王的“拍图识字”功能一键扫描识别竖排繁体古籍《桃花源记》,面对破损、皱褶的古籍,该功能通过分析图像图像文档复杂结构,进一步将古籍内容提取出来,赋予更加清晰、平整的古籍阅读体验。
图文智能处理与多场景应用技术不仅仅局限于图像图形领域,也涉及到自然语言处理、视频处理、人工智能等多个领域,未来可能会出现大量的、碎片化的应用范围,比如图像转文字,智能文档识别,文本生成头像、诗文、甚至短视频等,重点是在有趣的细分场景里发挥创造性和想象力。
在这个背景下,我也非常巧合地收到了CSIG图像图形企业行活动的邀请。
活动由中国图象图形协会(CSIG)主办,合合信息、CSIG文档图像分析与识别专业委员会在3月18日联合承办。华南理工金连文教授、上海交大杨小康教授、复旦邱锡鹏教授、厦大纪荣嵘教授、中科大杜俊教授、合合信息郭丰俊博士等顶尖专家们将交流分享对于图像文档处理中的结构建模、底层视觉技术、跨媒体数据协同应用、生成式人工智能及对话式大型语言模型等技术的展望。
在上海的朋友们可以点击链接:https://qywx.wjx.cn/vm/rhE9BxC.aspx线下参会!
不在上海的朋友们也可以通过直播间,预约观看,活动干货多多,全程亮点,本周六下午14.00,欢迎大家关注!
会后还有答疑环节,各位有什么想问的问题可以在评论区留言,我到时候线下可以面对面提问哦!,
参考文献
人人都能懂的ChatGPT解读[https://new.qq.com/rain/a/20230226A02Y7B00]
💡 最后
我们已经建立了🏤T2I研学社群,如果你还有其他疑问或者对🎓ChatGPT或者文本生成图像很感兴趣,可以私信我加入社群。
🎉 支持我:点赞👍+收藏⭐️+留言📝