【计算机视觉】图像分类模型
VIT
输入size,(4,3,256,256) ,为了序列化输入进 transformer 中,利用 patch 进行分块。patch_size=32。
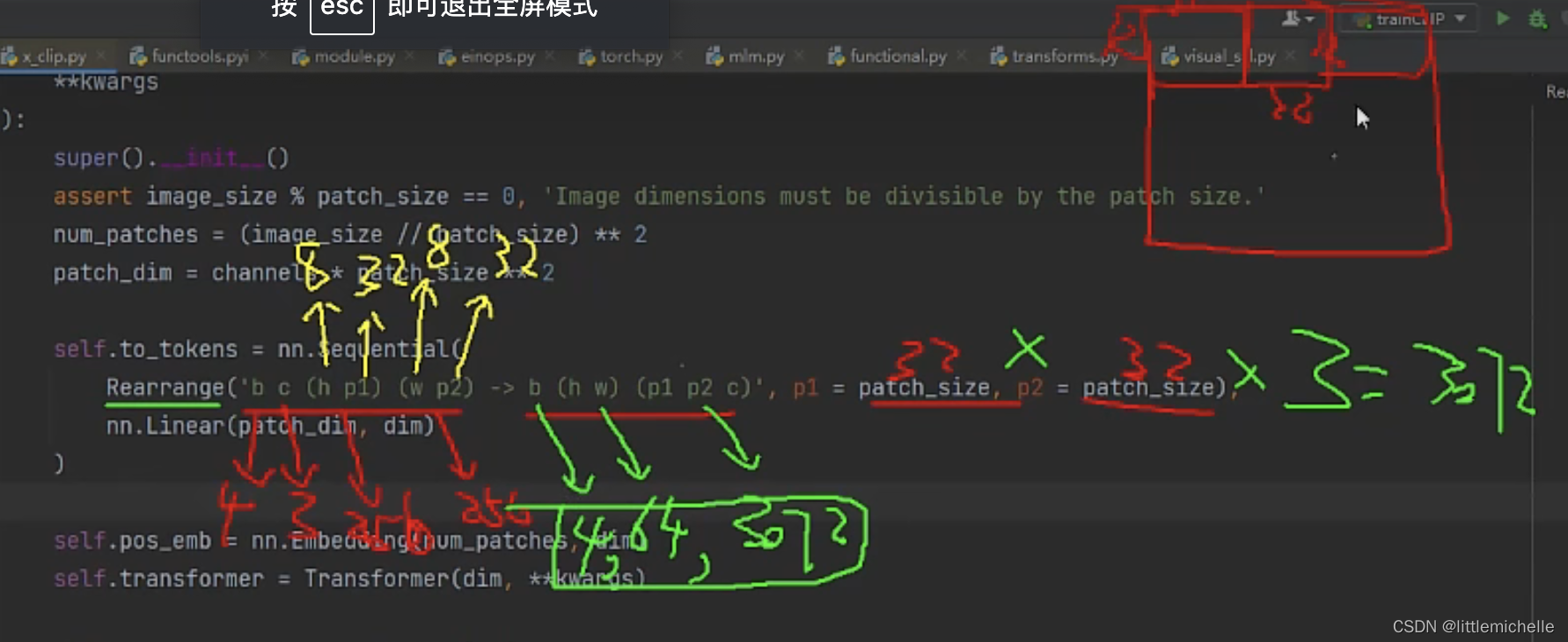
(4,3,256,256) -> b c (h p1) (w p2) -> 4,3, 8 32 8 32 # 256/32=8
-> b (h w) (p1 p2 c) -> 4 64 3072 # 32*32*3=3072
4是 batchsize 是不变的。64是图像所划分的小块,相当于64个 token。
3072是每个小块的向量维度。
 + pos_emb 位置编码
+ pos_emb 位置编码

经过transformer 特征提取后,得到 out # 4,64,512(64个位置)
to_cls_tokens(out) 求全局特征,cls_to_tokens=4,1,512
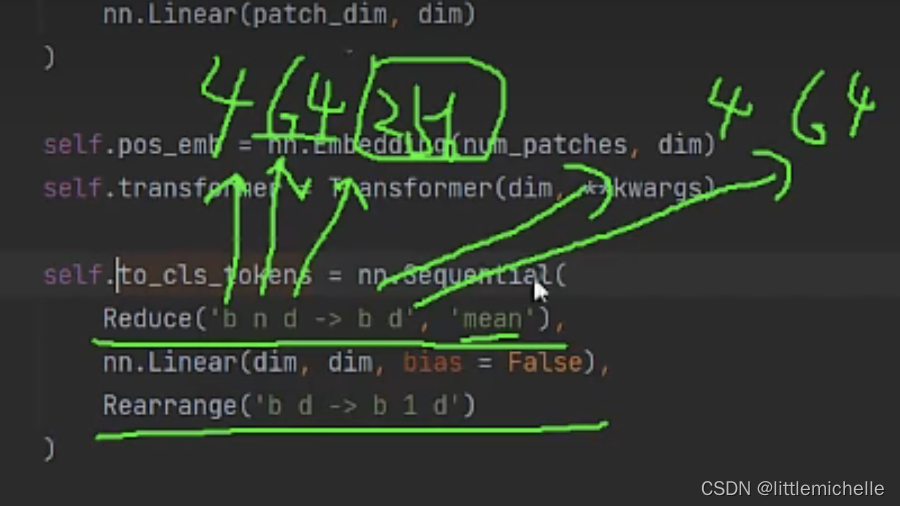
最终得到 4,65,512。。。走几个全连接, 得到260,128。
在 CLIP 中相当于,同一张图片,图像数据增强后,第一个图片 经过 VIT 进行特征提取,返回特征 query 160,128;第二个图片 经过 VIT 进行特征提取,返回特征 key 160,128
在batch=4的情况下,怎么算既有正样本又有负样本呢?
4个图片,分别是猫、狗、猪、鸭。key1,query1是猫通过图像增强得到的2个图片;key2,query2是狗通过图像增强得到2个图片。
key1,query1是互为正样本;
key2,query2是互为正样本;
(key1,key2) 、 (key1,query2) 都是负样本
但不知道通过 nt_xent_loss 是如何实现的

VIT里会更细致,具体到每个块(腿、眼睛)像不像。
260=4*65(全局特征1+64个位置特征?是叫位置特征吗?)
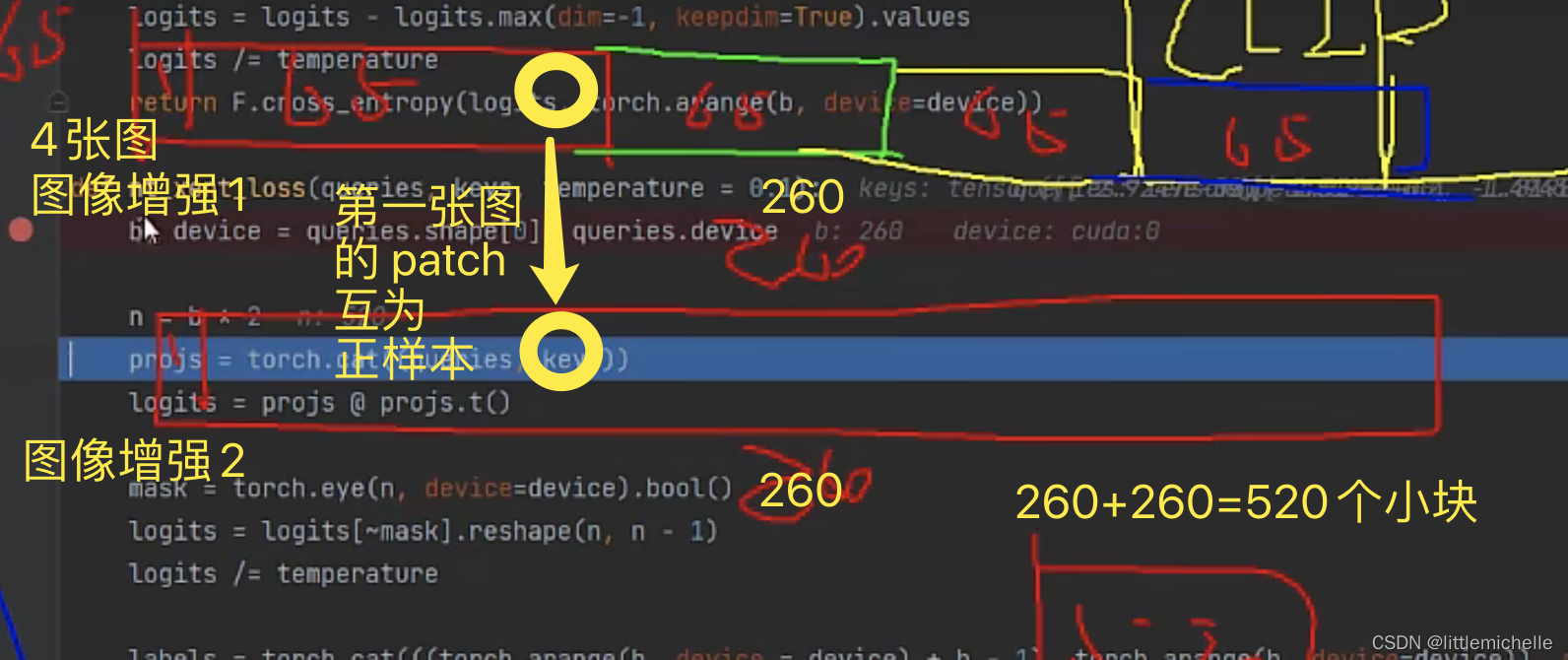
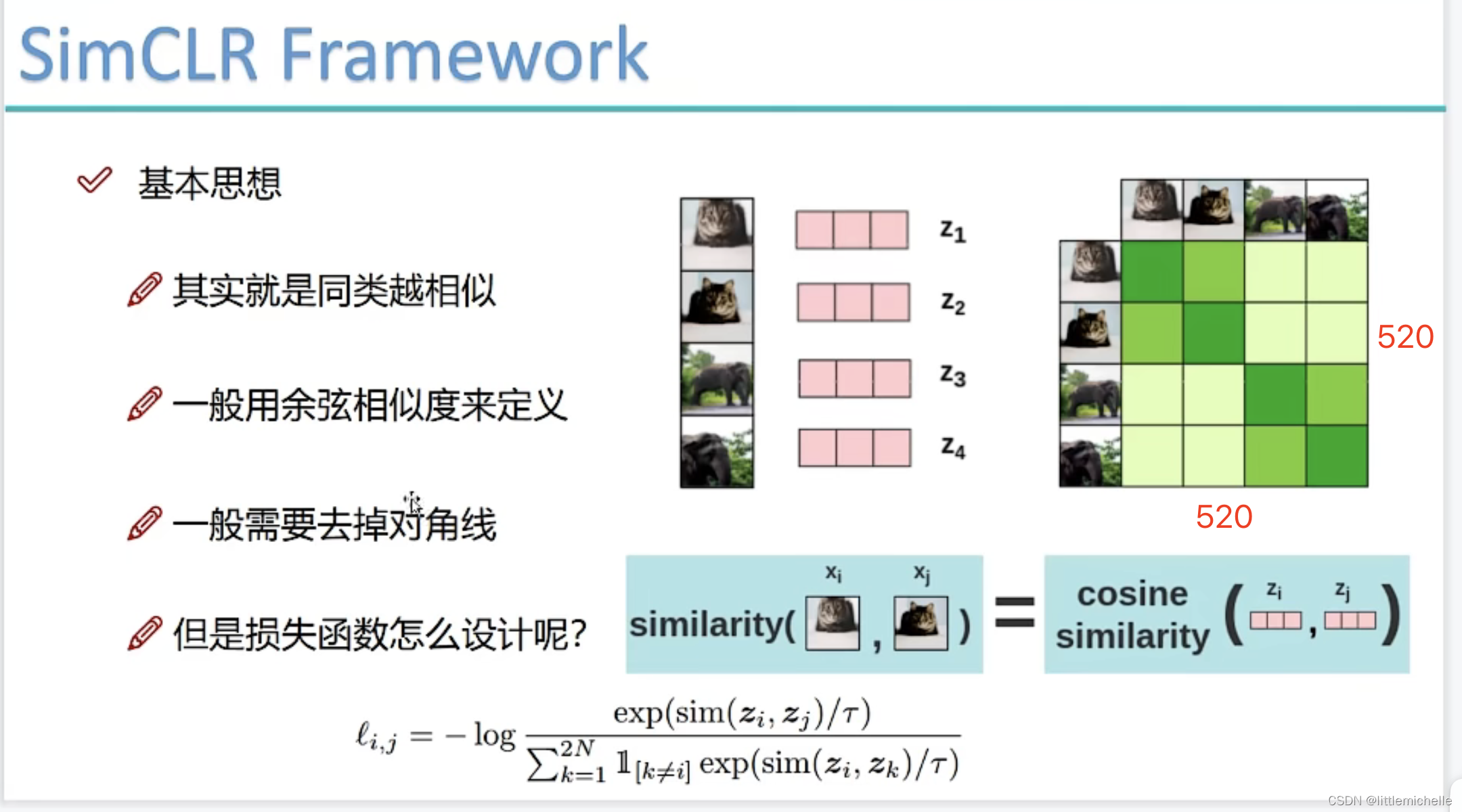
得到520*520的矩阵,代表每一个小块和其余小块的关系。不能考虑自己,去掉对角线,得到520*519。
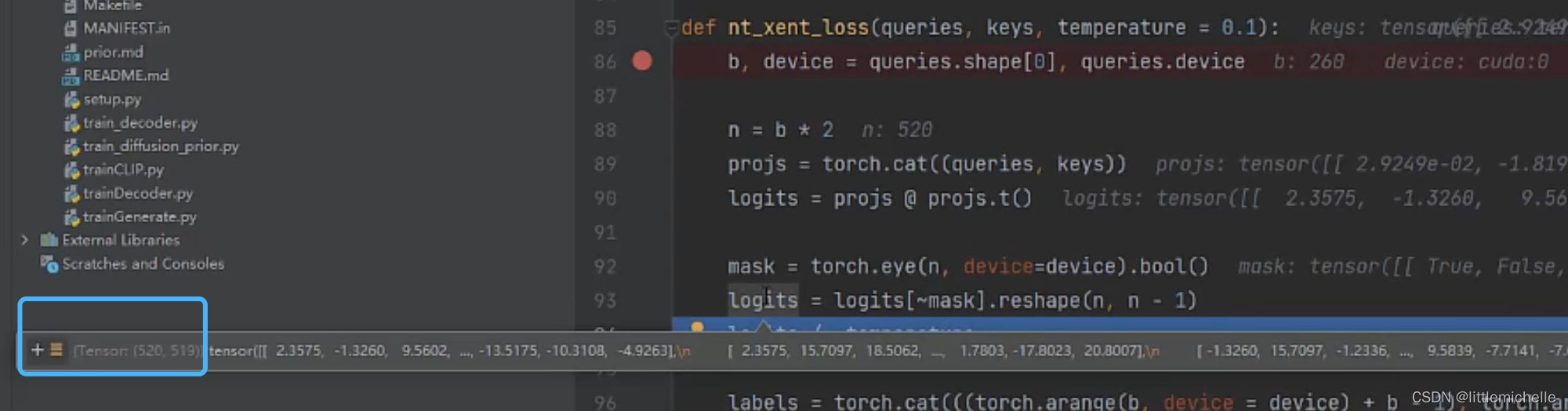 temperature 温度系数,扩大 softmax 的差异。
temperature 温度系数,扩大 softmax 的差异。
正样本的标签是自动生成的。总长520。259配对0。
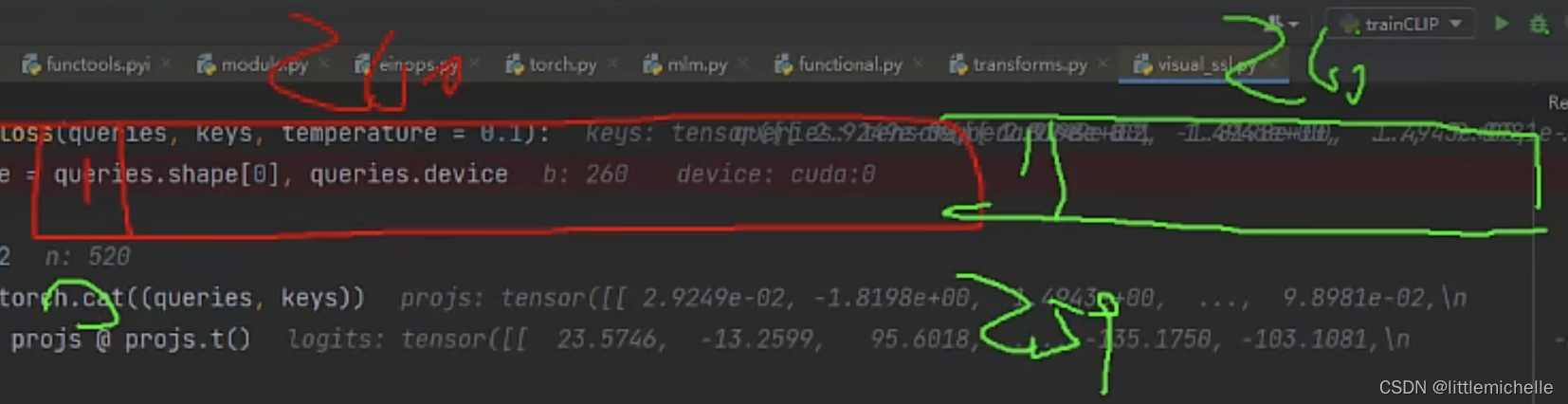 labels如下,518-259+1=260
labels如下,518-259+1=260
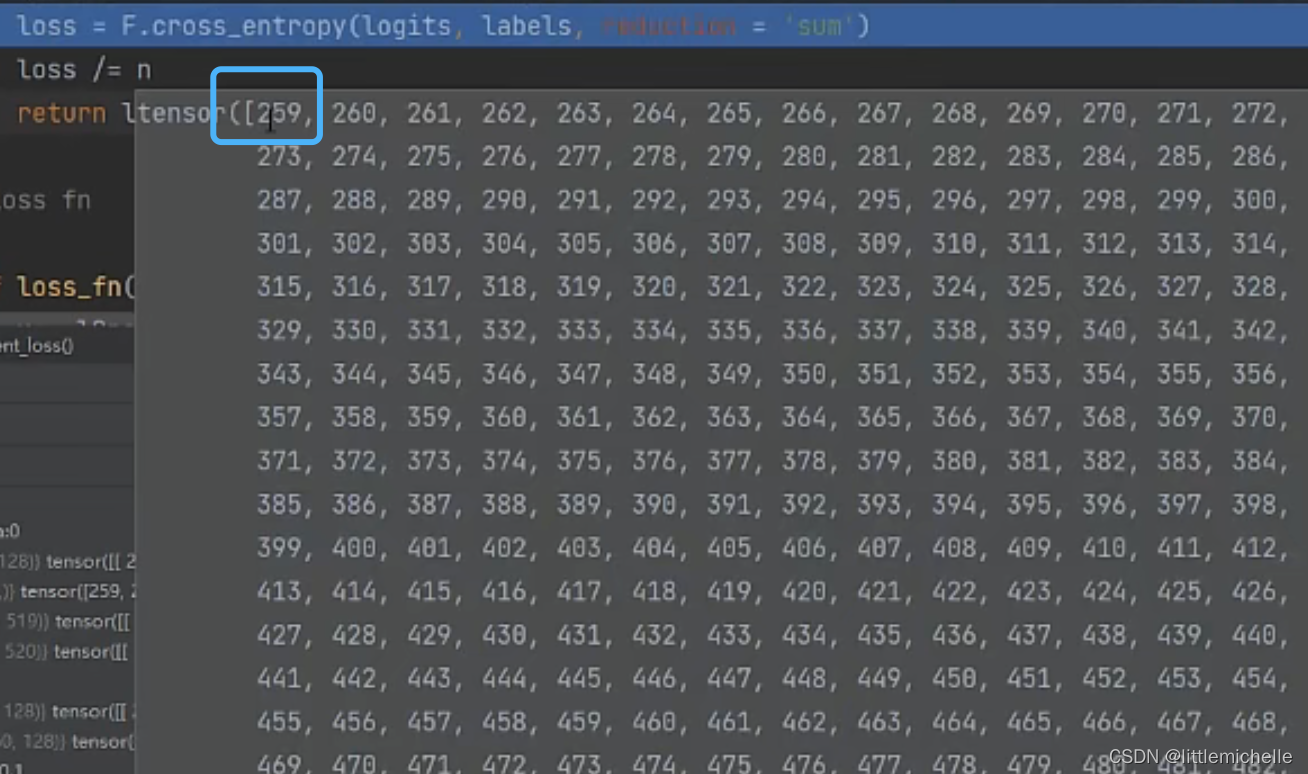

loss=F.cross_entropy(logits, labels, reduction='sum')
loss/=n # n=520,求平均损失
logits # 520,519
labels # 259,260
CLIP
文本模型内部做完形填空,mask language model。-> enc_text
图像模型内容做 simCLR 利用vit做对比学习。-> enc_image
enc_text与enc_image再做对比学习
text_embeds=enc_text[;,0] # 0是'CLS',全局特征,4,512
images_embeds=enc_image[;,0] # 4,512,我理解应该是4,65,512求均值得到4,512 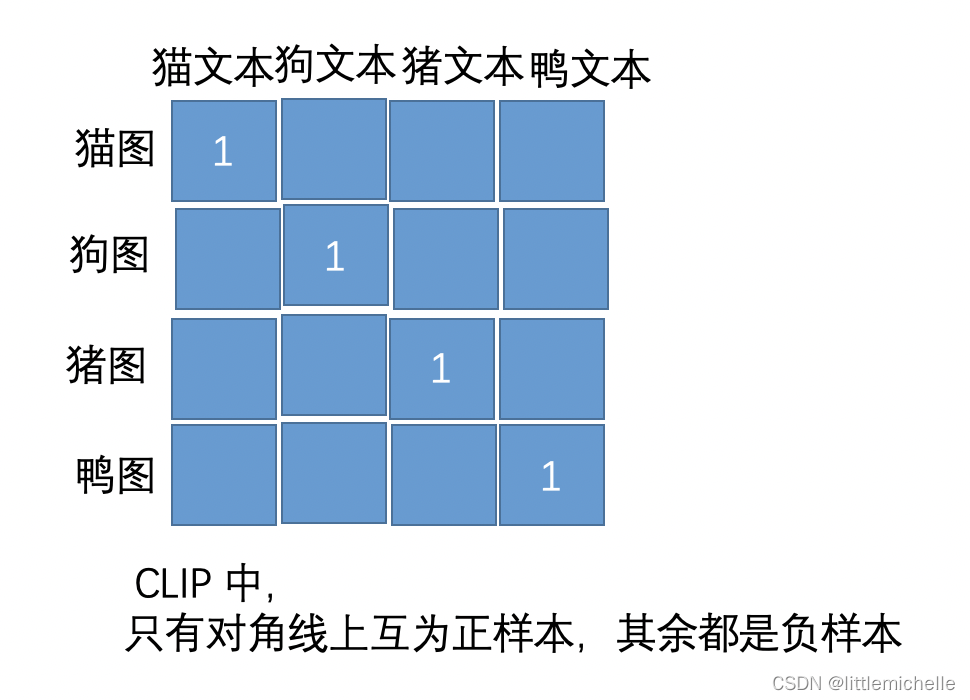
# t - sequence dimension along text tokens
# i - sequence dimension along image tokens
text_to_iamge = einsum('t d, i d - > t i', text_latentes, image_latentes) * temp
# text_latentes 4,512
# image_latentes 4,512
# text_to_iamge 4,4 # 4个文本和4个图像之间的关系
image_to_text = rearrange(text_to_image, '... t i -> ... i t')
# text_to_iamge 4,4 # 4个图像和4个文本之间的关系【对比学习有多火?文本聚类都被刷爆了!通俗易懂的讲解让我直接悟了啊!】 https://www.bilibili.com/video/BV1iR4y1R7dH/?share_source=copy_web&vd_source=694333d73ad23f4f70f7df5508d4f30a