Spark 之 解析json的复杂和嵌套数据结构
本文主要使用以下几种方法:
1,get_json_object():从一个json 字符串中根据指定的json 路径抽取一个json 对象
2,from_json():从一个json 字符串中按照指定的schema格式抽取出来作为DataFrame的列
3,to_json():将获取的数据转化为json格式
4,explode():炸裂成多行
5,selectExpr():将列转化为一个JSON对象的另一种方式
文件名是 mystudent.txt 具体内容如下,只有一条数据
1|{"dept":{"describe":"主要负责教学","name":"学术部"},"email":"zhangsan@edu.cn","id":79,"name":"zhangsan","stus":[{"grade":"三年级","id":12,"name":"xuesheng1","school":{"address":"南京","leader":"王总","name":"南京大学"}},{"grade":"三年级","id":3,"name":"xuesheng2","school":{"address":"南京","leader":"王总","name":"南京大学"}},{"grade":"三年级","id":1214,"name":"xuesheng3","school":{"address":"南京","leader":"王总","name":"南京大学"}}],"tel":"1585050XXXX"}
大概是这样的结构:

第一步:导入文件并分割成二元组转换成两列
val optionRDD: RDD[String] = sc.textFile("in/mystudent.txt")
optionRDD.foreach(println)
//分割,注意 | 用的是单引号
val option1: RDD[(String, String)] = optionRDD.map(x => {
val arr = x.split('|');
(arr(0), arr(1))
})
option1.foreach(println)
//转化成两列
val jsonStrDF: DataFrame = option1.toDF("aid", "value")
jsonStrDF.printSchema()
jsonStrDF.show(false)
第二步:按照几个大类先拆分
val jsonObj: DataFrame = jsonStrDF.select(
$"aid"
, get_json_object($"value", "$.dept").as("dept")
, get_json_object($"value", "$.email").as("email")
, get_json_object($"value", "$.id").as("tid")
, get_json_object($"value", "$.name").as("tname")
, get_json_object($"value", "$.stus").as("stus")
, get_json_object($"value", "$.tel").as("tel")
)
println("--------------------------1--------------------------")
jsonObj.printSchema()
jsonObj.show(false)
第三步:把dept这个部分再分
val jsonObj2: DataFrame = jsonObj.select($"aid", $"email"
, $"tid", $"tname"
, get_json_object($"dept", "$.describe").as("describe")
, get_json_object($"dept", "$.name").as("dname")
, $"stus", $"tel"
)
println("--------------------------2--------------------------")
jsonObj2.printSchema()
jsonObj2.show(false)
第四步:把stus这部分合并成数组
val fileds: List[StructField] =
StructField("grade", StringType) ::
StructField("id", StringType) ::
StructField("name", StringType) ::
StructField("school", StringType) :: Nil
val jsonObj3: DataFrame = jsonObj2.select(
$"aid", $"describe", $"dname", $"email", $"tid", $"tname"
, from_json($"stus", ArrayType(
StructType(
fileds
)
)
).as("events")
)
println("--------------------------3--------------------------")
jsonObj3.printSchema()
jsonObj3.show(false)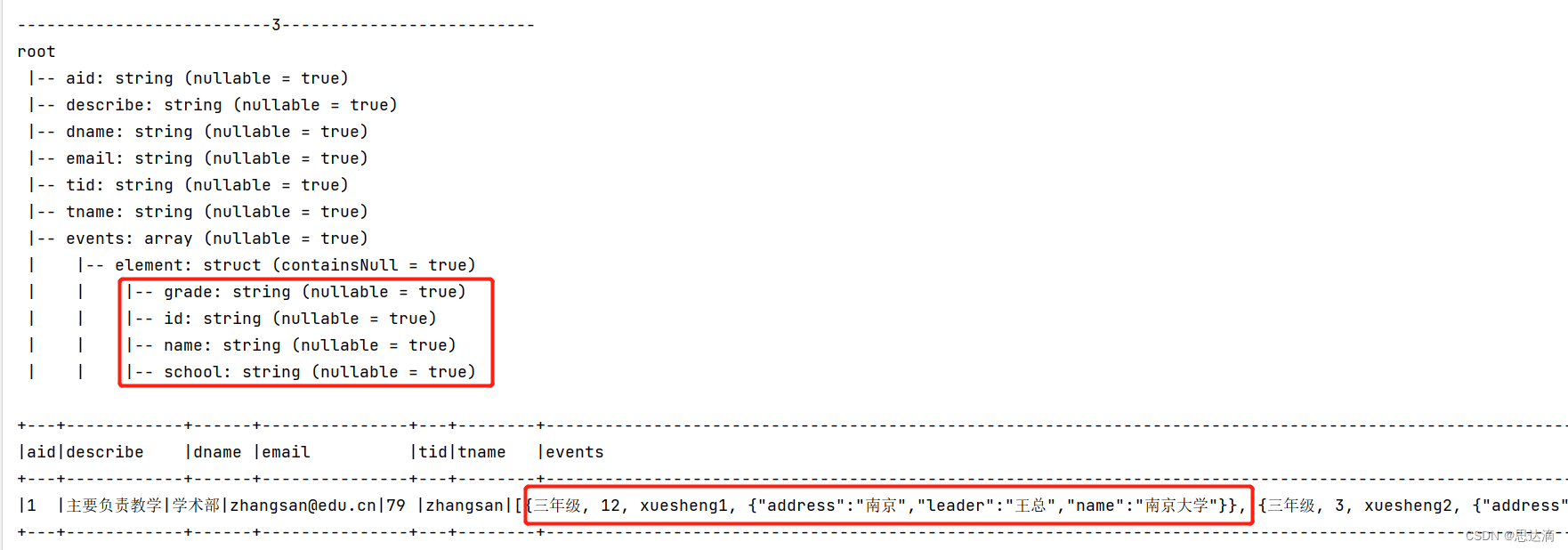
第五步:explode炸裂stus 部分,分成三部分;并新增列,删除原数组数据
//炸裂
val jsonObj4: DataFrame = jsonObj3.withColumn("events", explode($"events"))
println("--------------------------4--------------------------")
jsonObj4.printSchema()
jsonObj4.show(false)
//新增列,删除原数据
val jsonObj5: DataFrame = jsonObj4.withColumn("grade", $"events.grade")
.withColumn("id", $"events.id")
.withColumn("name", $"events.name")
.withColumn("school", $"events.school")
.drop("events")
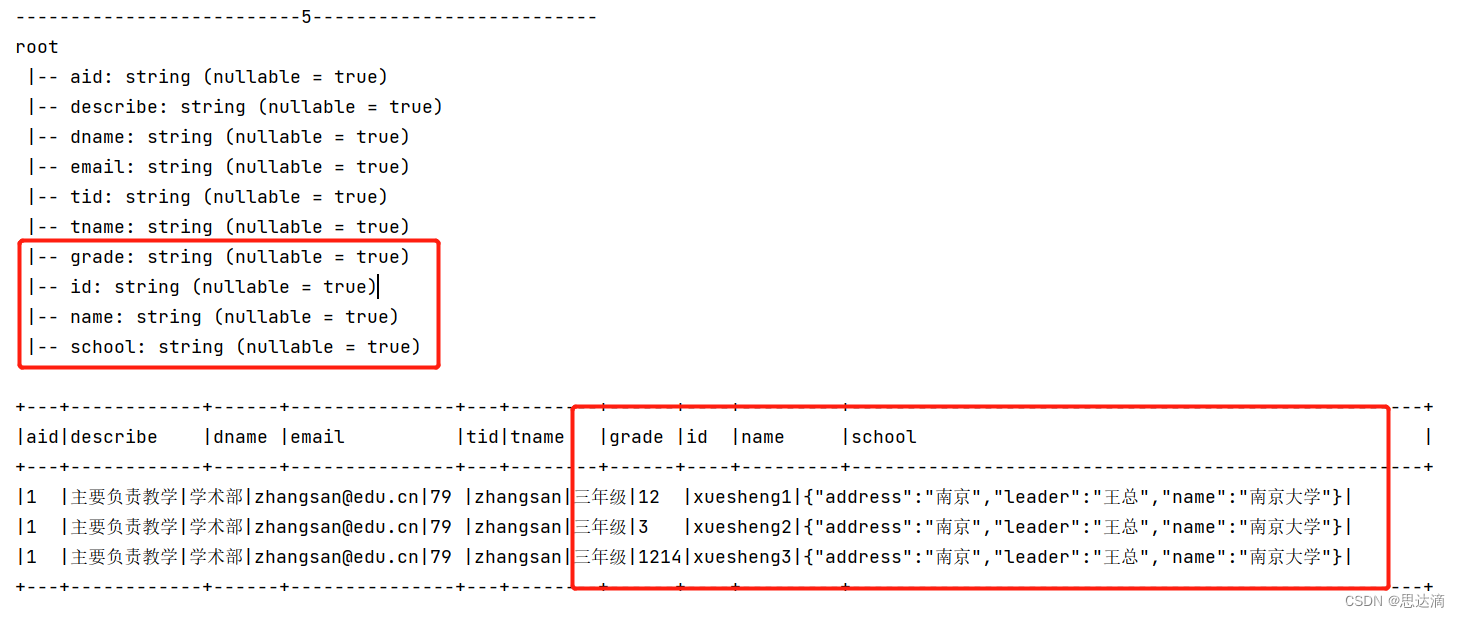
println("--------------------------5--------------------------")
jsonObj5.printSchema()
jsonObj5.show(false)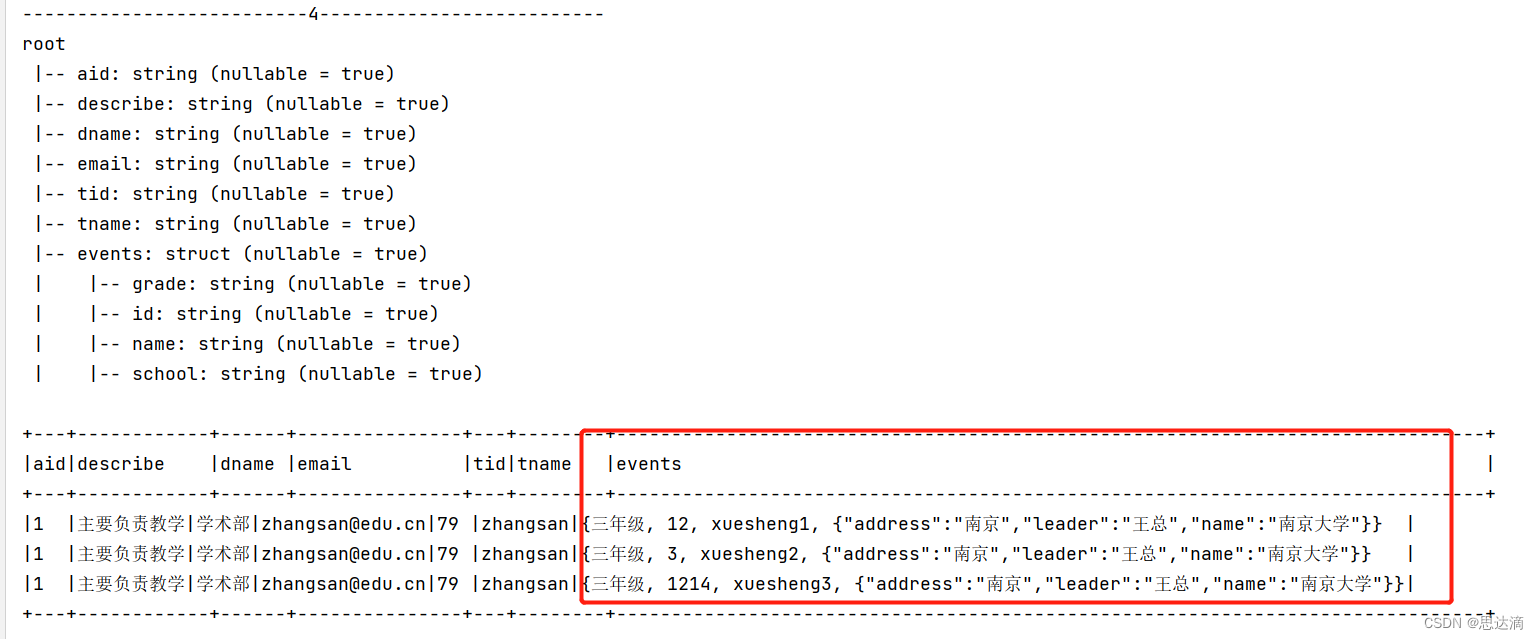
第六步:分开school部分,并合并全表
val jsonObj6: DataFrame = jsonObj5.select($"aid", $"describe"
, $"dname", $"email",$"tid",$"tname",$"grade",$"id",$"name",
get_json_object($"school","$.address").as("address")
,get_json_object($"school","$.leader").as("leader")
,get_json_object($"school","$.name").as("schoolname"))
println("--------------------------6--------------------------")
jsonObj6.printSchema()
jsonObj6.show(false)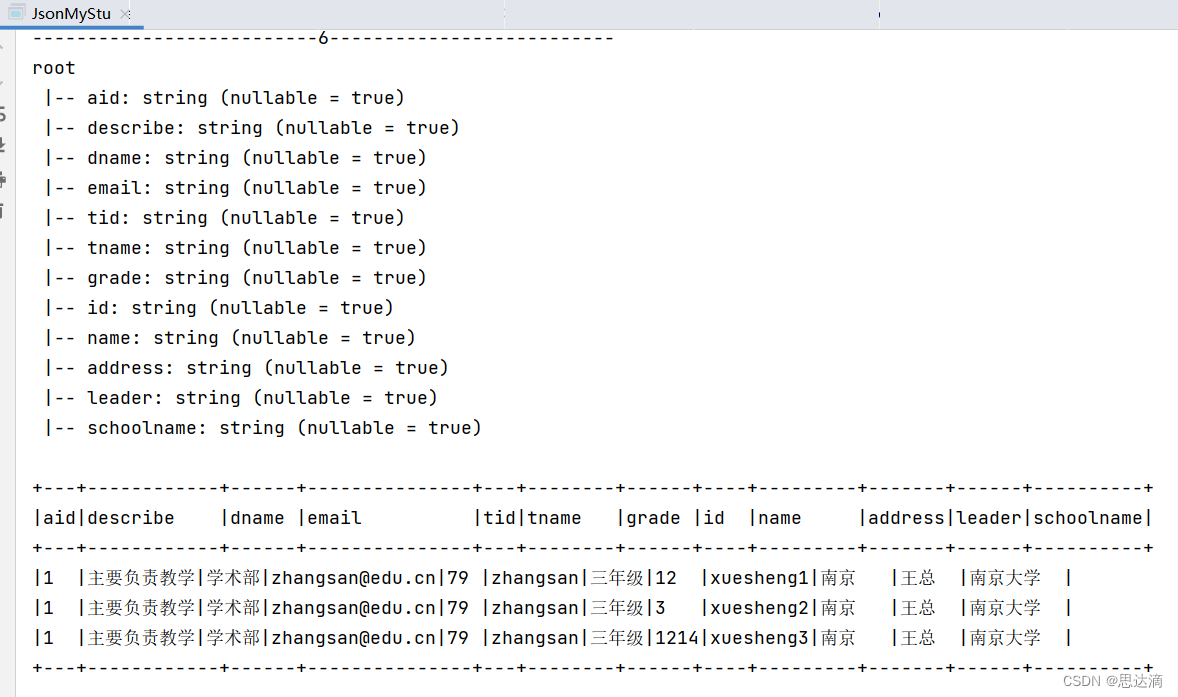
总结,全文代码如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, SparkSession}
object JsonMyStu {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("jsonstu3opdemo").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val sc: SparkContext = spark.sparkContext
import spark.implicits._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
val optionRDD: RDD[String] = sc.textFile("in/mystudent.txt")
optionRDD.foreach(println)
//按照 | 分割成两列
val option1: RDD[(String, String)] = optionRDD.map(x => {
val arr = x.split('|');
(arr(0), arr(1))
})
option1.foreach(println)
val jsonStrDF: DataFrame = option1.toDF("aid", "value")
jsonStrDF.printSchema()
jsonStrDF.show(false)
val jsonObj: DataFrame = jsonStrDF.select(
$"aid"
, get_json_object($"value", "$.dept").as("dept")
, get_json_object($"value", "$.email").as("email")
, get_json_object($"value", "$.id").as("tid")
, get_json_object($"value", "$.name").as("tname")
, get_json_object($"value", "$.stus").as("stus")
, get_json_object($"value", "$.tel").as("tel")
)
println("--------------------------1--------------------------")
jsonObj.printSchema()
jsonObj.show(false)
val jsonObj2: DataFrame = jsonObj.select($"aid", $"email"
, $"tid", $"tname"
, get_json_object($"dept", "$.describe").as("describe")
, get_json_object($"dept", "$.name").as("dname")
, $"stus", $"tel"
)
println("--------------------------2--------------------------")
jsonObj2.printSchema()
jsonObj2.show(false)
val fileds: List[StructField] =
StructField("grade", StringType) ::
StructField("id", StringType) ::
StructField("name", StringType) ::
StructField("school", StringType) :: Nil
val jsonObj3: DataFrame = jsonObj2.select(
$"aid", $"describe", $"dname", $"email", $"tid", $"tname"
, from_json($"stus", ArrayType(
StructType(
fileds
)
)
).as("events")
)
println("--------------------------3--------------------------")
jsonObj3.printSchema()
jsonObj3.show(false)
val jsonObj4: DataFrame = jsonObj3.withColumn("events", explode($"events"))
println("--------------------------4--------------------------")
jsonObj4.printSchema()
jsonObj4.show(false)
val jsonObj5: DataFrame = jsonObj4.withColumn("grade", $"events.grade")
.withColumn("id", $"events.id")
.withColumn("name", $"events.name")
.withColumn("school", $"events.school")
.drop("events")
println("--------------------------5--------------------------")
jsonObj5.printSchema()
jsonObj5.show(false)
val jsonObj6: DataFrame = jsonObj5.select($"aid", $"describe"
, $"dname", $"email",$"tid",$"tname",$"grade",$"id",$"name",
get_json_object($"school","$.address").as("address")
,get_json_object($"school","$.leader").as("leader")
,get_json_object($"school","$.name").as("schoolname"))
println("--------------------------6--------------------------")
jsonObj6.printSchema()
jsonObj6.show(false)
}
}拓展:
//如果分割符是 , 则用以下方法,indexOf返回第一个此元素的下标值
/*val optinRDD: RDD[String] = sc.textFile("in/mystudent.txt")
optinRDD.foreach(println)
val frame: RDD[(String, String)] = optinRDD.map(
x => {
//返回第一个,所在的位置
val i: Int = x.indexOf(",")//1
//开始截取
//(0,i)--->(0,1)
//(i+1) 2 从下标元素开始到末尾
val tuple: (String, String) = (x.substring(0, i), x.substring(i + 1))
tuple
}
)*/