chapter-4-数据库语句
以下课程来源于MOOC学习—原课程请见:数据库原理与应用
考研复习
概述
SQL发展
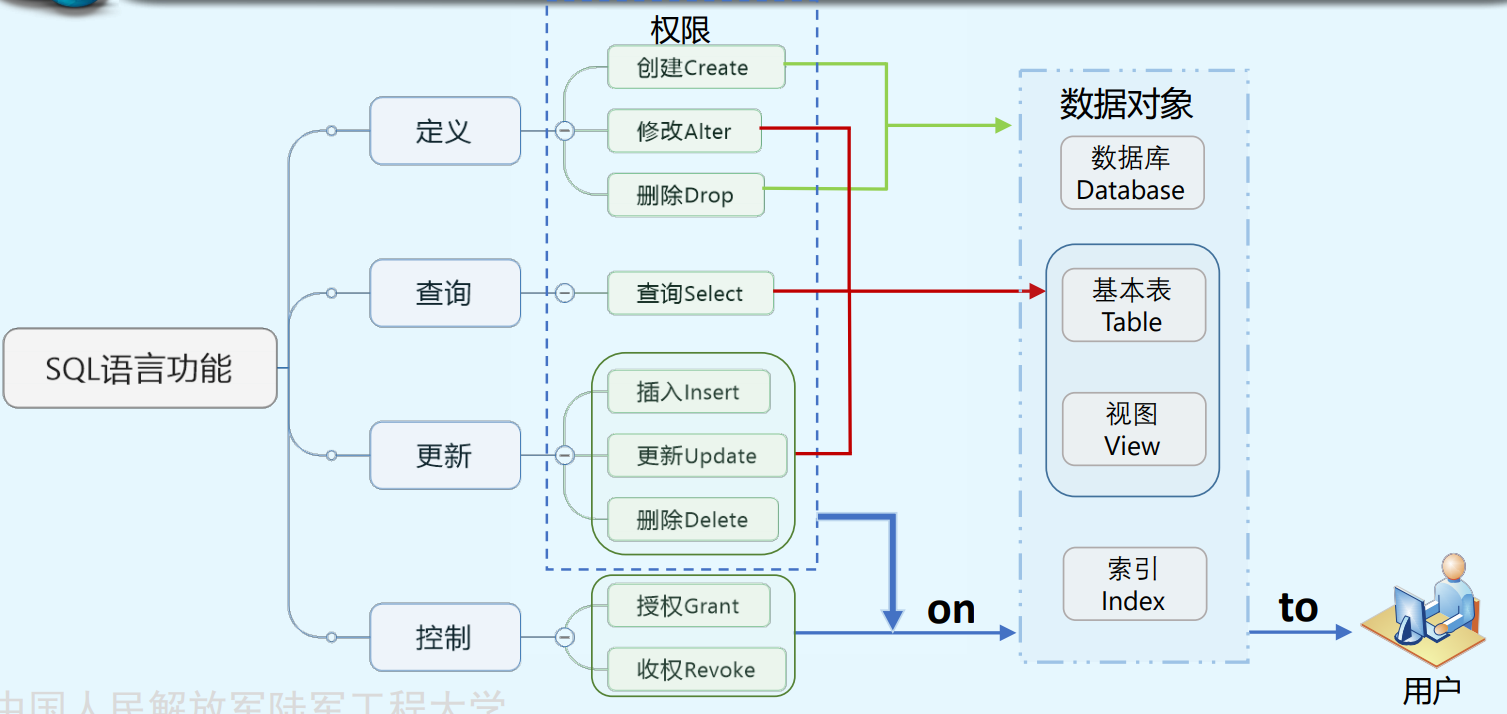
注:关键词是哪些功能,尤其第一个create alter drop是定义功能
1.SQL功能强大,实现了数据定义、数据操纵、数据控制等功能
2.SQL语言简洁,只用少量的动词就实现了核心功能
3.SQL支持关系数据库的三级模式结构
4.SQL语言能嵌入到其他高级语言所写的程序中
注:语句格式

补充:模式 create/drop schema <模式名> authorization <用户名> 定义模式=定义命名空间,可以进一步定义数据库对象等
补充:索引:create/drop [ unique/cluster ] index <索引名> on <表名>(…列)
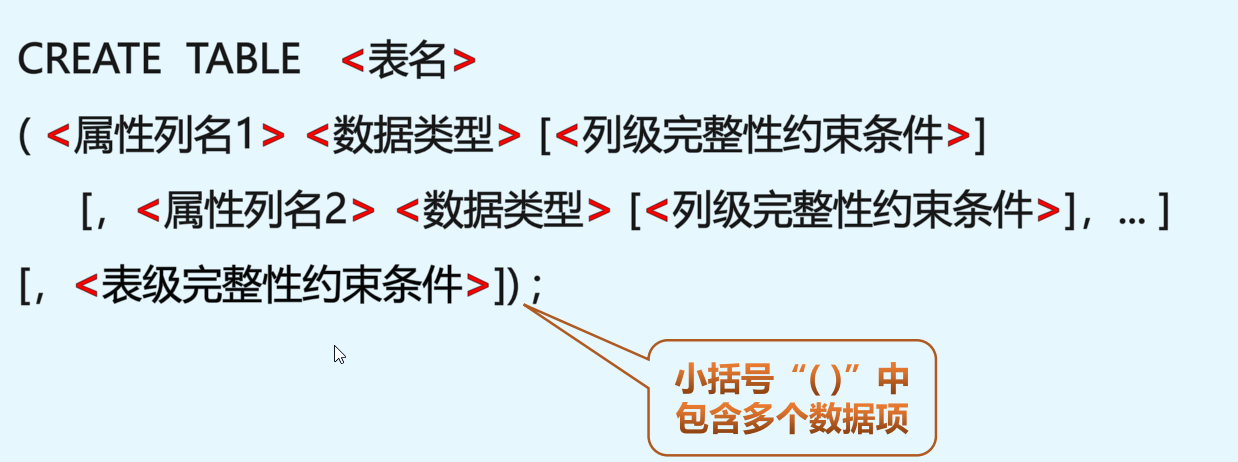
基本表定义创建
#创建数据库
create database <数据库名>
#打开数据库
use <数据库名>
#创建表
create table <表名> (
<属性名> <类型> [约束性条件],
<属性名> <类型> [约束性条件]
)
#主键
sno char(6) primary key
#单独约束主键【多个外键时仅此一种方法】
primary key(sno,cno)
#外键
FOREIGN key(sno) references S(sno)
#后续添加外键级联操作--级联更新|不操作
# ON UPDATE{cascade| NO ACTION}:
# ON DELETE{cascade| NO action}:
#用户定义
SN CHAR(10) NOT NULL,
SEX CHAR(2) DEFALUT'男'
check(sex in('男','女'))
check(GRADE between 0 and 100)
SEX CHAR(2) UNIQUE
create table s(
sno VARCHAR(100) PRIMARY KEY,
sn VARCHAR(100),
sd VARCHAR(100),
sb VARCHAR(100),
sex VARCHAR(100) DEFAULT '男'
CHECK (sex in ('男','女'))
)
基本表修改
增加列
alter table <表名>
add <属性名> <类型>
#增加约束规则
alter table <表名>
add PRIMARY KEY (SNO);
#改变某列的类型
alter table <表名>
add column <属性名> <类型>
#删除原有的列或者约束规则
alter table <表名>
drop column <列名> [CASCADE| RESTRICT]
#RESTRICT没有视图或者约束引用该属性时,该属性列才可以删除
#CASCADE删除某列时,对应的视图或者约束删除
alter table <表名>
drop [constraint <约束条件>]
#删除表
drop table <表名> [CASCADE| RESTRICT]
查询结果显示select
基础不再赘述
1.在SQL查询语句中,若结果中需要显示一个关系表的所有属性用*号
2.去除结果中重复的元组 select distinct ****列【默认不去除】
3.查询结果计算 【返回的结果】
- 聚集函数:count/sum/avg/max/min [all|distinct] <列>
- 对于属性的空值,除count()外都不考虑,count()只计算个数需要考虑
- 数学函数/字符串函数/日期函数
举例:select
查询结果排序order by
select **
from ***
order by <目列> [ASC|DESC],<目标列> [ASC|DESC]
#ASC默认升序,降序DESC,如果第一目标列相同,按第二列排序
#<目列>也可以用1,2,3表示,表示第i列属性
#例如 order by 2,3 ASC
5.SQL的查询语句中,重命名目标列的方式:
- 在重命名对象后用AS表示出新的名称 ,age as age1,
- 在重命名对象后空格加新的名称 ,age age1,
- 【不可以】在重命名后以括号形式表示新的名称
查询满足条件 like in
select .....
from ....
where <元组条件表达式>
元组条件表达式:
1.运算符:± / % = > < and or not* 比如:5/3=1
**2.谓词:[not] between …and … 范围 [not] LIKE … **匹配
[not] IN (列名…) 指定集合 IS [not] NULL

- 其中LIKE 用于部分匹配查询[单引号]
其中字符串表达式通配符
_ 表示任意单个字符[可以是0个字符]
% 表示长度可为0的任意长字符串
<属性列名> [not] like 字符串表达式
where sn like '王%'
where cn like '%\ 实验' ESCAPE'\'
#如果查询内容包括%,下划线,需要使用escape转换
比如查找DB_Design 则 LIKE ‘DB I_ Design’ ESCAPE ‘I’
前面用添加转义字符,后面补充 ESCAPE ‘I’
- 其中IN 用于判断一个值是否属于集合里面
where sd in('数学','计算机')
分组聚集group by、having
select .....
from ....
where <元组条件表达式>
group by <属性列名> [<属性列名>] [HAVING <选择条件>]
1.根据属性名1,属性名2值依次进行分组;2.having子句对分组后的结果进行筛选
#平均成绩90分以上 【不能用where是因为where不能用聚集函数avg
select sno,avg(grade)
from sc
where avg(grade)>=90 group by sno
#正确的写法
select sno,avg(grade)
from sc
group by sno having avg(grade)>90;
#男生人数>2人的系名
select sd
from sc
where sex="男"
group by sd having count(*)>2;
连接查询join
多表连接查询
#查询选修C01的学生姓名和成绩
select sn,grade
from sc,s #sc和s做笛卡尔积运算
where sc.sno=s.sno and cno='c01'
注意连接时,需要补充where中的内容 等价关系
外连接查询
from <左关系 > left |right|full [outer] join <右关系 > on <连接条件>
#查询所有学生姓名及选修课程号为“C01”的成绩,没有选修该课程的学生,成绩显示为空
select sn,grade
from sc right outer join s
on sc.sno=s.sno and cno='c01'
【常规/内连接】from <左关系 > [inner] join <右关系 > on <连接条件>
#查询选修“数据结构”课程的学生的学号、姓名和成绩
select s.sno,sn,grade
from s,sc,c
where s.sno=sc.sno and c.cno=sc.cno and cn='数据结构'
select s.sno,sn,grade
from (s inner join sc on s.sno=sc.sno) inner join c on c.cno=sc.cno
where cn='数据结构'
自身连接查询
select ...
from s s1,s s2
from s as s1,s as s2
举例练习:设有关系R(A,B,C)和S(C,D)。与SQL语句select A,B,D from R,S where R.C=S.C等价的关系代数表达式是( )。πA,B,D(σR.C= S.C(R×S))
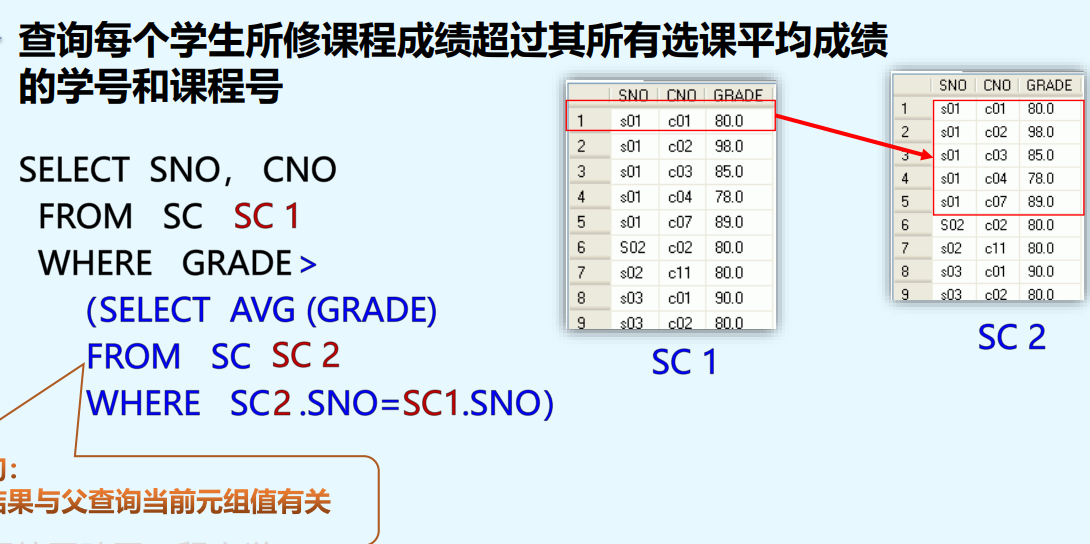
嵌套查询方式where中in
根据子查询中处理的数据是否与父查询的当前元组有关,
可以把嵌套查询分为独立子查询和相关子查询
-
谓词IN【一个值是否属于一个集合】

-
比较操作符
-
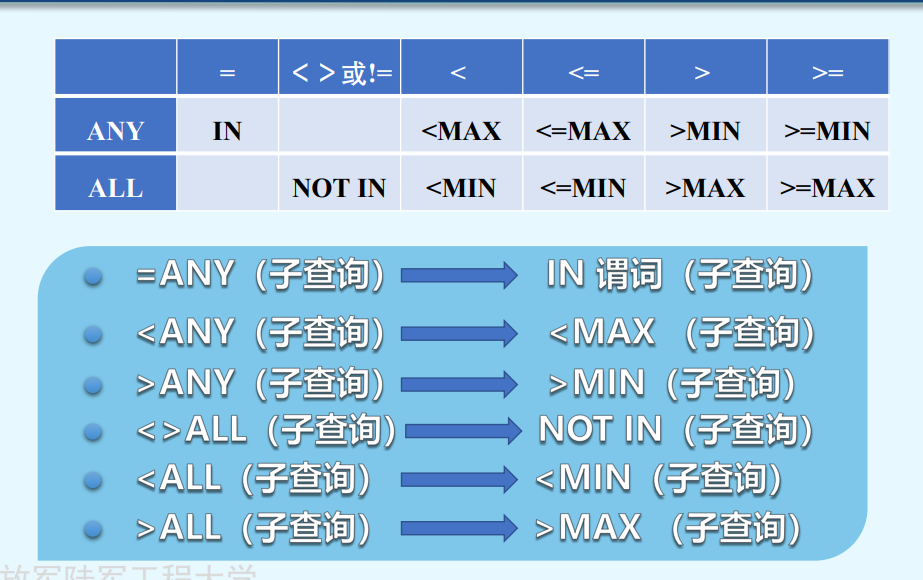
量词ANY ALL【部分支持】
ANY 的语义为查询结果中的某个值,当子查询结果中有某一 个值满足比较运算符,比较运算结果则为真。
ALL的语义为查询结果中的所有值,当子查询结果中每一个值 都满足比较运算符,比较运算结果才为真。


等价关系【因为部分支持any和all量词,所以可以替换】
-
谓词 exisits【相关子查询】
因为子查询的查询条件(sc.sno)需要用父查询的属性(s.sno)
#查询选修“C02”课程的学生姓名
SELECT SN
FROM S
WHERE SNO IN
( SELECT SNO FROM SC WHERE CNO=‘C02’ )
SELECT SN
FROM S
WHERE EXISTS
(SELECT * FROM SC WHERE SC.SNO=S.SNO AND CNO = ‘C02’)
#查询选修全部课程的学生的姓名
#选修全部课程的学生≡没有一门课他不选的学生
SELECT SN
FROM S
WHERE NOT EXISTS
(SELECT * FROM C
WHERE NOT EXISTS
(SELECT * FROM SC
WHERE SC.SNO=S.SNO AND SC.CNO=C.CNO))
集合运算
select语句返回的是集合,多个select语句可以返回多个集合
两个参与集合查询的select语句中,查询结果不仅要具备相同的属性名,而且属性名的排列顺序也要一致。
并union
#并
select [语句] union select [语句]
#查询选修了课程号为“C01”或“C02”的学生学号。
select sno from sc where cno='c01'
union
select sno from sc where cno='c02'
#union自动去除重复项
select distinct sno from sc
where cno='c01' or cno='c02'
交intersect
#交
select [语句] intersect select [语句]
#查询同时选修课程号为“C01”“C02”的学生学号。
select sno from sc where cno='c01'
intersect
select sno from sc where cno='c02'
select sno from sc
where cno='c01' and cno='c02' #错误
select sno from sc
where cno='c01' and sno in (
select sno from sc where cno='c02'
)
差except
#差
select [语句] except select [语句]
#查询选修了课程号为“C01”但没选修“C02”课程的学生学号
select sno from sc where cno='c01'
except
select sno from sc where cno='c02'
select sno from sc
where cno='c01' and cno='c02' #错误
select sno from sc
where cno='c01' and sno not in (
select sno from sc where cno='c02'
)
数据更新
**insert into <表名> (属性名,…) value (值…) **可插入多个元组
-
常量值与相应的属性名值域相同、个数相同。
-
元组的某属性没在INTO后出现,则这些属性上的值取空值NULL。
-
INTO中没有指明任何属性,则VALUES子句中新插入的元组在每个属 性上必须有值,且常量值的顺序要与表定义中属性的顺序一致。
-
INSERT语句可以往视图中插入数据
举例:INSERT INTO SC(SNO,CNO) VALUES (‘S31’,‘C01’);
INSERT INTO S VALUES (‘S31’,‘王浩’,‘计算机’,‘1999-10-15’,‘男’) ;
或者插入的元祖是某个子查询的结果
举例:插入“计算机”系学生选修“数据库”课程的选课记录。
INSERT INTO SC(SNO,CNO)
SELECT SNO,CNO FROM S,C WHERE SD=‘计算机’ AND CN=‘数据库’;
update <表名> set <属性>=<值> ,… where <条件> 可修改多个属性值
delete from <表名> [ where <条件> ]
举例:删除成绩低于所有课程平均成绩的选课元组
DELETE FROM SC WHERE GRADE<(SELECT AVG(GRADE) FROM SC);
- 更新操作的完整性检查
更新操作不能满足参照完整性时,采用的处理策略
拒绝执行(NO ACTION) •产生级联操作(CASCADE) •设置为空值(SET NULL)
- 更新操作不对关系表的模式结构进行改变
- 更新往往是在查询的基础上操作,更新也可能会嵌套子查询
- 更新需要考虑数据库定义的各类完整性约束
视图
视图(View)并不在数据库中实际存在,而是一种虚拟表,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
即视图就是执行查询语句后所返回的结果集,所以在创建视图的时候,主要就是创建这条SQL查询语句。
对于普通的数据表来说,视图具有以下的一些特点:
1、简单:因为视图是查询语句执行后返回的已经过滤好的复合条件的结果集,所以使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件。
2、安全:使用视图的用户只能访问他们被允许查询的结果集,对于表的权限管理并不能限制到某个行或者某个列,但是通过视图就可以简单的实现。
3、数据独立:一旦视图的结构被确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
二、视图的语法
create view <视图名> [列名,]
as 子查询
with check option
#with check option 表示对视图进行和更新操作时,要满足视图定义的条件
#如果没有指明字段,默认所有字段
drop view <视图名> [cascade]
#正常的select,update语句
普通的数据表来说,视图具有以下的一些特点:**
1、简单:因为视图是查询语句执行后返回的已经过滤好的复合条件的结果集,所以使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件。
2、安全:使用视图的用户只能访问他们被允许查询的结果集,对于表的权限管理并不能限制到某个行或者某个列,但是通过视图就可以简单的实现。
3、数据独立:一旦视图的结构被确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
二、视图的语法
create view <视图名> [列名,]
as 子查询
with check option
#with check option 表示对视图进行和更新操作时,要满足视图定义的条件
#如果没有指明字段,默认所有字段
drop view <视图名> [cascade]
#正常的select,update语句