干翻Hadoop系列之:Hadoop前瞻之分布式知识
前言
一:海量数据价值
二:海量数据两个棘手问题
1:海量数据如何存储?
掌握分布式存储数据的思想。
A:方案1:单机存储磁盘不够加磁盘
限制问题:
1:一台计算机不能无限制拓充
2:拓充的很多之后,计算机进行多磁盘寻址的问题。
1TB硬盘,100MB存储速度的时候
B:方案2:分布式存储
一台机器存不下,多台机器共同存储,读取数据时,多台数据同时读取数据。
三:海量数据如何计算
传统计算方式,时间很长,效率很低,能不能搞出来都是个问题。
解决方案:多台计算机同时计算,进行分布式计算。
第一章:大数据知识补充
一:大数据业务分析步骤
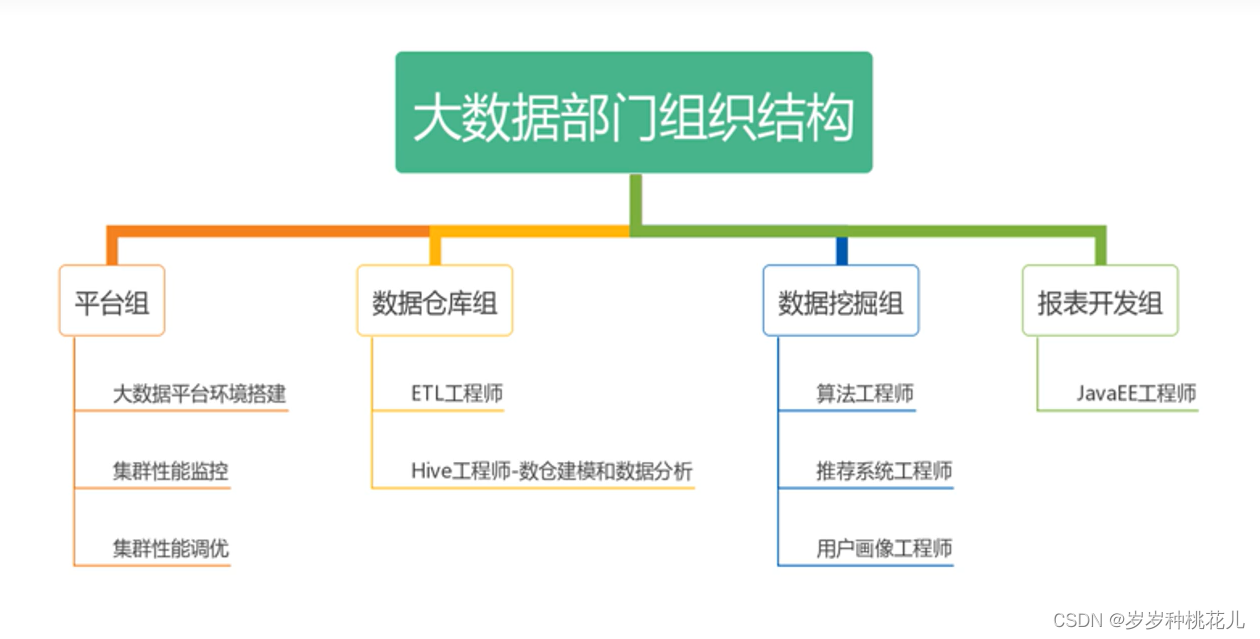
二:大数据部门介绍
第二章:分布式技术栈
一:分布式概念
1:单机到分布式
访问量变高,单机扛不住
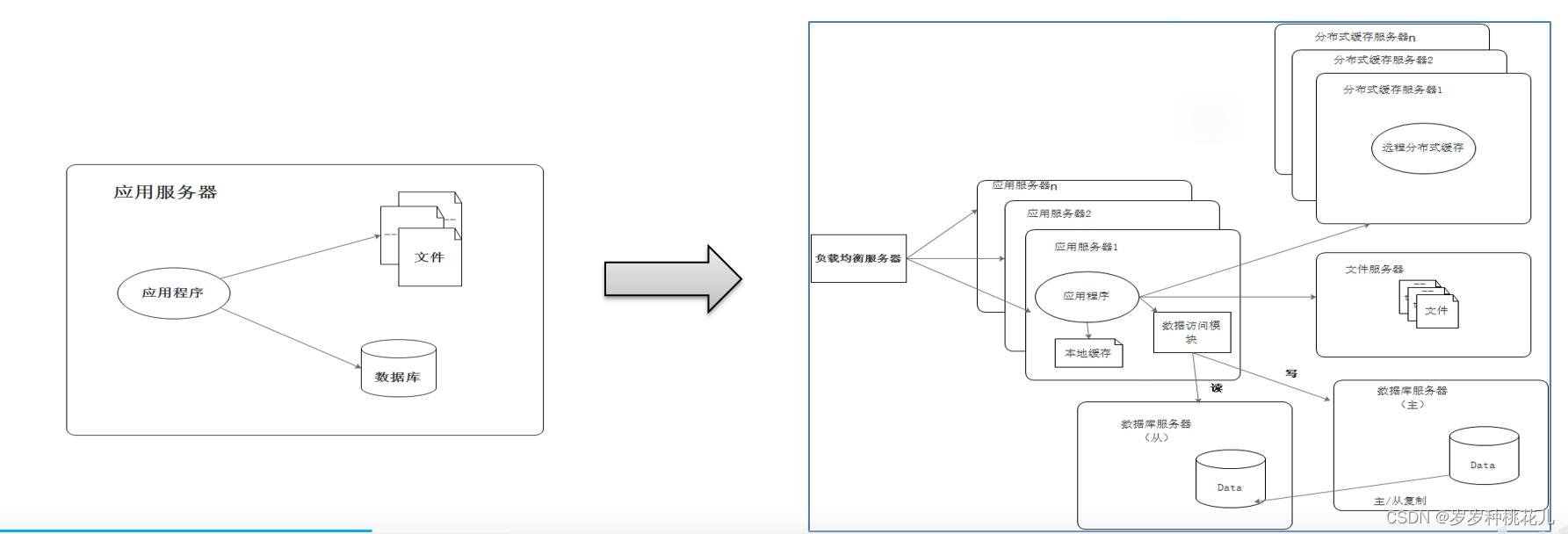
2:海量数据单机存不下、算不了
多线程计算,把CPU和内存榨干也是有上限瓶颈的。单机计算能力是受到物理硬件上限的限制。

二:分布式系统概述
分布式系统是一个硬件或软件组件分布在不同的网络计算机上
彼此之间仅仅通过消息传递进行通信和协调的系统。
一群互相独立计算机集合共同对外提供服务
对于系统的用户来说,就像是一台计算机在提供服务样
三:几个核心概念
1:负载均衡
概念:
Load Balance简称LB。将负载(工作任务)进行平衡、分摊到多个操作单元上进行。
说人话:
假设:单机服务最大qps为5w,现在没秒访问量有12W,单机肯定玩不转,需要加到三台机器。
图解:
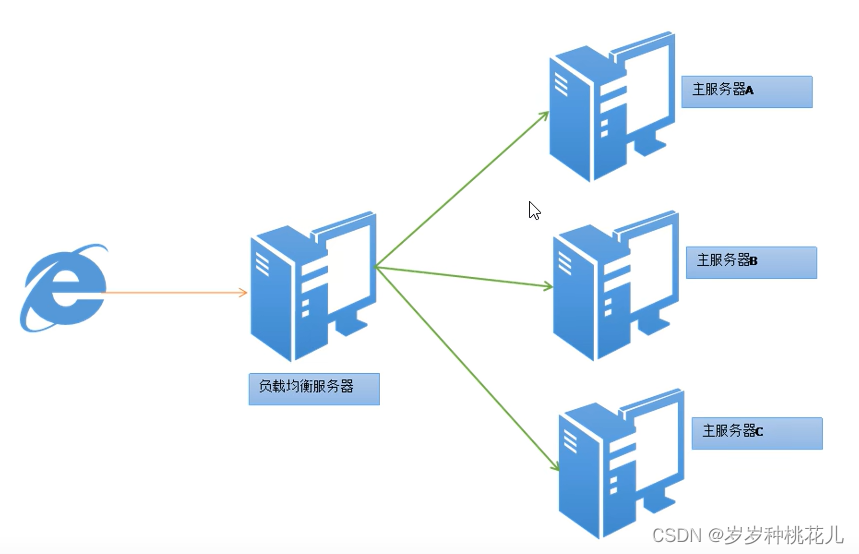
LB强调的是分布式概念呢?还是集群概念的?
集群的概念,因为这里是LB对应的后台服务是一样的,所以更加注重的是集群的概念。
2:故障转移
什么是单点故障?
假设一个场景,我们一个门户网页,需要订单系统、商品系统、支付系统…进行支持。结果突然某台服务器嗝屁了 ,此为单点故障。
故障转移:
1:当活动的服务或者应用意外终止时,快速启用冗余设备、备用服务器实例、系统、硬件、网络接替它工作
2:故障转移也称之为容错系统,所谓容错只是可以容忍错误的发生。
3:故障转移的和核心是设置备份,出现故障时,主备切换。
4:主备切换的前提是数据状态保持一致。服务状态一致,缓存状态一致,数据存储状态一致。
3:伸缩性
伸缩线称之为弹性可拓展性。动态拓展缩减我们的后台实例数量
流量大时拓展服务器,流量小时缩减服务器。
总结:
1:负载均衡:解决一个处理不了,多个共同处理的问题
2:故障转移:解决单点故障 容忍错误发生 业务连续
3:伸缩性:动态扩容,缩容