NumPy 秘籍中文第二版:十、Scikits 的乐趣
原文:NumPy Cookbook - Second Edition
协议:CC BY-NC-SA 4.0
译者:飞龙
在本章中,我们将介绍以下秘籍:
- 安装 scikit-learn
- 加载示例数据集
- 用 scikit-learn 对道琼斯股票进行聚类
- 安装 Statsmodels
- 使用 Statsmodels 执行正态性检验
- 安装 scikit-image
- 检测角点
- 检测边界
- 安装 Pandas
- 使用 Pandas 估计股票收益的相关性
- 从 Statsmodels 中将数据作为 pandas 对象加载
- 重采样时间序列数据
简介
Scikits 是小型的独立项目,以某种方式与 SciPy 相关,但不属于 SciPy。 这些项目不是完全独立的,而是作为一个联合体在伞下运行的。 在本章中,我们将讨论几个 Scikits 项目,例如:
- scikit-learn,机器学习包
- Statsmodels,统计数据包
- scikit-image,图像处理包
- Pandas,数据分析包
安装 scikit-learn
scikit-learn 项目旨在提供一种用于机器学习的 API。 我最喜欢的是令人惊叹的文档。 我们可以使用操作系统的包管理器安装 scikit-learn。 根据操作系统的不同,此选项可能可用也可能不可用,但它应该是最方便的方法。
Windows 用户只需从项目网站下载安装程序即可。 在 Debian 和 Ubuntu 上,该项目称为python-sklearn。 在 MacPorts 上,这些端口称为py26-scikits-learn和py27-scikits-learn。 我们也可以从源代码或使用easy_install安装。 PythonXY,Enthought 和 NetBSD 提供了第三方发行版。
准备
您需要安装 SciPy 和 NumPy。 返回第 1 章,“使用 IPython”,以获取必要的说明。
操作步骤
现在让我们看一下如何安装 scikit-learn 项目:
-
使用
easy_install进行安装:在命令行中键入以下命令之一:$ pip install -U scikit-learn $ easy_install -U scikit-learn由于权限问题,这个可能无法工作,因此您可能需要在命令前面编写
sudo,或以管理员身份登录。 -
从源代码安装:下载源代码,解压缩并使用
cd进入下载的文件夹。 然后发出以下命令:$ python setup.py install
加载示例数据集
scikit-learn 项目附带了许多我们可以尝试的数据集和样例图像。 在本秘籍中,我们将加载 scikit-learn 分发中包含的示例数据集。 数据集将数据保存为 NumPy 二维数组,并将元数据链接到该数据。
操作步骤
我们将加载波士顿房价样本数据集。 这是一个很小的数据集,因此,如果您要在波士顿寻找房子,请不要太兴奋! 其他数据集在这个页面中进行了描述。
我们将查看原始数据的形状及其最大值和最小值。 形状是一个元组,表示 NumPy 数组的大小。 我们将对目标数组执行相同的操作,其中包含作为学习目标(确定房价)的值。 以下sample_data.py 中的代码实现了我们的目标:
from __future__ import print_function
from sklearn import datasets
boston_prices = datasets.load_boston()
print("Data shape", boston_prices.data.shape)
print("Data max=%s min=%s" % (boston_prices.data.max(), boston_prices.data.min()))
print("Target shape", boston_prices.target.shape)
print("Target max=%s min=%s" % (boston_prices.target.max(), boston_prices.target.min()))
我们计划的结果如下:
Data shape (506, 13)
Data max=711.0 min=0.0
Target shape (506,)
Target max=50.0 min=5.0
利用 scikits-learn 对道琼斯股票进行聚类
聚类是一种机器学习算法,旨在基于相似度对项目进行分组。 在此示例中,我们将使用道琼斯工业平均指数(DJI 或 DJIA)进行聚类。 本秘籍的大多数步骤已通过前面各章的审查。
操作步骤
首先,我们将从 Yahoo 金融下载这些股票的 EOD 价格数据。 然后,我们将计算平方亲和矩阵。 最后,我们将股票与AffinityPropagation类聚类:
-
使用 DJI 指数的股票代码下载 2011 年价格数据。 在此示例中,我们仅对收盘价感兴趣:
# 2011 to 2012 start = datetime.datetime(2011, 01, 01) end = datetime.datetime(2012, 01, 01) #Dow Jones symbols symbols = ["AA", "AXP", "BA", "BAC", "CAT", "CSCO", "CVX", "DD", "DIS", "GE", "HD", "HPQ", "IBM", "INTC", "JNJ", "JPM", "KO", "MCD", "MMM", "MRK", "MSFT", "PFE", "PG", "T", "TRV", "UTX", "VZ", "WMT", "XOM"] quotes = [] for symbol in symbols: try: quotes.append(finance.quotes_historical_yahoo(symbol, start, end, asobject=True)) except urllib2.HTTPError as e: print(symbol, e) close = np.array([q.close for q in quotes]).astype(np.float) print(close.shape) -
使用对数收益率作为指标来计算不同股票之间的相似度。 我们正在要做的是计算数据点的欧几里德距离:
logreturns = np.diff(np.log(close)) print(logreturns.shape) logreturns_norms = np.sum(logreturns ** 2, axis=1) S = - logreturns_norms[:, np.newaxis] - logreturns_norms[np.newaxis, :] + 2 * np.dot(logreturns, logreturns.T) -
给
AffinityPropagation类上一步的结果。 此类为数据点或在我们的情况下的股票标记了适当的群集编号:aff_pro = sklearn.cluster.AffinityPropagation().fit(S) labels = aff_pro.labels_ for symbol, label in zip(symbols, labels): print('%s in Cluster %d' % (symbol, label))完整的群集程序如下:
from __future__ import print_function import datetime import numpy as np import sklearn.cluster from matplotlib import finance import urllib2 #1\. Download price data # 2011 to 2012 start = datetime.datetime(2011, 01, 01) end = datetime.datetime(2012, 01, 01) #Dow Jones symbols symbols = ["AA", "AXP", "BA", "BAC", "CAT", "CSCO", "CVX", "DD", "DIS", "GE", "HD", "HPQ", "IBM", "INTC", "JNJ", "JPM", "KO", "MCD", "MMM", "MRK", "MSFT", "PFE", "PG", "T", "TRV", "UTX", "VZ", "WMT", "XOM"] quotes = [] for symbol in symbols: try: quotes.append(finance.quotes_historical_yahoo(symbol, start, end, asobject=True)) except urllib2.HTTPError as e: print(symbol, e) close = np.array([q.close for q in quotes]).astype(np.float) print(close.shape) #2\. Calculate affinity matrix logreturns = np.diff(np.log(close)) print(logreturns.shape) logreturns_norms = np.sum(logreturns ** 2, axis=1) S = - logreturns_norms[:, np.newaxis] - logreturns_norms[np.newaxis, :] + 2 * np.dot(logreturns, logreturns.T) #3\. Cluster using affinity propagation aff_pro = sklearn.cluster.AffinityPropagation().fit(S) labels = aff_pro.labels_ for symbol, label in zip(symbols, labels): print('%s in Cluster %d' % (symbol, label))具有每个股票的簇号的输出如下:
(29, 252) (29, 251) AA in Cluster 0 AXP in Cluster 6 BA in Cluster 6 BAC in Cluster 1 CAT in Cluster 6 CSCO in Cluster 2 CVX in Cluster 7 DD in Cluster 6 DIS in Cluster 6 GE in Cluster 6 HD in Cluster 5 HPQ in Cluster 3 IBM in Cluster 5 INTC in Cluster 6 JNJ in Cluster 5 JPM in Cluster 4 KO in Cluster 5 MCD in Cluster 5 MMM in Cluster 6 MRK in Cluster 5 MSFT in Cluster 5 PFE in Cluster 7 PG in Cluster 5 T in Cluster 5 TRV in Cluster 5 UTX in Cluster 6 VZ in Cluster 5 WMT in Cluster 5 XOM in Cluster 7
工作原理
下表是在秘籍中使用的函数的概述:
| 函数 | 描述 |
|---|---|
sklearn.cluster.AffinityPropagation() | 创建一个AffinityPropagation对象。 |
sklearn.cluster.AffinityPropagation.fit() | 从欧几里得距离计算亲和度矩阵,并应用亲和度传播聚类。 |
diff() | 计算 NumPy 数组中数字的差。 如果未指定,则计算一阶差。 |
log() | 计算 NumPy 数组中元素的自然对数。 |
sum() | 对 NumPy 数组的元素求和。 |
dot() | 这对二维数组执行矩阵乘法。 它还计算一维数组的内积。 |
另见
- 相关文档
安装 Statsmodels
statsmodels包专注于统计建模。 我们可以将其与 NumPy 和 pandas 集成(在本章稍后的内容中将有更多关于 pandas 的信息)。
操作步骤
可以从这里下载源码和二进制文件。 如果要从源代码安装,请运行以下命令:
$ python setup.py install
如果使用setuptools,则命令如下:
$ easy_install statsmodels
使用 Statsmodels 执行正态性检验
statsmodels包具有许多统计检验。 我们将看到这样一个检验的示例 – Anderson-Darling 检验用于正态性。
操作步骤
我们将像以前的秘籍一样下载价格数据,但这一次是单只股票。 再次,我们将计算该股票收盘价的对数收益,并将其用作正态性检验函数的输入。
此函数返回一个包含第二个元素的元组,即 p 值,介于 0 和 1 之间。本教程的完整代码如下:
from __future__ import print_function
import datetime
import numpy as np
from matplotlib import finance
from statsmodels.stats.adnorm import normal_ad
#1\. Download price data
# 2011 to 2012
start = datetime.datetime(2011, 01, 01)
end = datetime.datetime(2012, 01, 01)
quotes = finance.quotes_historical_yahoo('AAPL', start, end, asobject=True)
close = np.array(quotes.close).astype(np.float)
print(close.shape)
print(normal_ad(np.diff(np.log(close))))
#Retrieving data for AAPL
#(252,)
#(0.57103805516803163, 0.13725944999430437)
下面显示了0.13为p-value的脚本的输出:
Retrieving data for AAPL
(252,)
(0.57103805516803163, 0.13725944999430437)
工作原理
如statsmodels中所示,此秘籍证明了 Anderson-Darling 统计检验的正态性。 我们使用没有正态分布的股票价格数据作为输入。 对于数据,我们获得了0.13的 p 值。 由于概率在 0 到 1 之间,这证实了我们的假设。
安装 scikit-image
scikit-image 是用于图像处理的工具包,它依赖 PIL,SciPy,Cython 和 NumPy。 Windows 安装程序也可用。 该工具包是 Enthought Python 发行版以及 PythonXY 发行版的一部分。
操作步骤
与往常一样,使用以下两个命令之一安装 scikit-image:
$ pip install -U scikit-image
$ easy_install -U scikit-image
同样,您可能需要以超级用户身份运行这些命令。
另一种选择是通过克隆 Git 存储库或从 Github 下载该存储库作为源归档来获取最新的开发版本。 然后运行以下命令:
$ python setup.py install
检测角点
角点检测是计算机视觉中的标准技术。 scikit-image 提供了 Harris 角点检测器,它很棒,因为角检测非常复杂。 显然,我们可以从头开始做,但是这违反了不重新发明轮子的基本原则。
准备
您可能需要在系统上安装jpeglib,才能加载 scikit-learn 图像(是 JPEG 文件)。 如果您使用的是 Windows,请使用安装程序。 否则,下载发行版,解压缩它,并使用以下命令从顶部文件夹中进行构建:
$ ./configure
$ make
$ sudo make install
操作步骤
我们将从 scikit-learn 加载示例图像。 对于此示例,这不是绝对必要的; 您可以改用其他任何图像:
-
scikit-learn 当前在数据集结构中有两个样例 JPEG 图像。 只看第一张图片:
dataset = load_sample_images() img = dataset.images[0] -
自本书第一版以来,API 发生了变化。 例如,对于 scikit-image 0.11.2,我们需要首先将彩色图像的值转换为灰度值。 图像灰度如下:
gray_img = rgb2gray(img) -
调用
corner_harris()函数获取角点的坐标:harris_coords = corner_peaks(corner_harris(gray_img)) y, x = np.transpose(harris_coords)拐角检测的代码如下:
from sklearn.datasets import load_sample_images import matplotlib.pyplot as plt import numpy as np from skimage.feature import corner_harris from skimage.feature import corner_peaks from skimage.color import rgb2gray dataset = load_sample_images() img = dataset.images[0] gray_img = rgb2gray(img) harris_coords = corner_peaks(corner_harris(gray_img)) y, x = np.transpose(harris_coords) plt.axis('off') plt.imshow(img) plt.plot(x, y, 'ro') plt.show()我们得到一个带有点的图像,脚本在其中检测角点,如以下屏幕截图所示:

工作原理
我们对 scikit-image 的样例图像应用了 Harris 角点检测。 如您所见,结果非常好。 我们只能使用 NumPy 做到这一点,因为它只是一个简单的线性代数类型的计算。 仍然,可能会变得凌乱。 scikit-image 工具包具有更多类似的功能,因此,如果需要图像处理例程,请查看 scikit-image 文档。 另外请记住,API 可能会发生快速变化。
另见
- 相关的 scikit-image 文档
检测边界
边界检测是另一种流行的图像处理技术。 scikit-image 具有基于高斯分布的标准差的 Canny 过滤器实现 ,可以开箱即用地执行边界检测。 除了将图像数据作为 2D 数组外,此过滤器还接受以下参数:
- 高斯分布的标准差
- 下限阈值
- 上限阈值
操作步骤
我们将使用与先前秘籍相同的图像。 代码几乎相同(请参见edge_detection.py)。 请特别注意我们称为 Canny 筛选器函数的行:
from sklearn.datasets import load_sample_images
import matplotlib.pyplot as plt
import skimage.feature
dataset = load_sample_images()
img = dataset.images[0]
edges = skimage.feature.canny(img[..., 0])
plt.axis('off')
plt.imshow(edges)
plt.show()
该代码生成原始图像中边界的图像,如以下屏幕截图所示:

另见
- 相关文档
安装 Pandas
Pandas 是用于数据分析的 Python 库。 它与 R 编程语言有一些相似之处,并非偶然。 R 是一种受数据科学家欢迎的专业编程语言。 例如,R 启发了 Pandas 的核心DataFrame对象。
操作步骤
在 PyPi 上,该项目称为pandas。 因此,您可以运行以下命令之一:
$ sudo easy_install -U pandas
$ pip install pandas
如果使用 Linux 包管理器,则需要安装python-pandas项目。 在 Ubuntu 上,执行以下操作:
$ sudo apt-get install python-pandas
您也可以从源代码安装(除非下载源代码存档,否则需要 Git):
$ git clone git://github.com/pydata/pandas.git
$ cd pandas
$ python setup.py install
另见
- 相关文档
使用 Pandas 估计股票收益的相关性
Pandas DataFrame是类似矩阵和字典的数据结构,类似于 R 中提供的功能。实际上,它是 Pandas 的中心数据结构,您可以应用各种操作。 例如,查看投资组合的相关矩阵是很常见的,所以让我们开始吧。
操作步骤
首先,我们将为每个符号的每日对数回报创建带有 Pandas 的DataFrame。 然后,我们将在约会中加入这些。 最后,将打印相关性,并显示一个图:
-
要创建数据框,请创建一个包含股票代码作为键的字典,并将相应的日志作为值返回。 数据框本身以日期作为索引,将股票代码作为列标签:
data = {} for i, symbol in enumerate(symbols): data[symbol] = np.diff(np.log(close[i])) # Convention: import pandas as pd df = pd.DataFrame(data, index=dates[0][:-1], columns=symbols)现在,我们可以执行诸如计算相关矩阵或在数据帧上绘制等操作:
print(df.corr()) df.plot()完整的源代码(也可以下载价格数据)如下:
from __future__ import print_function import pandas as pd import matplotlib.pyplot as plt from datetime import datetime from matplotlib import finance import numpy as np # 2011 to 2012 start = datetime(2011, 01, 01) end = datetime(2012, 01, 01) symbols = ["AA", "AXP", "BA", "BAC", "CAT"] quotes = [finance.quotes_historical_yahoo(symbol, start, end, asobject=True) for symbol in symbols] close = np.array([q.close for q in quotes]).astype(np.float) dates = np.array([q.date for q in quotes]) data = {} for i, symbol in enumerate(symbols): data[symbol] = np.diff(np.log(close[i])) df = pd.DataFrame(data, index=dates[0][:-1], columns=symbols) print(df.corr()) df.plot() plt.legend(symbols) plt.show() # AA AXP BA BAC CAT #AA 1.000000 0.768484 0.758264 0.737625 0.837643 #AXP 0.768484 1.000000 0.746898 0.760043 0.736337 #BA 0.758264 0.746898 1.000000 0.657075 0.770696 #BAC 0.737625 0.760043 0.657075 1.000000 0.657113 #CAT 0.837643 0.736337 0.770696 0.657113 1.000000这是相关矩阵的输出:
AA AXP BA BAC CAT AA 1.000000 0.768484 0.758264 0.737625 0.837643 AXP 0.768484 1.000000 0.746898 0.760043 0.736337 BA 0.758264 0.746898 1.000000 0.657075 0.770696 BAC 0.737625 0.760043 0.657075 1.000000 0.657113 CAT 0.837643 0.736337 0.770696 0.657113 1.000000显示了五只股票的对数收益图:
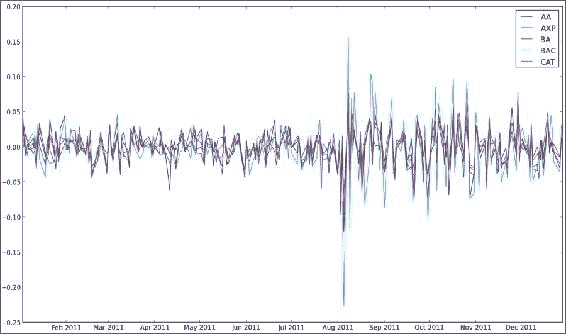
工作原理
我们使用了以下DataFrame方法:
| 函数 | 描述 |
|---|---|
pandas.DataFrame() | 此函数使用指定的数据,索引(行)和列标签构造DataFrame。 |
pandas.DataFrame.corr() | 该函数计算列的成对相关,而忽略缺失值。 默认情况下,使用 Pearson 相关。 |
pandas.DataFrame.plot() | 此函数使用matplotlib绘制数据帧。 |
另见
- 相关文档
- 第 4 章,“Pandas 入门书”,摘自 Ivan Idris 的书“Python 数据分析”, Packt Publishing
从 Statsmodels 中将数据作为 pandas 对象加载
statsmodels 在其发行版中有很多样本数据集。 完整列表可以在这个页面中找到。
在本教程中,我们将专注于铜数据集,其中包含有关铜价,世界消费量和其他参数的信息。
准备
在开始之前,我们可能需要安装 patsy。 patsy 是描述统计模型的库。 很容易看出这个库是否是必需的。 只需运行代码。 如果您收到与 patsy 相关的错误,请执行以下任一命令:
$ sudo easy_install patsy
$ pip install --upgrade patsy
操作步骤
在本节中,我们将从 statsmodels 中加载数据集作为 Pandas DataFrame或Series对象。
-
我们需要调用的函数是
load_pandas()。 如下加载数据:data = statsmodels.api.datasets.copper.load_pandas()这会将数据加载到包含 Pandas 对象的
DataSet对象中。 -
DataSet对象具有名为exog的属性,当作为 Pandas 对象加载时,该属性将成为具有多个列的DataFrame对象。 在我们的案例中,它还有一个endog属性,其中包含世界铜消费量的值。通过创建
OLS对象并调用其fit()方法来执行普通的最小二乘计算,如下所示:x, y = data.exog, data.endog fit = statsmodels.api.OLS(y, x).fit() print("Fit params", fit.params)这应该打印拟合过程的结果:
Fit params COPPERPRICE 14.222028 INCOMEINDEX 1693.166242 ALUMPRICE -60.638117 INVENTORYINDEX 2515.374903 TIME 183.193035 -
OLS 拟合的结果可以通过
summary()方法总结如下:print(fit.summary())这将为我们提供以下回归结果输出:
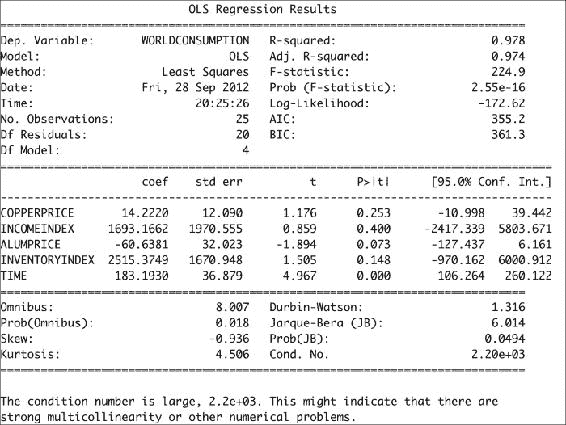
加载铜数据集所需的代码如下:
from __future__ import print_function import statsmodels.api # See https://github.com/statsmodels/statsmodels/tree/master/statsmodels/datasets data = statsmodels.api.datasets.copper.load_pandas() x, y = data.exog, data.endog fit = statsmodels.api.OLS(y, x).fit() print("Fit params", fit.params) print() print("Summary") print() print(fit.summary())
工作原理
Statsmodels 的Dataset类中的数据遵循特殊格式。 其中,此类具有endog和exog属性。 Statsmodels 具有load()函数,该函数将数据作为 NumPy 数组加载。 相反,我们使用了load_pandas()方法,该方法将数据加载为pandas对象。 我们进行了 OLS 拟合,基本上为我们提供了铜价和消费量的统计模型。
另见
- 相关文档
重采样时间序列数据
在此教程中,您将学习如何使用 Pandas 对时间序列进行重新采样。
操作步骤
我们将下载AAPL的每日价格时间序列数据,然后通过计算平均值将其重新采样为每月数据。 我们将通过创建 Pandas DataFrame并调用其resample() 方法来做到这一点:
-
在创建 Pandas
DataFrame之前,我们需要创建一个DatetimeIndex对象传递给DataFrame构造器。 根据下载的报价数据创建索引,如下所示:dt_idx = pandas.DatetimeIndex(quotes.date) -
获得日期时间索引后,我们将其与收盘价一起使用以创建数据框:
df = pandas.DataFrame (quotes.close, index=dt_idx, columns=[symbol]) -
通过计算平均值,将时间序列重新采样为每月频率:
resampled = df.resample('M', how=numpy.mean) print(resampled)如下行所示,重新采样的时间序列每个月都有一个值:
AAPL 2011-01-31 336.932500 2011-02-28 349.680526 2011-03-31 346.005652 2011-04-30 338.960000 2011-05-31 340.324286 2011-06-30 329.664545 2011-07-31 370.647000 2011-08-31 375.151304 2011-09-30 390.816190 2011-10-31 395.532381 2011-11-30 383.170476 2011-12-31 391.251429 -
使用
DataFrame plot()方法绘制数据:df.plot() resampled.plot() plt.show()原始时间序列的图如下:
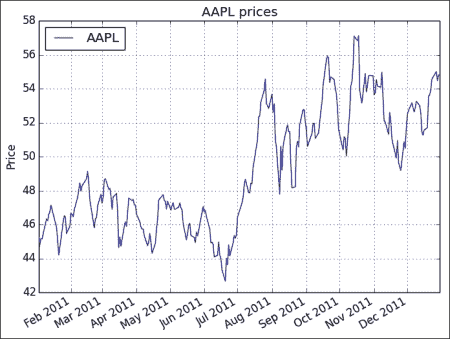
重采样的数据具有较少的数据点,因此,生成的图更加混乱,如以下屏幕截图所示:
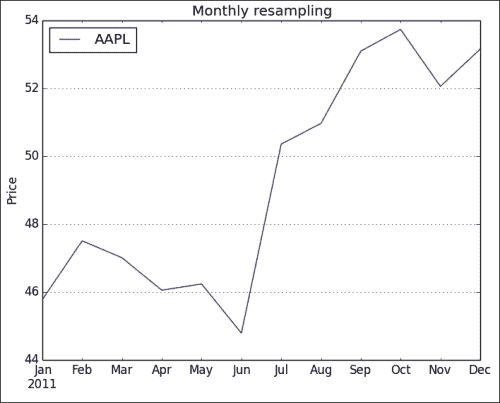
完整的重采样代码如下:
from __future__ import print_function import pandas import matplotlib.pyplot as plt from datetime import datetime from matplotlib import finance import numpy as np # Download AAPL data for 2011 to 2012 start = datetime(2011, 01, 01) end = datetime(2012, 01, 01) symbol = "AAPL" quotes = finance.quotes_historical_yahoo(symbol, start, end, asobject=True) # Create date time index dt_idx = pandas.DatetimeIndex(quotes.date) #Create data frame df = pandas.DataFrame(quotes.close, index=dt_idx, columns=[symbol]) # Resample with monthly frequency resampled = df.resample('M', how=np.mean) print(resampled) # Plot df.plot() plt.title('AAPL prices') plt.ylabel('Price') resampled.plot() plt.title('Monthly resampling') plt.ylabel('Price') plt.grid(True) plt.show()
工作原理
我们根据日期和时间列表创建了日期时间索引。 然后,该索引用于创建 Pandas DataFrame。 然后,我们对时间序列数据进行了重新采样。 单个字符给出重采样频率,如下所示:
- 每天
D - 每月
M - 每年
A
resample()方法的how参数指示如何采样数据。 默认为计算平均值。
另见
- 相关 Pandas 文档