在Win11上部署ChatGLM2-6B详细步骤--(上)准备工作
一:简单介绍
ChatGLM-6B是清华大学知识工程和数据挖掘小组(Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University)发布的一个开源的对话机器人。根据官方介绍,这是一个千亿参数规模的中英文语言模型。并且对中文做了优化。本次开源的版本是其60亿参数的小规模版本,约60亿参数,本地部署仅需要6GB显存(INT4量化级别)。
其中ChatGLM2-6B代码依照Apache-2.0协议开源,ChatGLM2-6B模型的权重的使用则需要遵循Model License。ChatGLM2-6B权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
ChatGLM2-6B是开源中英双语对话模型 ChatGLM-6B 的第二代版本在保留了初代对话流畅、部署门槛较低等众多优秀特点之上,引入以下四个新特性:
1、性能更强大,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
2、更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练。
3、更长的上下文:由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练。
4、更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
二:环境准备
1、查看CUDA的版本
打开cmd,执行nvidia-smi
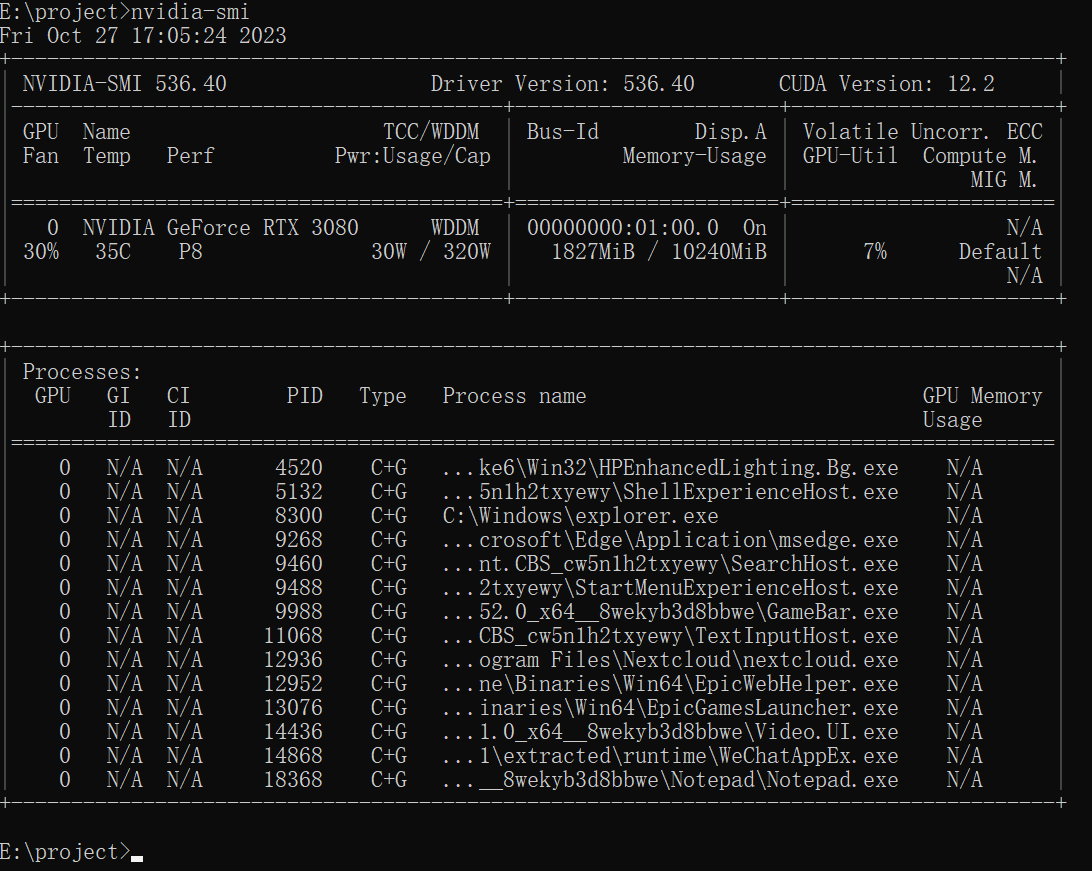
这里我们需要记录的数据就是CUDA Version:12.2
如果没有显示或报错,那就是显卡驱动还没有安装好,那么接下来需要安装显卡驱动。
2、安装显卡驱动
要安装显卡驱动,首先要搞清楚自己显卡的型号,你可以打开windows设备管理器,查下自己显示的驱动如下图:

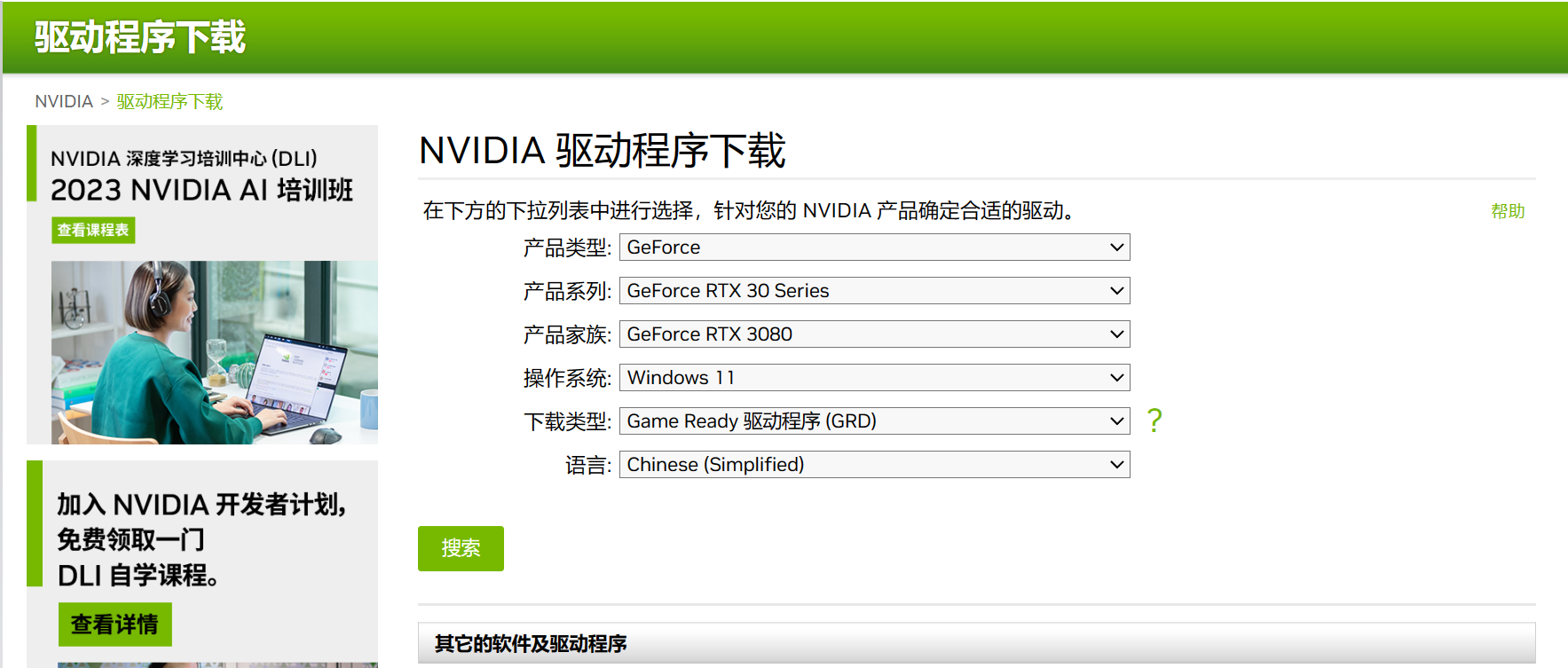
从这张图上我们看到这台电脑的显卡是NVIDIA GeForce RTX 3080。然后我们到厂商的官方网站下载驱动,注意为保证安装质量,一定要官网下载,切不可去其他网站下载驱动。
下载地址为:
https://www.nvidia.cn/Download/index.aspx?lang=cn
3、安装CUDA
CUDA是NVIDIA发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。
CUDA的下载地址:
https://developer.nvidia.com/cuda-toolkit-archive
根据nvidia-smi记录的数据,CUDA Version:12.2,所以我们下载的版本只要不高过V12.2就可以了。
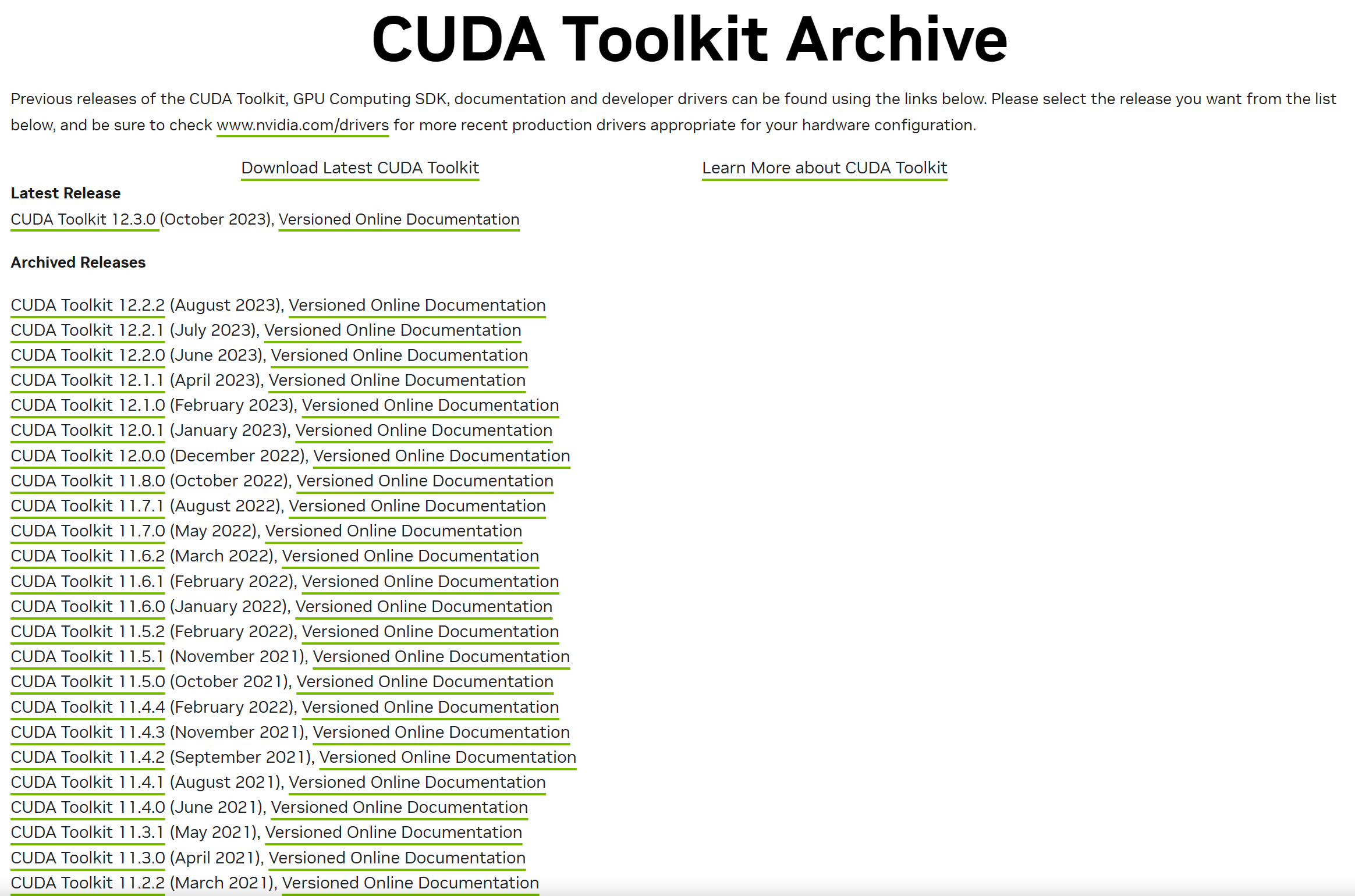
这里我们下载CUDA Toolkit 11.7.1
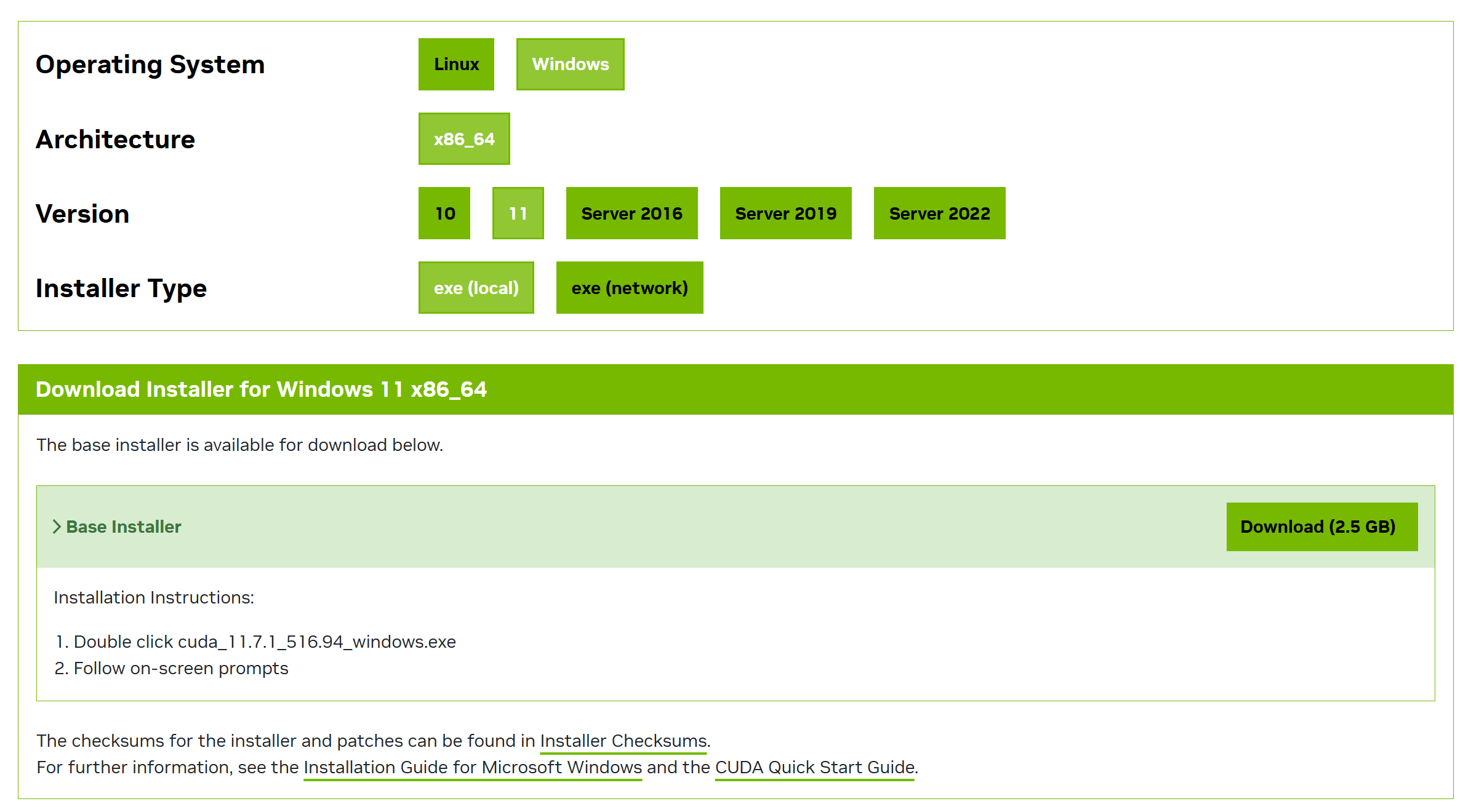
大约有2.5G左右的文件,下载完安装就可以了。
4、安装Visual Studio2019
下载地址:https://visualstudio.microsoft.com/zh-hans/downloads/
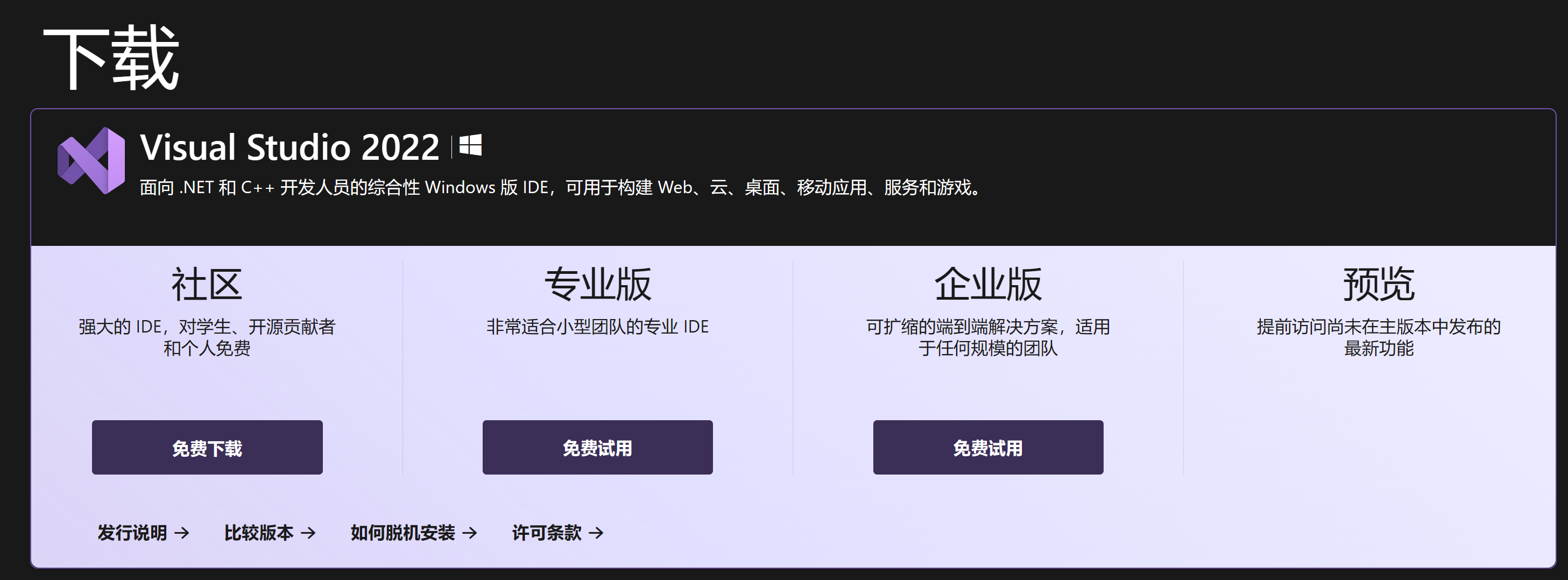
做为测试使用我们下载社区版本就可以了,当然有些小伙伴说,为什么不下载最新版本,实际原因是因为我们测试的这些模型未必能兼容最新版本,所以从安装的简单程序方面来看,最好不要用最新版。这样成功率会更好,当然也要看我们具体测试的模型他的具体要求,或高或低都不行。这个要根据实际情况来定。
然后鼠标拉到最低下:
在这里我们选择:

安装时需要勾选“Python开发”和“C++桌面开发”
5、下载cuDNN
cuDNN(CUDA Deep Neural Network library) 是由NVIDIA开发的一个深度学习GPU加速库。目的和功能:cuDNN旨在提供高效、标准化的原语(基本操作)来加速深度学习框架(例如TensorFlow、PyTorch)在NVIDIA GPU上的运算。多数主流的深度学习框架(如TensorFlow、PyTorch、Caffe等)都集成了cuDNN。这意味着当开发者使用这些框架并在NVIDIA GPU上运行时,他们会自动从cuDNN的高效运算中受益。
总之:cuDNN是一个为深度学习在NVIDIA GPU上提供高效运算的库。它包含了许多为神经网络操作高度优化的函数,使得深度学习框架可以在NVIDIA GPU上实现最佳性能。
cuDNN的下载地址:https://developer.nvidia.com/rdp/cudnn-archive
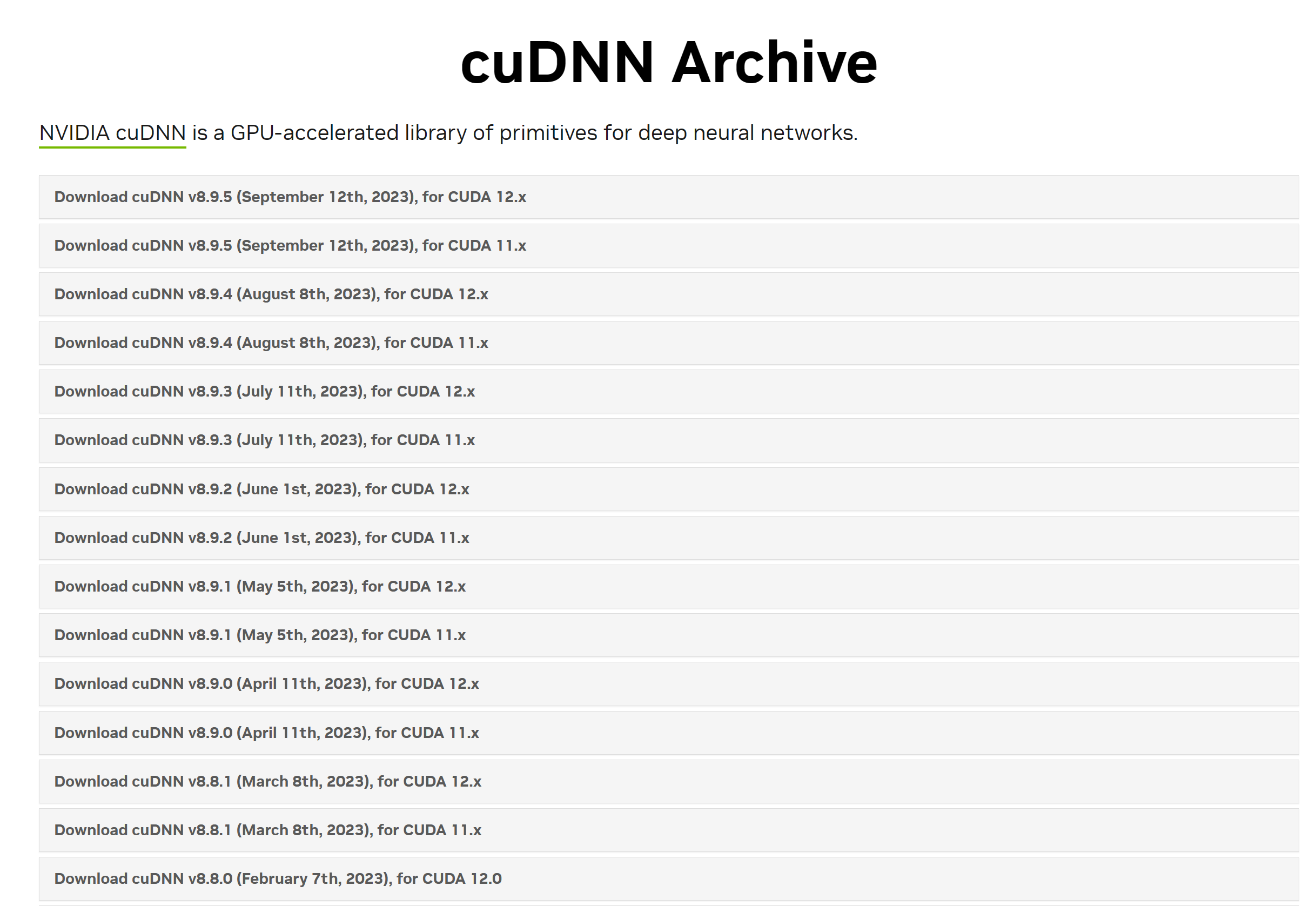
这里我们下载了V8.9.5,下载时需要用户名和密码,自己注册一个就可以了,下载后将文件解压缩,将bin、include、lib都考到:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7
把三个文件夹直截复制过去就可以了。
安装完成后,我们测试一下是否成功的安装了GPU。执行指令:nvcc -V,如下图

以上显示我们安装成功了。
6、安装anaconda
Anaconda 是一个用于科学计算的 Python 发行版,支持 Linux, Mac, Windows, 包含了众多流行的科学计算、数据分析的 Python 包。
下载地址如下:https://www.anaconda.com/download
无特别的说明,直接下载windows版本就可以了。
其他需要说明的地方,所有版本都会随着时间的过渡有变化,包括厂家的网页可能也会改。所以大家有时不要完全依赖这些文章的显示,也要灵活根据现实的情况来安装。