【网络】详解http协议
目录
- 一、认识URL
- urlencode和urldecode
- 二、HTTP协议
- HTTP协议格式
- HTTP的方法
- HTTP的状态码
- HTTP常见Header
一、认识URL
URL叫做统一资源定位符,也就是我们平时俗称的网址,是因特网的万维网服务程序上用于指定信息位置的表示方法。

urlencode和urldecode
urlencode编码:主要解决在url中出现的特殊符号的问题
urldecode:就是urlencode的逆过程
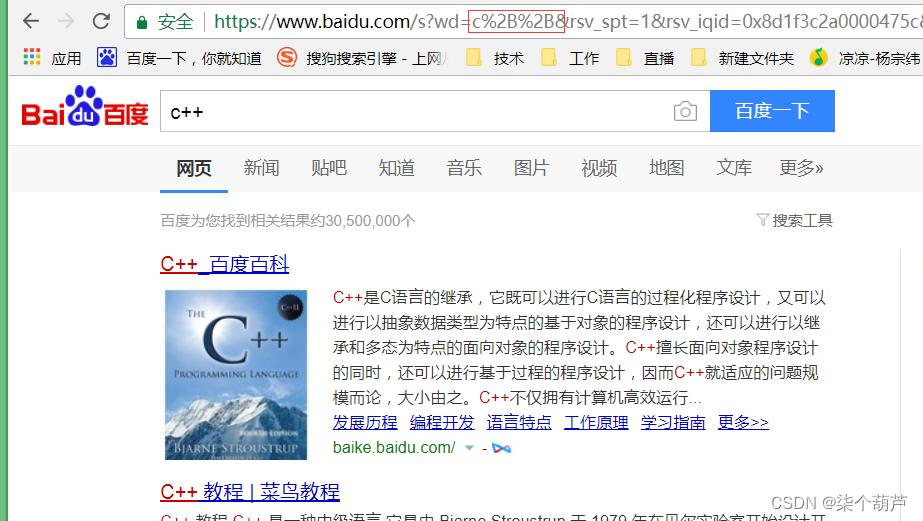
比如:图中的“+”就被转义成了“%2B”,而urldecode就是把“%2B”解释成“+”
转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
二、HTTP协议
HTTP协议格式
HTTP请求:

- 首行: [方法] + [url] + [版本]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度;
HTTP响应:
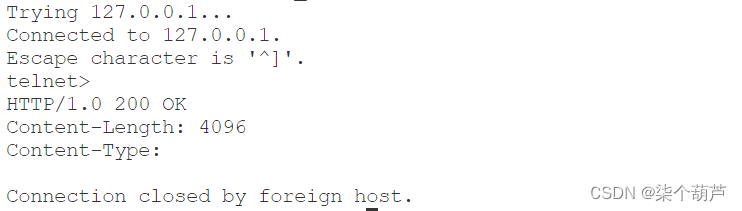
- 首行: [版本号] + [状态码] + [状态码解释]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个
- Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.
HTTP的方法
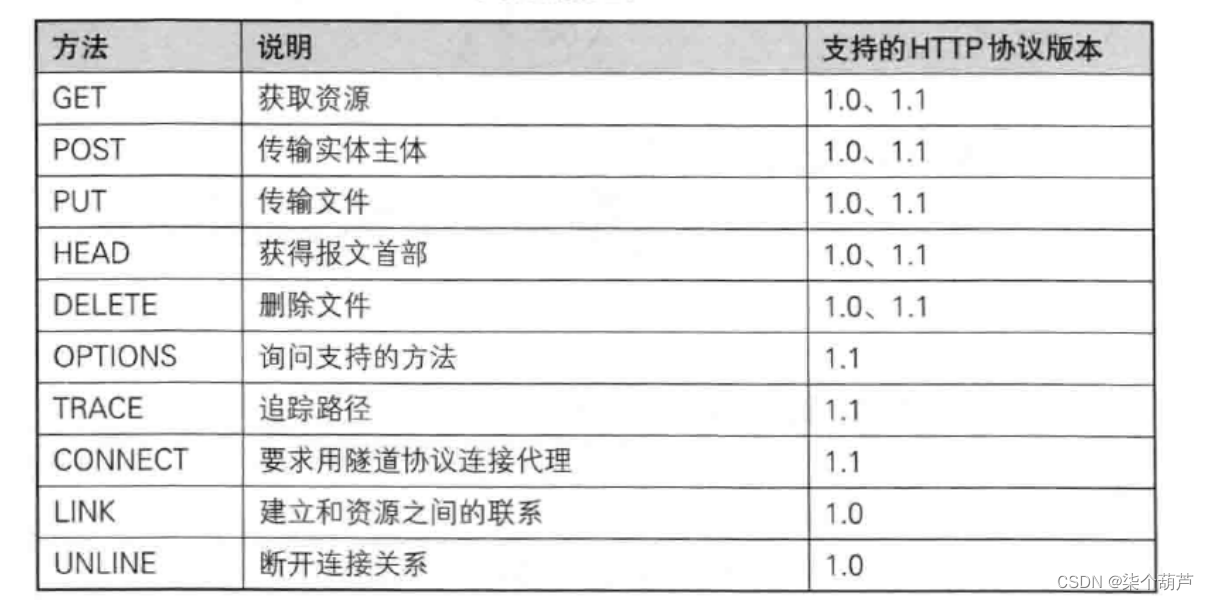
其中最常用的就是GET方法和POST方法
HTTP的状态码
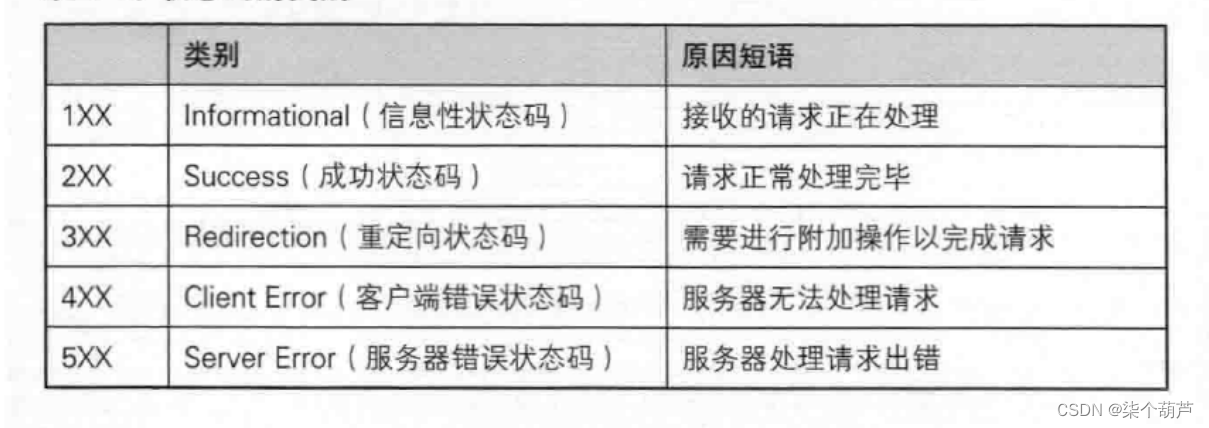
为什么有状态码?
我们对应的请求,我们给浏览器返回结果,但是我们怎么知道返回的是正确的,所以有http状态码。
当你访问某个服务器上的某个资源时,这个资源不存在,属于客户端错误还是服务器错误?
请求也分正常请求和不正常请求,比如你的银行卡只有1元,而你要取一个亿,所以服务器上的资源是有限的,所以404报错是客户端的错误。
要不要告诉客户端是错误的?要,所以会返回404的页面
5开头,一般是服务器错误,比如我们今天在做请求,服务器里面可能会创建进程或线程处理失败,这就是服务器内部错误,或者一些原因,服务器响应失败,但是即使公司内部是服务器错了,也不会给你发是5开头的错误码,一般会发1或2开头
3开头的状态码:重定向状态码
概念:有个客户端和服务器,因为某些原因服务器地址换了, 对应网站变了,可是老用户不知道,所以老用户访问的时候,请求之后,服务器不对这个客户端提供服务,只是告诉你当前需要访问其他地址。
我们举个例子,来理解什么是重定向状态码:
有个学校东门,在东门有家吃饭的地方,但是学校东门路况不好,过了二三月,走到吃饭的地方,发现门上有贴张字条,这条路在修,我们临时搬到西门,所以重定向功能是通过服务的一方告诉你,我们店门没办法提供服务了,由你决定去不去。而过了半年后,是去西门还是东门,但是我不知道路修好没,所以我还是去东门看看,看了后,然后再跑到西门,因为我不知道什么时候搬过来,这就是临时重定向,我的认知始终是先去老的店门,后来,老板在西门干久了,生意好,想在西门开,就回老店,贴三个月之内,我们永久搬到西门,所以此时,我们去东门看到这张纸,以后就都会去西门了。
- 临时重定向:不更改浏览器的如何地址信息
- 永久重定向:会更改浏览器的本地书签
server 会响应301 302 307 + Location + 新的地址
301:永久重定向
302 307:临时重定向
重定向什么时候用?
1、一个网站,不仅仅是人在访问,由可能有其他的程序也在访问,比如爬虫,搜索引擎每时每刻都在爬全网的数据
2、搜出来一个条目,点击,这个网站过期了,打不开了
一般用在搜索引擎爬全网的资源,会用重定向,爬的网站会经常更新,所以有临时重定向
HTTP常见Header
- Content-Type: 数据类型(text/html等)
- Cache-Control:缓存时间,默认为0,就是没有缓冲
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能
- Accept-Enconing:我是客户端,可以接受什么样的编码或压缩类型
- Accept-Language:我是客户端,我未来可以接受什么样的编码符号
- User-Agent:代表这次HTTP请求的客户端信息
关于http的会话保持功能
http本身是无状态的,在我们不考虑缓存的问题,http今天访问file1,之后,还想访问,http并不知道你访问过,还会重新请求,就比如,登录哔哩哔哩,基于http已经登录了一个网站,关闭后,再访问,还是登录的,http不是无状态的吗,为什么还是认识我?
无状态主要是用于超文本传输的,本身并不会去维护你这个用户是否在线做过多工作,它本身不做,并不代表它不提供这个功能,所以http不直接做这个工作,但是用户需要这个功能,保证登录后,会一直都在,这就是会话功能,要使用户是否在线要持续的记录下来,所以有会话保持功能,会写入一些cookie信息,就有cookie加session功能,就是会话保持功能。
比如:服务器上有非常多的资源,如果今天我要访问一个资源,要VIP才能访问,所以我买了个VIP,然后我去访问它了,服务器识别到我是VIP,就发给我资源,而只有发和收,就是http的功能,下次我还想访问其他资源呢,http说你是谁啊,就还要再登录,,所以第一次访问VIP资源,服务器发现没登录,就会返回去要求登录,登录成功了,就会把我的账号密码提回去,服务器端就对我的账号密码做认证,做认证之前肯定我注册过,就会去查我的账号注册过,认证成功后,就会返回客户端一个认证通过的消息,可能返回一个301:Location: https//xxx,下次再访问时,它怎么知道我是谁,所以浏览器当我认证通过时,会通过一下http选项(set-cooke),把我的私人信息写到https的响应里,发给client。
1、将response中响应的cookie信息在本地进行保存(内存级,文件级)
所以以后访问请求都会携带一个cookie信息,不用用户手动操作,这是浏览器自动做的,服务器会自动进行认证,client访问每一个资源的时候,都需要认证的
假如黑客盗取cookie信息,就以你的cookie登录, 一旦我的cookie泄漏了,就被别人利用了,怎么解决呢?
所以服务器上有很多资源,client也来了,访问服务器资源,服务器叫先登录,会给client一个form表单,那我就以post的方式登录了, 以前是因为把我的信息保持在cookie里,这次我就先在服务器形成一个session对象,用当前用户的基本信息填充,就有了一个内存级或者文件级的,通过办法,形成一个session id,然后把id写回给client,证明登录成功了,所以session id是唯一的,client收到了session id,我本地也有cookie文件,只保存session id,是有保存时间限制的,一天或几天,之后在访问资源,都有携带一个http request cookie:session id,就给服务器推上来,每次推上来,就只需要确认是否在很多session id池当中,存在,就不用再登录了,然后黑客来了,给你client中放木马,拿到你的cookie,我也可以访问了,我在去访问时,也有session id,也可以访问,也会存在,但是我们的信息已经被server服务器维护了,而server服务器一般都是些公司。
所以cookie加session的策略存在的目的:
- 其一:用户信息不在泄漏
- 其二:我们要正确认识cookie加session的策略,不是为了防范客户用户被盗取的,也不是冒认客户去访问某某网站的,而是对异常用户进行识别,然后进行处理。
由于普通的小白,很难去保护自己的数据被盗用,所以我们很难去管理所有人的电脑,但是在公司层面,能保证把自己的东西管理好,服务器方虽然我无法确认你冒认我,但我识别出来,你冒认了,我立马就可以解决这个客户,
所以1、要识别出来,2、解决。但是,我们很难取解决,不可能去把你的用户密码改了,即使识别出来了,也很难去解决,最多是冻结,比如,这个账号在新疆,立马跑到北京,所以这个账号是有问题的,这个账号发生异地登录,就强制你下线,重新登录,黑客只有你的cookie信息,而没有你的账号密码,然后识别,比如这个QQ好友一天之内都在线了,在数据层面,如何解决,就直接将session id失效,就无法登录,就不像上面,怎么失效,只有改别人密码所以这种方案不能杜绝client的cookie丢失的问题,但是可以提出来一下解决方案,对异常client识别出来,并进行解决。