Cross-View Transformers for Real-Time Map-View Semantic Segmentation 论文阅读
论文链接
Cross-View Transformers for Real-Time Map-View Semantic Segmentation
0. Abstract
- 提出了 Cross-View Transformers ,一种基于注意力的高效模型,用于来自多个摄像机的地图视图语义分割
- 使用相机感知的跨视图注意机制隐式学习从单个相机视图到规范地图视图表示的映射
- 该架构由每个视图的卷积图像编码器和跨视图变换层组成,以推断地图视图语义分割
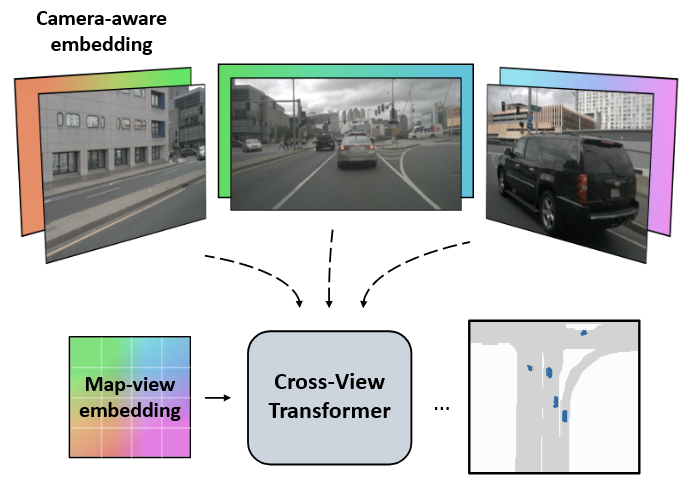
1. Intro
背景
- 基于图像的深度估计很容易出错,因为单眼深度估计与观察者的距离的关系很差
- 基于深度的投影是视图之间映射的相当不灵活且僵化的瓶颈
工作
- 使用该架构将相机视图映射到规范的地图视图表示,该架构不执行任何显式的几何推理,而是通过几何感知的位置嵌入学习在视图之间进行映射
- 多头注意力学习使用学习的地图视图位置嵌入将特征从摄像机视图映射到规范的地图视图表示
- 该模型学习将不同的地图位置链接到两个摄像机以及每个摄像机内的位置
- 交叉视图变换器允许网络隐式地、直接地从数据中学习任何几何变换。通过几何感知位置嵌入尽可能准确地执行下游任务,通过依赖于相机的地图视图位置嵌入来学习深度的隐式估计
2. Related Works
单目三维物体检测
- 单目检测旨在在场景中找到物体,估计它们在三维场景中的真实尺寸、方向和放置位置
- 最常见的方法将问题简化为二维物体检测,并推断单目深度
- 单目检测强烈依赖于一个良好的明确的单目深度估计,这可能更难获得
深度估计
- 深度是许多多视点映射方法的核心要素。经典的运动构造方法利用极线几何和三角测量来显式计算相机外部参数和深度
- 最近的深度学习方法直接从图像回归深度。虽然方便,但显式的深度对于下游任务而言具有挑战性
- 与相机相关,并且需要准确的校准和多个嘈杂估计的融合
地图视图的语义映射
- 输入是在校准过的相机视图中记录的,输出被光栅化到地图上
- 一种常见的技术是假设场景主要是平面的,并将图像到地图视图的转换表示为简单的单应变换
- 第二类方法直接从输入图像生成地图视图预测,没有明确的几何建模
VPN
- 与本文方法思想类似。通过他们提出的视图关系模块 - 一个多层感知器(MLP),从所有视图的输入中输出地图视图特征,学习多个视图之间的共同特征表示
- 缺点
- 没有对场景的几何结构进行建模
- 放弃了标定相机配置中包含的继承归纳偏置,并且需要学习嵌入到网络权重中的隐式相机标定模型
本文工作展示了隐式几何推理与显式几何模型的效果相当。隐式处理几何的附加好处是相比显式模型,在推理速度上有所提高。只需学习一组位置嵌入,注意力机制将重新映射相机到地图视图
3. Cross-view transformers
-
在这个任务中,提供了一组由n个单独视图 ( I k , K k , R k , t k ) k = 1 n (I_k,K_k,R_k,t_k)^n_{k=1} (Ik,Kk,Rk,tk)k=1n 组成的输入图像 I k ∈ R H × W × 3 I_k∈\mathbb{R}^{H×W×3} Ik∈RH×W×3,相机内参 K k ∈ R 3 × 3 K_k∈\mathbb{R}^{3×3} Kk∈R3×3,外参旋转 R k ∈ R 3 × 3 R_k∈\mathbb{R}^{3×3} Rk∈R3×3 和相对于自车中心的平移 t k ∈ R 3 t_k∈\mathbb{R}^3 tk∈R3
-
目标是学习一个高效的模型,从多个相机视图中提取信息,以便预测一个二进制语义分割掩码 y ∈ { 0 , 1 } h × w × C y∈\{0, 1\}^{h×w×C} y∈{0,1}h×w×C 在正交地图视图坐标框架中
-
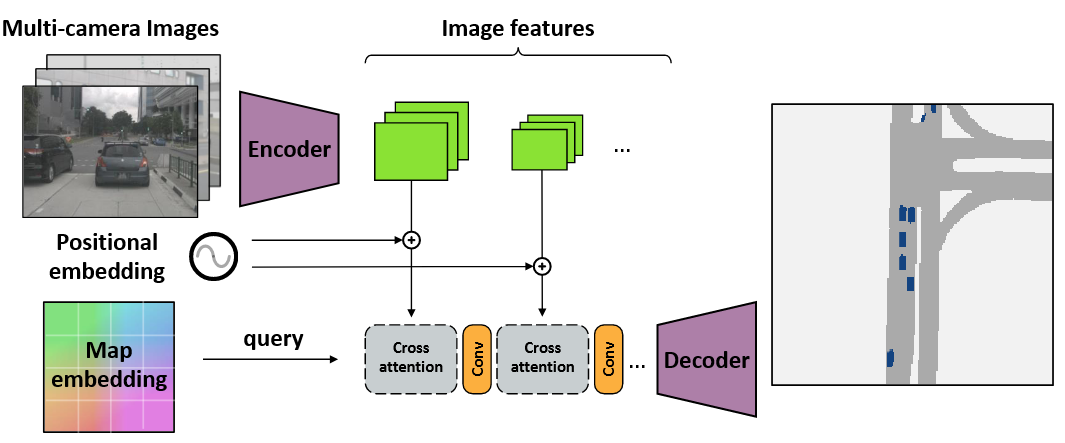
为地图视角语义分割设计了一个简单而有效的编码器-解码器结构
-
图像编码器为每个输入图像生成多尺度特征表示
-
跨视角跨注意机制将多尺度特征聚合成一个共享的地图视角表示。所有相机共享相同的图像编码器,但使用依赖于它们各自相机校准的位置嵌入
-
轻量级的卷积解码器对精炼的地图视角嵌入进行上采样,产生最终的分割输出
-
3.1 Cross-view Attention
-
跨视角注意力的目标是将地图视图表示与图像视图特征相连接
x ( I ) ≃ K k R k ( x ( W ) − t k ) (1) x^{(I)} ≃ K_kR_k(x^{(W)} − t_k) \tag{1} x(I)≃KkRk(x(W)−tk)(1)
≃ ≃ ≃ 表示等比例关系, x ( I ) = ( ⋅ , ⋅ , 1 ) x^{(I)} = (·, ·, 1) x(I)=(⋅,⋅,1) 使用齐次坐标在没有相机视图中准确的深度估计或地图视图中的地面高度估计的情况下,世界坐标 x ( W ) x^{(W)} x(W)是不确定的 。我们不学习深度的显式估计,而是将任何深度不确定性编码在位置嵌入中,并让 Transformer 学习深度的代理
-
从对等式1中的世界坐标和图像坐标之间的几何关系进行重新表述,将其作为余弦相似度在注意机制中使用
s i m k ( x ( I ) , x ( W ) ) = ( R k − 1 K k − 1 x ( I ) ) ⋅ ( x ( W ) − t k ) ∥ R k − 1 K k − 1 x ( I ) ) ∥∥ ( x ( W ) − t k ∥ (2) sim_k(x^{(I)}, x^{(W)}) = \frac{(R^{−1}_k K^{−1}_k x^{(I)}) \cdot (x^{(W)} − t_k)} {∥R^{−1}_k K^{−1}_k x^{(I)})∥∥(x^{(W)} − t_k∥} \tag{2} simk(x(I),x(W))=∥Rk−1Kk−1x(I))∥∥(x(W)−tk∥(Rk−1Kk−1x(I))⋅(x(W)−tk)(2)
这种相似性仍然依赖于准确的世界坐标 w ( W ) w^{(W)} w(W)。用位置编码替换这种相似性的所有几何组件,位置编码可以学习几何和外观特征
考虑相机的位置编码
- 对于每个图像坐标 x i ( I ) x^{(I)}_i xi(I),位置编码从未投影的图像坐标 d k , i = R k − 1 K k − 1 x i ( I ) d_{k,i} = R^{−1}_k K^{−1}_k x^{(I)}_i dk,i=Rk−1Kk−1xi(I) 开始。未投影的图像坐标 d k , i d_{k,i} dk,i 描述了从摄像机 k 的起始点 t k t_k tk 到深度为 1 的图像平面的方向向量。方向向量使用世界坐标
- 使用一个多层感知器(在所有k视图上共享)将这个方向向量 d k , i d_{k,i} dk,i 编码为一个D维的位置嵌入 δ k , i ∈ R D δ_{k,i}∈\mathbb{R}^D δk,i∈RD 。将该位置嵌入与图像特征 ϕ k , i \phi _{k,i} ϕk,i 相结合,作为我们跨视图注意力机制的键
地图视图的潜在嵌入
- 在一个单独的位置嵌入中对两者进行编码。使用MLP将每个相机位置tk转换为一个嵌入 τ k ∈ R D τ_k ∈ \mathbb{R}^D τk∈RD
- 从一个学习到的位置编码
c
(
0
)
∈
R
w
×
h
×
D
c^{(0)} ∈ \mathbb{R}^{w×h×D}
c(0)∈Rw×h×D 开始。地图视图位置编码的目标是产生每个道路元素的3D位置的估计
- 最初,这个估计在所有场景中是共享的,并且可能学习到了每个场景元素在地面平面上的平均位置和高度
- 然后,变换器架构通过多轮计算对这个估计进行细化,得到新的潜在嵌入 c ( 1 ) 、 c ( 2 ) c^{(1)}、c^{(2)} c(1)、c(2) 等
- 每个位置嵌入都能更好地将地图视图坐标投影到三维环境的代理中
- 将地图视图嵌入 c 和相机位置嵌入 τ k τ_k τk 之间的差异用作变换器中的查询
跨视图注意力
-
跨视图变换器通过跨视图注意力机制结合了位置编码。允许每个地图视图坐标关注一个或多个图像位置,但并非每个地图视图位置在每个视图中都有对应的图像块
-
允许注意机制在每个摄像头和每个摄像头内的位置之间进行选择
- 首先将所有视图的相机感知位置嵌入 δ 1 , δ 2 , δ_1, δ_2, δ1,δ2, . . .合并为单个键向量 δ = [ δ 1 , δ 2 , . . . ] δ = [δ_1,δ_2, . . .] δ=[δ1,δ2,...]
- 同时,我们将所有图像特征 ϕ 1 , ϕ 2 , \phi_1,\phi_2, ϕ1,ϕ2, . . .合并为单个值向量 ϕ = [ ϕ 1 , ϕ 2 , . . . ] \phi = [\phi_1,\phi_2, . . .] ϕ=[ϕ1,ϕ2,...],将相机感知位置嵌入 δ δ δ 和图像特征 ϕ \phi ϕ 相结合以计算注意力键
- 最后,我们在键 [ δ , ϕ ] [δ,\phi] [δ,ϕ]、值 ϕ \phi ϕ 和地图视图查询 c − τ k c − τ_k c−τk 之间执行 softmax 交叉注意力
-
softmax 注意力使用键和查询之间的余弦相似度
s i m ( δ k , i , ϕ k , i , c j ( n ) , τ k ) = ( δ k , i + ϕ k , i ) ⋅ ( c j ( n ) − τ k ) ∥ δ k , i + ϕ k , i ∥∥ c j ( n ) − τ k ∥ (3) sim(δ_{k,i}, \phi_{k,i}, c^{(n)}_j , τ_k) = \frac{(δ_{k,i} + \phi_{k,i})\cdot(c^{(n)}_j − τ_k)} {∥δ_{k,i} + \phi_{k,i}∥∥c^{(n)}_j − τ_k∥} \tag{3} sim(δk,i,ϕk,i,cj(n),τk)=∥δk,i+ϕk,i∥∥cj(n)−τk∥(δk,i+ϕk,i)⋅(cj(n)−τk)(3)
3.2 A cross-view transformer architecture
- 网络的第一阶段为每个输入图像建立相机视图表示
- 将每个图像 I i I_i Ii 输入特征提取器,并获得多分辨率补丁嵌入 ϕ 1 1 , ϕ 1 2 , . . . , ϕ n R {\phi_1^1, \phi^2_1,..., \phi_n^R} ϕ11,ϕ12,...,ϕnR,其中 R 是我们考虑的分辨率数量(实验中 R=2)
- 单独处理每个决议。从最低分辨率开始,并使用跨视图注意将所有图像特征投影到地图视图中
- 然后,细化地图视图嵌入并重复该过程以获得更高分辨率
- 最后,我们使用三个上卷积层来产生全分辨率输出
4. Implementation Details
架构
- 使用(并微调)预训练的 EfficientNet-B4 来计算两个不同尺度的图像特征 —— (28, 60) 和 (14, 30),分别对应于 8 倍和 16 倍的缩小
- 初始地图视图位置嵌入是学习参数 w × h × D 的张量,其中 D = 128。为了计算效率,选择 w = h = 25,因为交叉注意力函数随网格大小呈二次方增长
- 编码器由两个交叉注意力块组成:一个用于每个尺度的块特征
- 使用具有4个头和嵌入尺寸 d h e a d = 64 d_{head} = 64 dhead=64 的多头注意力
- 解码器由三个(双线性上采样 + 卷积)层组成,将潜在表示上采样到最终输出尺寸
5. Results
数据集
利用 nuScenes 数据集,数据集是一个包含1000个不同场景的集合,这些场景在各种天气、时间和交通条件下采集
评估
对于地图视图车辆分割,有两种常用的评估设置
- 设置1在车辆周围使用一个100m×50m的区域,并以25cm的分辨率对地图进行取样
- 设置2在车辆周围使用一个100m×100m的区域,并以50cm的取样分辨率
使用模型预测和地图视角标签之间的交并比(IoU)分数作为主要性能指标
5.1 Comparison to prior work
- 将模型与在线地图上五种最具竞争力的现有方法进行比较
- 与金字塔占用网络(PON)、正交特征变换(OFT)、视图解析网络(VPN)、时空聚合(STA)、Lift-Splat-Shoot 和火热 FIERY 比较
- 在这两种设置中,我们的交叉视图转换器和 FIERY 都明显优于所有替代方法
5.2 Ablations of cross-view attention
-
方法的核心要素是跨视图注意机制。它将相机感知嵌入和图像特征结合起来作为键,并将学习到的地图视图位置嵌入作为查询
-
地图视图嵌入允许在多次迭代中更新,而相机感知嵌入包含一些几何信息

-
系统最重要的组成部分是相机感知的位置嵌入。它赋予注意力机制推理场景几何布局的能力。如果没有它,注意力就必须依靠图像特征来揭示自己的位置
-
仅图像特征很难正确连接地图视图和摄像机视图视角。它还需要明确推断每个图像所面向的方向,以消除不同视图的歧义
-
另一方面,仅靠纯粹的几何相机感知位置嵌入也是不够的。该网络可能使用语义和几何线索来对齐地图视图和相机视图,特别是在地图视图嵌入的细化之后
-
使用单个固定地图视图嵌入也会降低模型的性能。最终模型在其所有注意力组件下表现最佳
5.3 Camera-aware positional embeddings

- 不使用任何位置嵌入的效果很差。注意机制难以定位特征并识别摄像头
- 个摄像头学习的嵌入效果出人意料地好。这可能是因为摄像机校准基本保持静态,而学习到的嵌入则将所有几何信息整合在一起
- 使用线性或随机傅立叶投影的相机感知嵌入效果最好
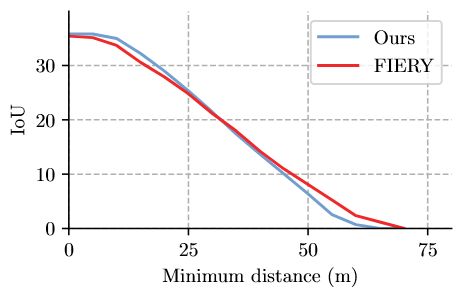
5.4 Accuracy vs distance

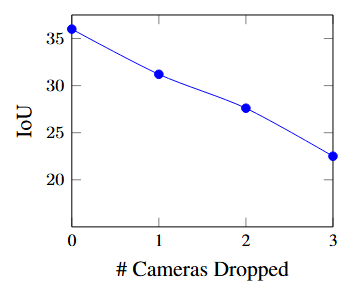
5.5 Robustness to sensor dropout
-
采用在所有六个输入上训练的模型,通过在验证集中对每个样本随机删除 m 个摄像头来评估交并比(IoU)指标
-
性能随着删除的摄像头数量的线性下降。这是相当直观的,因为不同的摄像头仅有轻微的重叠
-
值得注意的是,基于Transformer的模型通常对摄像头丢失具有相当强的鲁棒性,整体性能不会下降到场景的未观察区域以外
5.6 Qualitative Results
- 对于每一行,我们展示了六个输入摄像机视图以及预测的地图视图分割和地面真实分割
- 提出的方法可以准确地分割附近的车辆,但对于远处或遮挡的车辆无法感知良好
5.7 Geometric reasoning in cross-view attention
-
可视化了地图视角中几个点的图像视角注意力。每个点对应车辆的一个部分。根据定性证据,注意机制可以突出显示相互对应的地图视角和摄像头视角位置

6. Conclusion
- 提出了一种基于跨视图变换器架构的地图视图分割方法,该方法建立在考虑相机位置的位置嵌入之上。所提出的方法实现了最先进的性能,易于实施,并且实时运行