数据库的增删查改(CRUD)基础版
CRUD: create增加、retrieve查询、update更新、delete删除
注意一点:MySQL对大小写是不敏感的
目录
新增(create)
全列插入
指定列插入
多行插入
查询(Retrieve)
列查询
全列查询
指定列查询
表达式查询
给查询结果指定别名
查询去重
查询的同时进行排序
条件查询(where)
实操
分页查询(limit)
修改(update)
删除(delete)
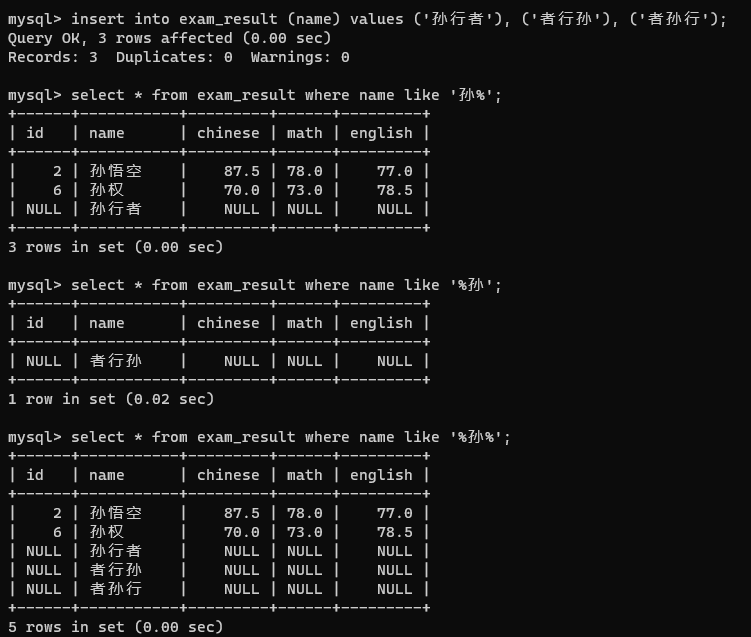
新增(create)
实际上sql中使用insert往表里插入数据
(前提:选定好数据库并创建好表)
全列插入
insert into 表名 values(列,列...)
如果要插入中文,对于MySQL5来说,要显式地设定好字符集
诶我忘记加了怎么办?趁着现在数据库还没啥东西,删了重建就行了(手动滑稽~
⚠插入的列类型要和列头匹配

插入datetime类型的数据时,插入的数据要按照格式 YYYY-MM-DD HH:MM:SS 来填充,数据库会自动把你输入的时间转为8个字节的时间戳

sql是一种编程语言,我们可以使用自带的库函数now()把当前时间插入到里面
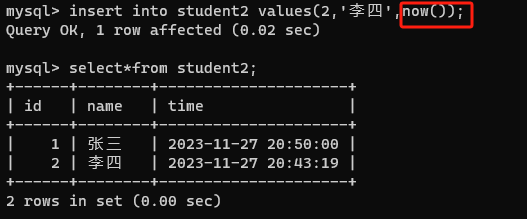
指定列插入
第二种错误换一种写法就对了

表示这一次插入只插入id这一列(可以指定多个列名,使用","分割即可)
也可以只插入名字到name那一列
![]()
现在看看表的状态
没有问题😊
多行插入

每条记录用","分割就行
这种多行插入执行效率会比一行一行插入高
MySQL是一种客户端-服务器结构的程序,通过网络互传数据
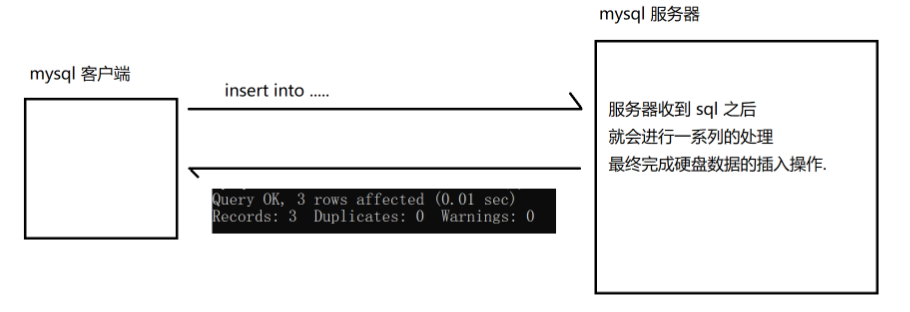
如果分多个sql进行,意味这个过程中就会有多次网络交互,服务器收到请求后也要进行多次对应处理(语法检查,数据校验,定位插入数据...),这样效率就很低
如果一次操作,虽然单次操作消耗时间长一点,但是网络开销、服务器检查开销都只用进行1次
查询(Retrieve)
列查询
全列查询
select * from 表名;这里的*指的是通配符,可以表示任何一列
在公司中一般不要敲select * ,因为一旦数据量很大,这个操作会产生大量的硬盘IO和网络IO,可能把硬盘或网卡的带宽吃满(类似于堵车)
带宽吃满了,此时服务器就无法正常相应其他客户端的请求了
搜狗公司的解决方式:
给每个服务器配上两个网卡,一个用来传输数据,一个用来控制命令
数据网卡吃满了,不耽误另一个控制网卡来接收
阿里巴巴的解决方式:
用钱解决,直接上万兆网卡,相比于千兆网卡,这个更不容易堵死
相当于4条车道扩充到40条车道
指定列查询
指定列查询可以只查一两列,消耗的硬盘/网络带宽只有之前的几分之一
select 列名, 列名..... from 表名;
这种查询方式也不是万无一失,如果查的列行数巨多,也可能把路堵死
表达式查询
把查询出的每一行带入表达式进行计算
现在有这么一张表
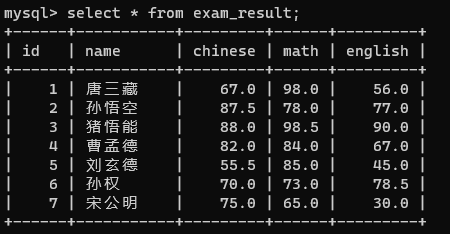
查询每个同学英语成绩+10的情况
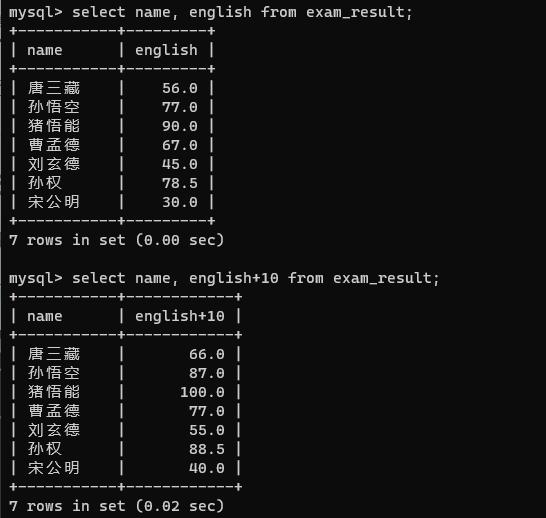
1.当前的表达式查询,并不会修改服务器硬盘中存储的数据本体,只是在查询结果的基础上进行计算的,得到的是一个临时表,查询操作结束,临时表里面的数据就消散了
所有的select都只是在操作临时表
2.此处查询出来的临时表,每个列的类型不再受限于原始表
原始表中,english列的数据类型是decimal(3,1),即长度限制为3,小数点后限制1位
但是在临时表中我们发现100.0这已经不符合长度为3这个限制了
=========================================================================
表达式还可以对多个列进行运算,但无法针对行和行之间进行运算
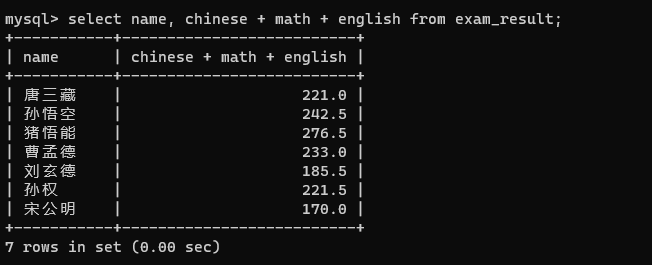
查询的表达式是啥,临时表的列名就是啥,如果列名都很长,最后临时表的列名可读性会变差
那就可以用下面的方法
给查询结果指定别名
通俗来讲就是起绰号
select 表达式 as 别名 from 表名;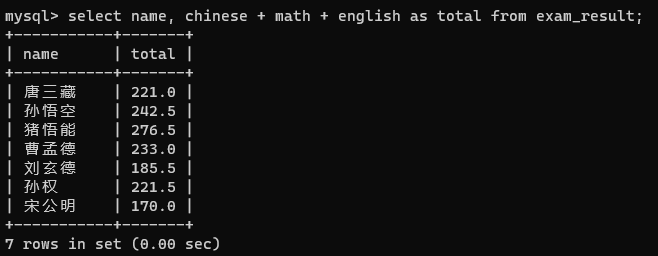
别名不一定要给列起,也可以给表起
查询去重
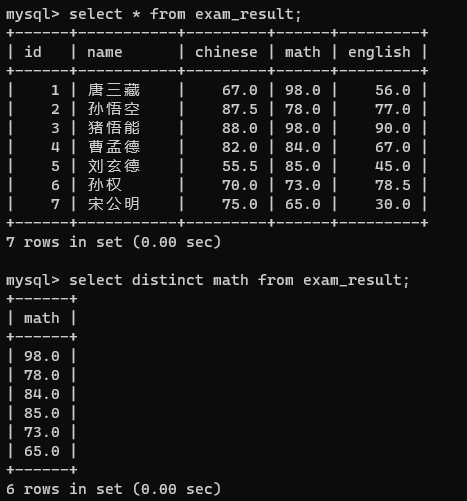
查询结果中如果存在重复的元素,就只保留一个
select distinct 列名 from 表名;
如果列里面有数据重复就把值相同的记录合并成一个
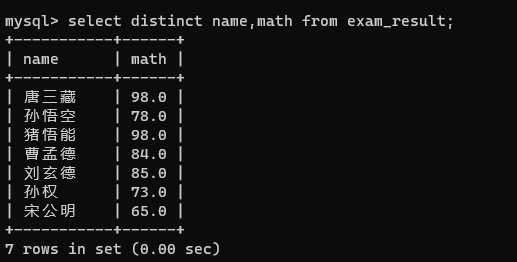
如果是多个列一起查重,那只有多个列的值是相同的才算是重复
比如name和math一起去重,虽然math这一列有相同的值,但是name列两个98对应的名字不一样啊,所以就不去重
查询的同时进行排序
select 列名 from 表名 order by 列名;如果一个查询语句没有order by,那反馈出来的临时表数据之间的顺序是不可预期的
所以一定要有一个order by确定一个顺序
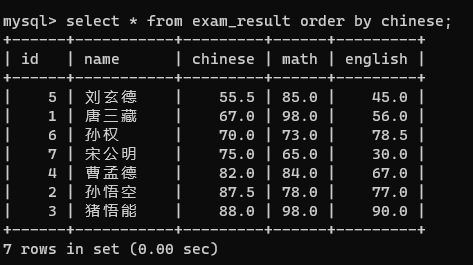
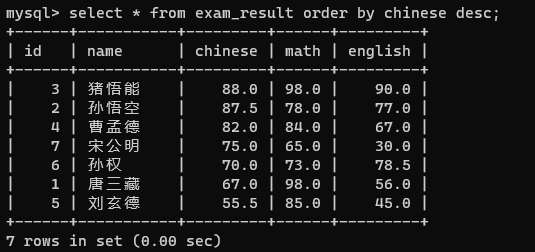
这里默认是一个升序排序,在刚刚查询语句后面加个desc就是降序了
此处的desc ≠ describe 而是 = descand(降序)
order by可以指定多个列来进行排序,此时排序的列是带有优先级的
前面的列(紧跟着order by的)优先级高,后面的列优先级低,优先级高的列值相同才会比较优先级低的列
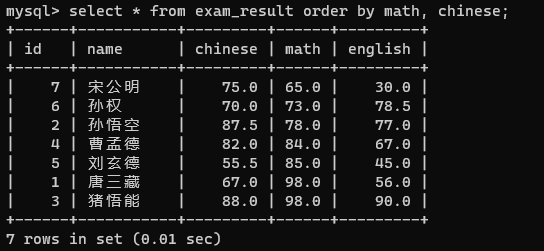
先按照数学成绩排序,如果数学成绩相同,再按照语文成绩排序
条件查询(where)
查询的时候指定筛选条件,条件满足这个数据就被保留;不满足就直接跳过
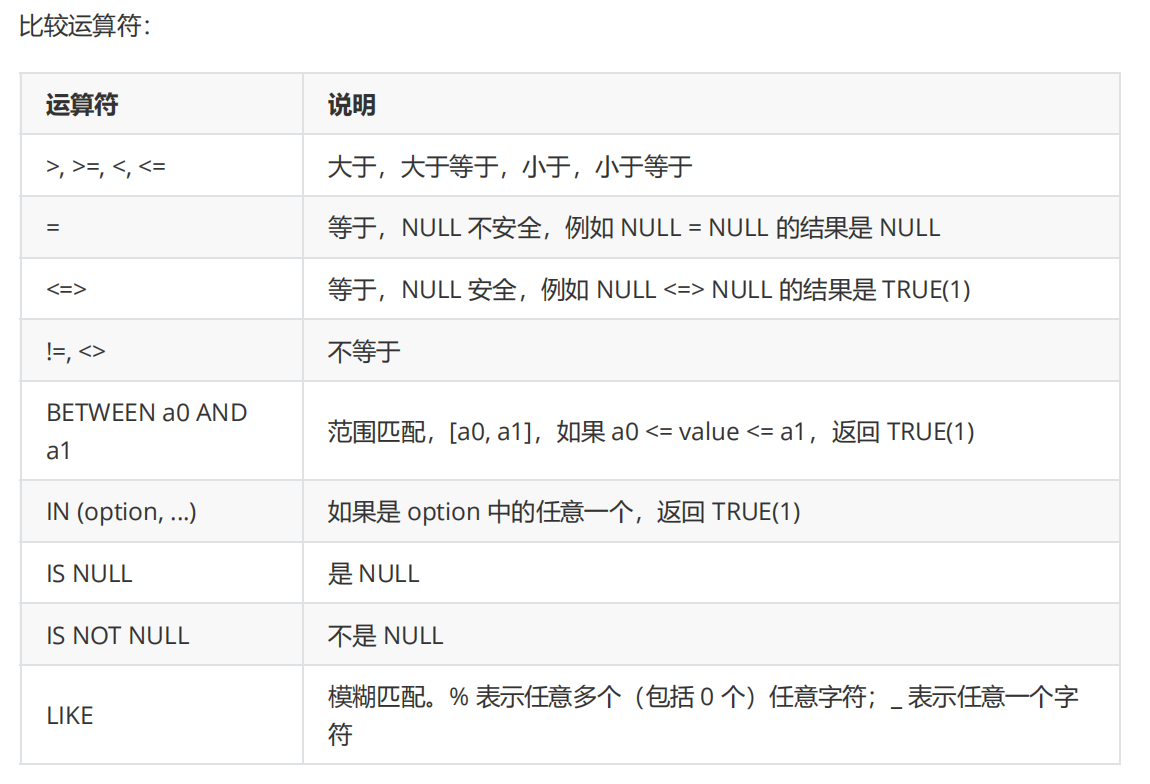
注意:
1. = 在条件查询中表示比较是否相等(和C语言的==含义一样)
这里的NULL=NULL=>NULL其实相当于FALSE的意思,表示条件不成立
NULL表示单元格没填,这里的理解是没填和没填是不同的,不具有可比性
而下面的<=>的 NULL=NULL=>TRUE,这里的理解是没填和没填是相同的,都是空嘛~
2. 模糊匹配,指的是不要求完全一样,只要满足一定的规则就算匹配了
逻辑运算符
实操
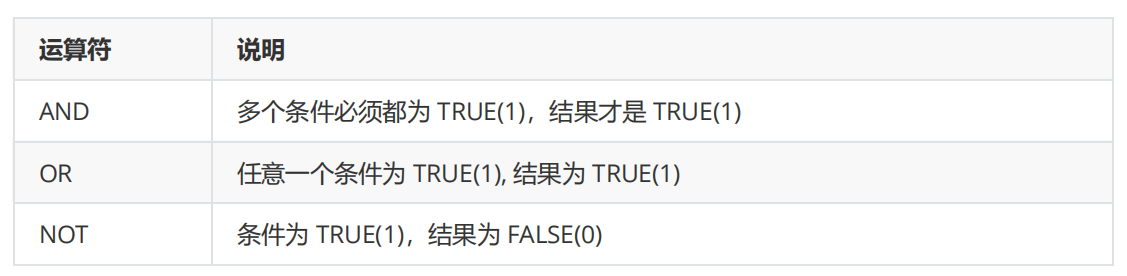
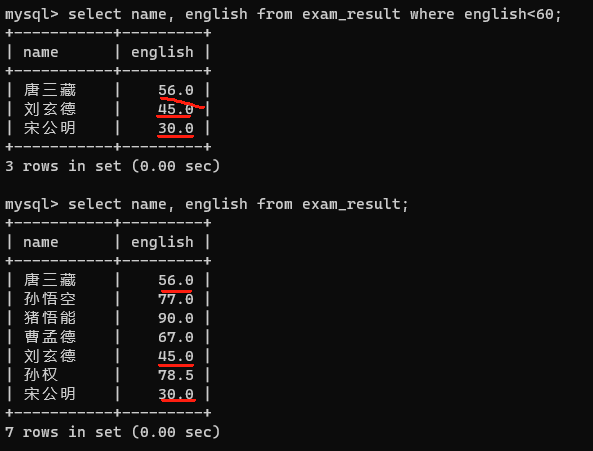
1.查询英语成绩<60分的同学
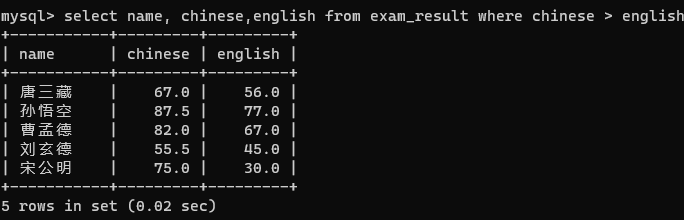
2.查询语文成绩逼英语成绩好的同学
3.查询总分200分以下的同学

起个别名能不能让列更简洁呢?
![]()
显然不行,这里定义的别名不能被where感知到
⚠SQL执行顺序:
1.取出一条记录(遍历表);
2.把记录带入条件,判定是否满足
3.如果条件满足,再把select后面指定的列取出来,并进行一些表达式运算
而上面的过程是先执行where,后执行表达式的取别名操作
4.查询语文成绩大于80分,且英语成绩大于80分的同学

5.查询语文成绩大于80分,或英语成绩大于80分的同学
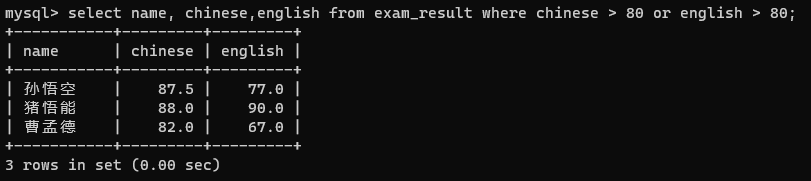
6. and的优先级大于or
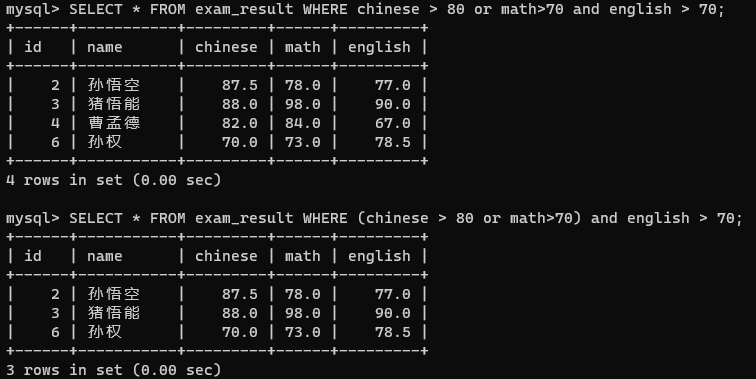
第一条语句先执行math>70 and english>70,再执行or
对于曹孟德来说,and语句执行是false的,但是Chinese>80这个条件是true的,true or false = true
所以曹孟德同学在这张表里
第二条语句先执行括号里面的or语句,再执行and
曹孟德同学or语句为true,但是english >70 这个条件为false, true and false = false
所以此时曹孟德同学不会在这张表里
其实真正写代码的时候,我们不用过多在乎优先级,我们只要用括号显式表示哪个式子先执行就行了
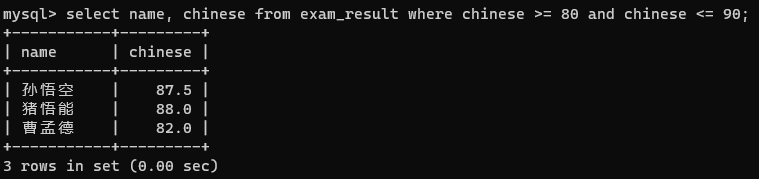
7. 查询语文成绩在 [80, 90] 分的同学及语文成绩 (between ... and ...)
第一种方法
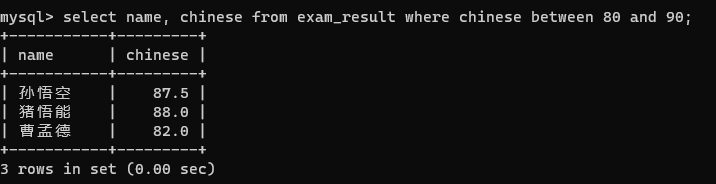
第二种方法
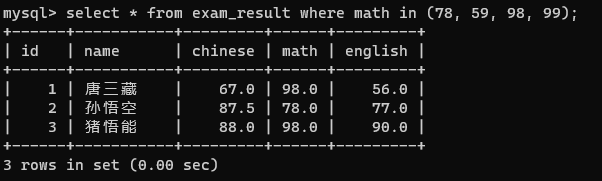
8.查询数学成绩是 78 或者 59 或者 98 或者 99 分的同学及数学成绩(in)
9. like
%:匹配任意个任意字符,可以匹配到0个字符
_:匹配一个字符
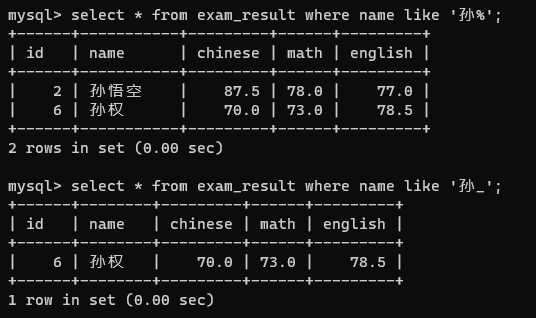
写成%孙就是以孙为结尾;%孙%表示查询名字里有孙的名字
_用法和%差不多,只不过 '_'写在前面只能匹配一个字符
10 is (not) null;
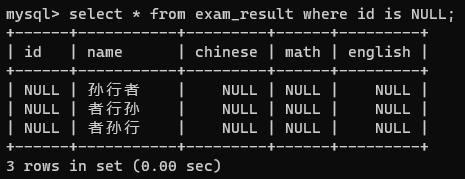
但是不要用 = 号

这里的null = null -> null -> false -> 条件没有满足
分页查询(limit)
我们上面提到select * 这个操作很危险,可能一次查询出来的内容太多辣
分页查询就是解决上面问题的方案。
我们常见的网站也有分页的效果
分页查询通过关键字limit来限制这一次的查询最多能查多少记录
offset:描述当前结果从第几条开始获取

修改(update)
update 表名 set 列名 = 值 where 条件;注意:update里面创建出来的表不是临时表!!!
这里的set是设置的意思,此处的 = 就是赋值了
where 条件:表示要修改哪些行,定位的作用;条件不写就是修改所有了
1. 把孙悟空数学成绩改成80分
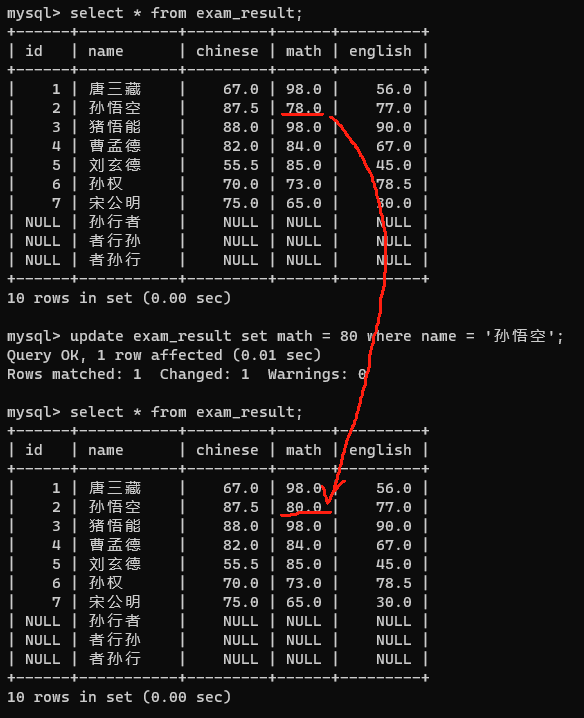
2. 把曹孟德数学改成60分,语文改成70分

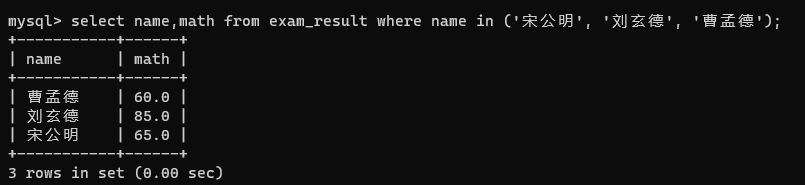
3. 捞捞同学:将总成绩倒数前三的3位同学数学成绩+30分
先查出总成绩倒数前三的同学分别是何方神圣

再查出这三位同学数学成绩分别是咋样的
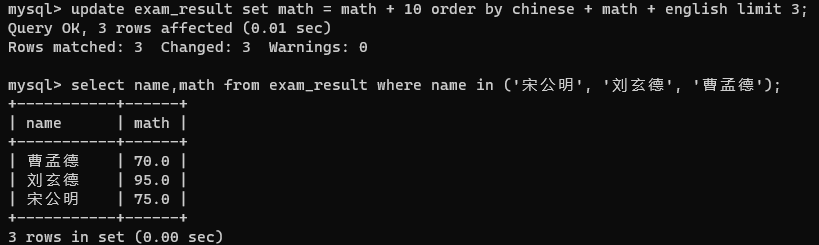
期望通过update给他们数学成绩加30分
![]()
但是刘玄德同学+30分后变成115.0不符合decimal(3,1)的类型了
而且第二行一旦出错,第一行和第三行的成绩也加不上去
这个是sql的一个特性:“事务”,给定的一个sql语句就是一个整体,要么整个执行成功,要是失败就全部都不执行。我下一篇博客会讲到😊
🆗我们看到刘玄德同学数学还是挺不错的,捞给他30分怕是顶破天了,我们现在只给他们+10分
update也是蛮危险的操作,因为它撤回不了!!!
删除(delete)
delete from 表名 where 条件;删掉孙悟空的成绩
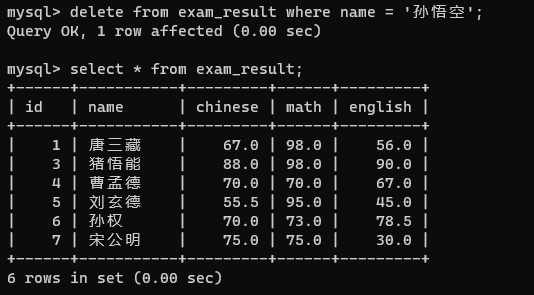
如果删除语句没有指定条件,就会全部删除
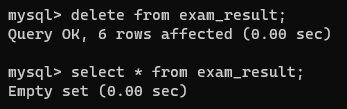
注意:这里的delete只是删除了表里面的数据,而drop table则是把表和表里的数据都删掉了
delete也是一个危险操作!!!
后续待更新~~