Python基于Pytorch Transformer实现对iris鸢尾花的分类预测,分别使用CPU和GPU训练
1、鸢尾花数据iris.csv

iris数据集是机器学习中一个经典的数据集,由英国统计学家Ronald Fisher在1936年收集整理而成。该数据集包含了3种不同品种的鸢尾花(Iris Setosa,Iris Versicolour,Iris Virginica)各50个样本,每个样本包含了花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)四个特征。
iris数据集的主要应用场景是分类问题,在机器学习领域中被广泛应用。通过使用iris数据集作为样本集,我们可以训练出一个分类器,将输入的新鲜鸢尾花归类到三种品种中的某一种。iris数据集的特征数据已经被广泛使用,也是许多特征选择算法和模型选择算法的基础数据集之一。
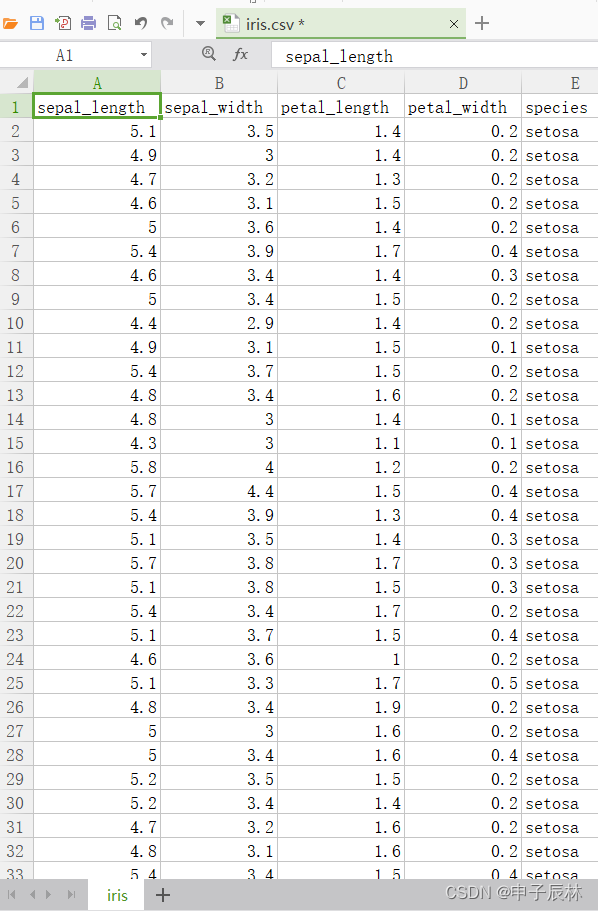
总共150条数据
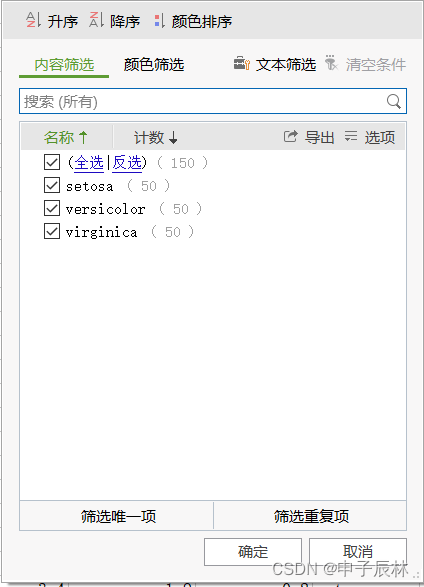
数据分布均匀,每种分类50条数据。
2、Transformer模型 CPU版本
# -*- coding:utf-8 -*-
import torch # 导入 PyTorch 库
from torch import nn # 导入 PyTorch 的神经网络模块
from sklearn import datasets # 导入 scikit-learn 库中的 dataset 模块
from sklearn.model_selection import train_test_split # 从 scikit-learn 的 model_selection 模块导入 split 方法用于分割训练集和测试集
from sklearn.preprocessing import StandardScaler # 从 scikit-learn 的 preprocessing 模块导入方法,用于数据缩放
print("# 加载鸢尾花数据集")
# 加载鸢尾花数据集,这个数据集在机器学习中比较著名
iris = datasets.load_iris()
X = iris.data # 对应输入变量或属性(features),含有4个属性:花萼长度、花萼宽度、花瓣长度 和 花瓣宽度
y = iris.target # 对应目标变量(target),也就是类别标签,总共有3种分类
print("拆分训练集和测试")
# 把数据集按照80:20的比例来划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
print("数据缩放")
# 对训练集和测试集进行归一化处理,常用方法之一是StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
print("数据转tensor类型")
# 将训练集和测试集转换为PyTorch的张量对象并设置数据类型
X_train = torch.tensor(X_train).float()
y_train = torch.tensor(y_train).long()
X_test = torch.tensor(X_test).float()
y_test = torch.tensor(y_test).long()
# 定义 Transformer 模型
class TransformerModel(nn.Module):
def __init__(self, input_size, num_classes):
super(TransformerModel, self).__init__()
# 定义 Transformer 编码器,并指定输入维数和头数
self.encoder_layer = nn.TransformerEncoderLayer(d_model=input_size, nhead=1)
self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=1)
# 定义全连接层,将 Transformer 编码器的输出映射到分类空间
self.fc = nn.Linear(input_size, num_classes)
def forward(self, x):
# 在序列的第2个维度(也就是时间步或帧)上添加一维以适应 Transformer 的输入格式
x = x.unsqueeze(1)
# 将输入数据流经 Transformer 编码器进行特征提取
x = self.encoder(x)
# 通过压缩第2个维度将编码器的输出恢复到原来的形状
x = x.squeeze(1)
# 将编码器的输出传入全连接层,获得最终的输出结果
x = self.fc(x)
return x
print("创建模型")
# 初始化 Transformer 模型
model = TransformerModel(input_size=4, num_classes=3)
print("定义损失函数和优化器")
# 定义损失函数(交叉熵损失)和优化器(Adam)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
print("训练模型")
# 训练模型,对数据集进行多次迭代学习,更新模型的参数
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播计算输出结果
outputs = model(X_train)
loss = criterion(outputs, y_train)
# 反向传播,更新梯度并优化模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印每10个epoch的loss值
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
print("测试模型")
# 测试模型的准确率
with torch.no_grad():
# 对测试数据集进行预测,并与真实标签进行比较,获得预测
outputs = model(X_test)
_, predicted = torch.max(outputs.data, 1)
accuracy = (predicted == y_test).sum().item() / y_test.size(0)
print(f'Test Accuracy: {accuracy:.2f}')
控制台输出:
# 加载鸢尾花数据集
拆分训练集和测试
数据缩放
数据转tensor类型
创建模型
定义损失函数和优化器
训练模型
Epoch [10/100], Loss: 0.5863
Epoch [20/100], Loss: 0.3978
Epoch [30/100], Loss: 0.2954
Epoch [40/100], Loss: 0.1765
Epoch [50/100], Loss: 0.1548
Epoch [60/100], Loss: 0.1184
Epoch [70/100], Loss: 0.0847
Epoch [80/100], Loss: 0.2116
Epoch [90/100], Loss: 0.0941
Epoch [100/100], Loss: 0.1062
测试模型
Test Accuracy: 0.97
正确率97%
3、Transformer模型 GPU版本
# -*- coding:utf-8 -*-
import torch # 导入 PyTorch 库
from torch import nn # 导入 PyTorch 的神经网络模块
from sklearn import datasets # 导入 scikit-learn 库中的 dataset 模块
from sklearn.model_selection import train_test_split # 从 scikit-learn 的 model_selection 模块导入 split 方法用于分割训练集和测试集
from sklearn.preprocessing import StandardScaler # 从 scikit-learn 的 preprocessing 模块导入方法,用于数据缩放
print("# 检查GPU是否可用")
# Check if GPU is available
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("# 加载鸢尾花数据集")
# 加载鸢尾花数据集,这个数据集在机器学习中比较著名
iris = datasets.load_iris()
X = iris.data # 对应输入变量或属性(features),含有4个属性:花萼长度、花萼宽度、花瓣长度 和 花瓣宽度
y = iris.target # 对应目标变量(target),也就是类别标签,总共有3种分类
print("拆分训练集和测试")
# 把数据集按照80:20的比例来划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
print("数据缩放")
# 对训练集和测试集进行归一化处理,常用方法之一是StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
print("数据转tensor类型")
# 将训练集和测试集转换为PyTorch的张量对象并设置数据类型,加上to(device)可以运行在GPU上
X_train = torch.tensor(X_train).float().to(device)
y_train = torch.tensor(y_train).long().to(device)
X_test = torch.tensor(X_test).float().to(device)
y_test = torch.tensor(y_test).long().to(device)
# 定义 Transformer 模型
class TransformerModel(nn.Module):
def __init__(self, input_size, num_classes):
super(TransformerModel, self).__init__()
# 定义 Transformer 编码器,并指定输入维数和头数
self.encoder_layer = nn.TransformerEncoderLayer(d_model=input_size, nhead=1)
self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=1)
# 定义全连接层,将 Transformer 编码器的输出映射到分类空间
self.fc = nn.Linear(input_size, num_classes)
def forward(self, x):
# 在序列的第2个维度(也就是时间步或帧)上添加一维以适应 Transformer 的输入格式
x = x.unsqueeze(1)
# 将输入数据流经 Transformer 编码器进行特征提取
x = self.encoder(x)
# 通过压缩第2个维度将编码器的输出恢复到原来的形状
x = x.squeeze(1)
# 将编码器的输出传入全连接层,获得最终的输出结果
x = self.fc(x)
return x
print("创建模型")
# 初始化 Transformer 模型
model = TransformerModel(input_size=4, num_classes=3).to(device)
print("定义损失函数和优化器")
# 定义损失函数(交叉熵损失)和优化器(Adam)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
print("训练模型")
# 训练模型,对数据集进行多次迭代学习,更新模型的参数
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播计算输出结果
outputs = model(X_train)
loss = criterion(outputs, y_train)
# 反向传播,更新梯度并优化模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印每10个epoch的loss值
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
print("测试模型")
# 测试模型的准确率
with torch.no_grad():
# 对测试数据集进行预测,并与真实标签进行比较,获得预测
outputs = model(X_test)
_, predicted = torch.max(outputs.data, 1)
accuracy = (predicted == y_test).sum().item() / y_test.size(0)
print(f'Test Accuracy: {accuracy:.2f}')
控制台输出:
# 检查GPU是否可用
# 加载鸢尾花数据集
拆分训练集和测试
数据缩放
数据转tensor类型
创建模型
定义损失函数和优化器
训练模型
Epoch [10/100], Loss: 0.6908
Epoch [20/100], Loss: 0.4861
Epoch [30/100], Loss: 0.3541
Epoch [40/100], Loss: 0.2136
Epoch [50/100], Loss: 0.2149
Epoch [60/100], Loss: 0.1263
Epoch [70/100], Loss: 0.1227
Epoch [80/100], Loss: 0.0685
Epoch [90/100], Loss: 0.1775
Epoch [100/100], Loss: 0.0889
测试模型
Test Accuracy: 0.97
正确率:97%
4、代码说明
在这段代码中,我们首先通过 torch.cuda.is_available() 检查GPU是否可用,如果GPU可用,则将计算转移到GPU,以便更快地训练模型。
然后使用 datasets.load_iris() 函数加载鸢尾花数据集。对于机器学习任务,我们通常会将数据集分成训练集和测试集,以便评估模型的性能。在本例中,使用 train_test_split() 方法将数据集分成训练集和测试集。
接下来,我们使用 StandardScaler 对数据进行缩放,以获得更好的模型性能。然后将数据集转换为PyTorch tensor格式,并使用 to() 将它们移动到GPU上(如果存在)。
然后定义了一个类名为 TransformerModel 的模型,并继承了 nn.Module。这个模型包括 TransformerEncoder 层、全局平均池化层和线性层。在这个模型中,输入是一组4维数值(表示鸢尾花的4种特征),输出需要有3个类别,因此最后一层的输出大小设置为3。
接下来,我们初始化模型并将其移动到GPU上,之后定义损失函数和优化器以进行模型的优化。在每个迭代步骤内进行前向传递、反向传递和梯度更新,同时打印出损失值以便调试和优化模型。经过若干次迭代后,我们使用测试集对模型进行测试,最后输出测试集的精度值。