python爬虫-某公开数据网站实例小记
注意!!!!某XX网站逆向实例仅作为学习案例,禁止其他个人以及团体做谋利用途!!!
第一步:分析页面和请求方式
此网站没有技巧的加密,仅是需要携带cookie和请求格式,因此本文主要进行分析重点的2次请求
第二步:请求页面并分析请求
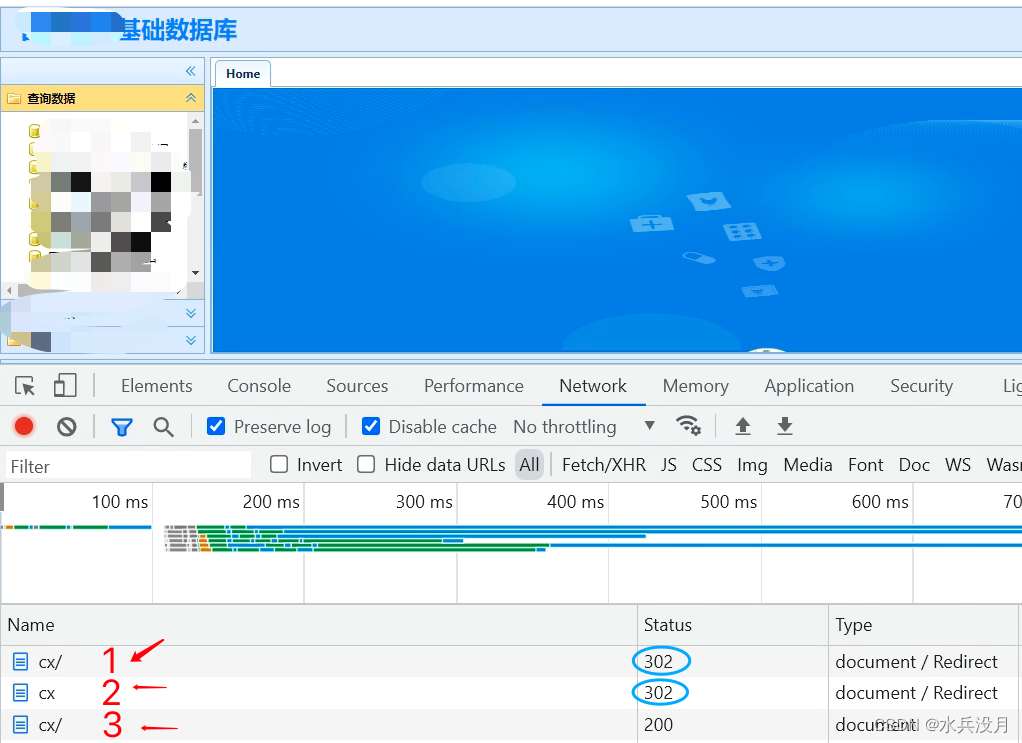
可以看到出现了三次请求,前两次请求为302 重定向,第三次请求状态为200
第三步:分析第一次请求
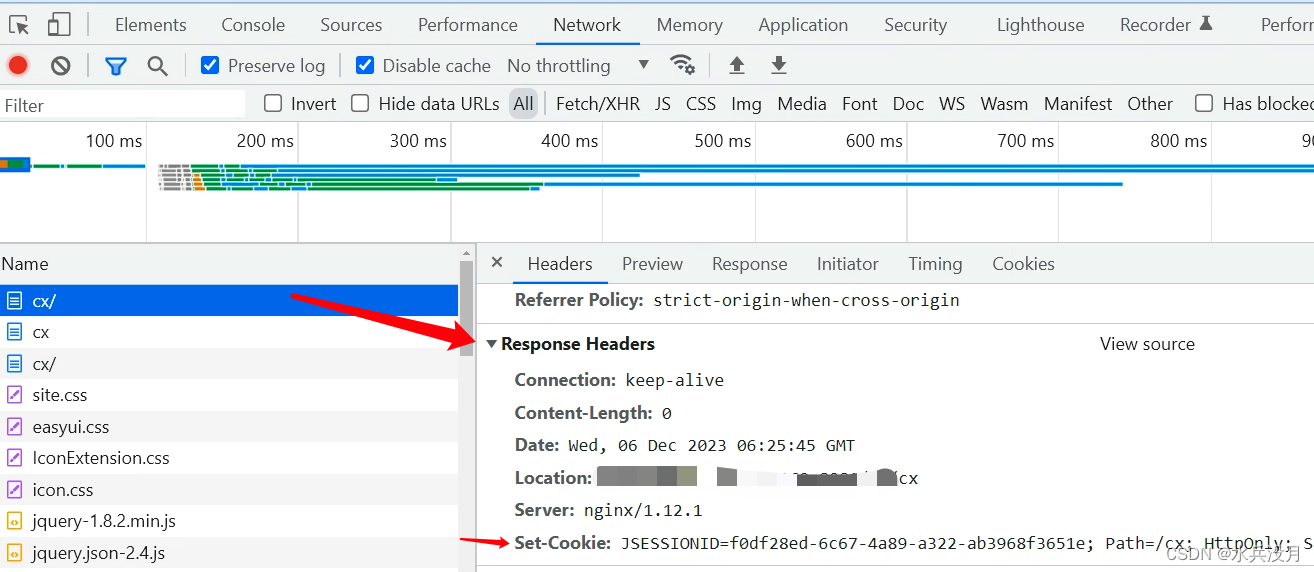

可以看到第一次请求在响应headers 可以获得set-cookie,同时也可以看到第一次请求后被重定向到指定地址Location
第四步:分析第二次请求,注意!注意!注意!这步请求很重要

可以看到第二次请求使用的是第一次请求后响应的重定向网址(也就是第一次请求302响应得到的location)和cookie,这步很重要。
第一请求——>302(重定向)——>response.headers.Location和set-cookie
第二次请求(第一次请求的response.headers.Location)—>302(重定向)——>response.headers.Location (第二次请求后的重定向网址可以忽略,可以直接请求目标网址)
第五步:请求目标链接

可以看到报文头中携带了cookie和内容类型。注意这两个参数很重要。
第六步:上代码
# -*- coding:utf-8 -*-
# @Time : 2023/12/6 12:01
# @Author: 水兵没月
# @File : 某网址-cookie.py
# @Software: PyCharm
import json
import random
import requests
headers = {
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"no-cache",
"Connection":"keep-alive",
"Content-Type":"application/json",
"Host":"XXX.XXX.XX.XXX:8081",
"Pragma":"no-cache",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
}
# 第一次请求
res = requests.Session().get("http://XXX.XXX.XX.XXX:8081/cx/", verify=False,headers=headers, allow_redirects=False) # verify=False,
cookies = res.cookies.items()
cookie = ''
for name, value in cookies:
cookie += '{0}={1};'.format(name, value)
print(cookie)
headers['Cookie'] = cookie
# 第二次请求
requests.Session().get(res.headers.get("Location"), verify=False,headers=headers, allow_redirects=False)
# 目标请求
url = "http://XXX.XXX.XX.XXX:8081/cx/api/cxsj/syscqyinfo/list"
data = {"page":1,"rows":100,"conditionItems":[]}
print(headers)
res = requests.session().post(url=url, data=json.dumps(data), headers=headers, verify=False) #
res.encoding = 'UTF-8'
print(res.text)