spark的安装与使用:一键自动安装
使用shell脚本一键下载、安装、配置spark(单机版)
1. 把下面的脚本复制保存为/tmp/install_spark.sh文件
#!/bin/bash
# sprak安装版本
sprak_version="2.4.0"
# sprak安装目录
sprak_installDir="/opt/module"
# hadoop安装路径,修改为自己的
HADOOP_HOME=/opt/module/hadoop-3.1.3
# java安装路径,修改为自己的
JAVA_HOME=/opt/module/jdk1.8.0_381
install_spark() {
local version=$1
local installDir=$2
# 下载地址
local downloadUrl="https://archive.apache.org/dist/spark/spark-$version/spark-$version-bin-hadoop2.7.tgz"
# 检查安装目录是否存在,不存在则创建
if [ ! -d "${installDir}" ]; then
echo "创建安装目录..."
sudo mkdir -p "${installDir}"
fi
if test -f /tmp/spark-"$version"-bin-hadoop2.7.tgz; then
echo "/tmp/spark-$version-bin-hadoop2.7.tgz文件已存在"
else
# 下载并解压 spark
echo "开始下载spark..."
wget "$downloadUrl" -P /tmp
fi
echo "开始解压spark..."
tar -zxvf "/tmp/spark-$version-bin-hadoop2.7.tgz" -C "${installDir}"
mv "${installDir}/spark-${version}-bin-hadoop2.7" "${installDir}/spark-${version}"
if test -n "$(grep '#SPARK_HOME' ~/.bashrc)"; then
echo "SPARK_HOME已存在"
else
# 设置spark用户环境变量
echo >> ~/.bashrc
echo '#SPARK_HOME' >> ~/.bashrc
echo "export SPARK_HOME=${installDir}/spark-${version}" >> ~/.bashrc
echo 'export PATH=$PATH:$SPARK_HOME/bin' >> ~/.bashrc
fi
# 配置 spark
echo "配置spark运行环境"
cp "${installDir}/spark-${version}/conf/spark-env.sh.template" "${installDir}/spark-${version}/conf/spark-env.sh"
echo 'export SPARK_DIST_CLASSPATH=$('"$HADOOP_HOME"'/bin/hadoop classpath)' >> "${installDir}/spark-${version}/conf/spark-env.sh"
echo "spark日志级别配置"
cp "${installDir}/spark-${version}/conf/log4j.properties.template" "${installDir}/spark-${version}/conf/log4j.properties"
sed -i "s|^log4j.rootCategory=.*|log4j.rootCategory=WARN, console|" "${installDir}/spark-${version}/conf/log4j.properties"
echo "配置spark单机模式"
echo "export SPARK_MASTER_HOST=$(hostname) #设置主节点地址" >> "${installDir}/spark-${version}/conf/spark-env.sh"
echo 'export SPARK_WORKER_MEMORY=1g #设置节点内存大小' >> "${installDir}/spark-${version}/conf/spark-env.sh"
echo 'export SPARK_WORKER_CORES=1 #设置节点参与计算的核心数' >> "${installDir}/spark-${version}/conf/spark-env.sh"
echo 'export SPARK_WORKER_INSTANCES=1 #设置节点实例数' >> "${installDir}/spark-${version}/conf/spark-env.sh"
echo "export JAVA_HOME=$JAVA_HOME" >> "${installDir}/spark-${version}/conf/spark-env.sh"
echo "export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop" >> "${installDir}/spark-${version}/conf/spark-env.sh"
echo "设置spark节点"
echo "$(hostname)" > "${installDir}/spark-${version}/conf/slaves"
echo "删除spark安装包"
rm -rf /tmp/spark-"$version"-bin-hadoop2.7.tgz
echo "spark 安装完成!"
}
install_spark "$sprak_version" "$sprak_installDir"
2. 增加执行权限
chmod a+x /tmp/install_spark.sh
3. 执行/tmp/install_spark.sh
/tmp/install_spark.sh
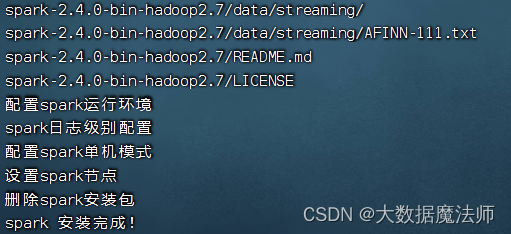
执行之后等待下载、安装、配置完成,如下图:
4. 加载环境变量
source ~/.bashrc
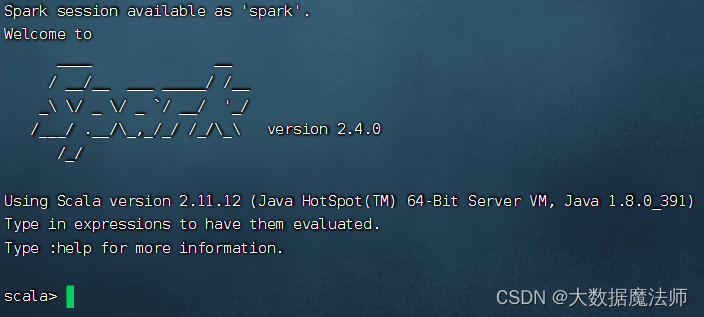
进入spark交互界面
spark-shell
如下图:
5. 启动/停止spark
启动spark
/opt/module/spark-2.4.0/sbin/start-all.sh
查看是否启动成功
jps | awk '$NF == "Master" || $NF == "Worker" { print $NF }'
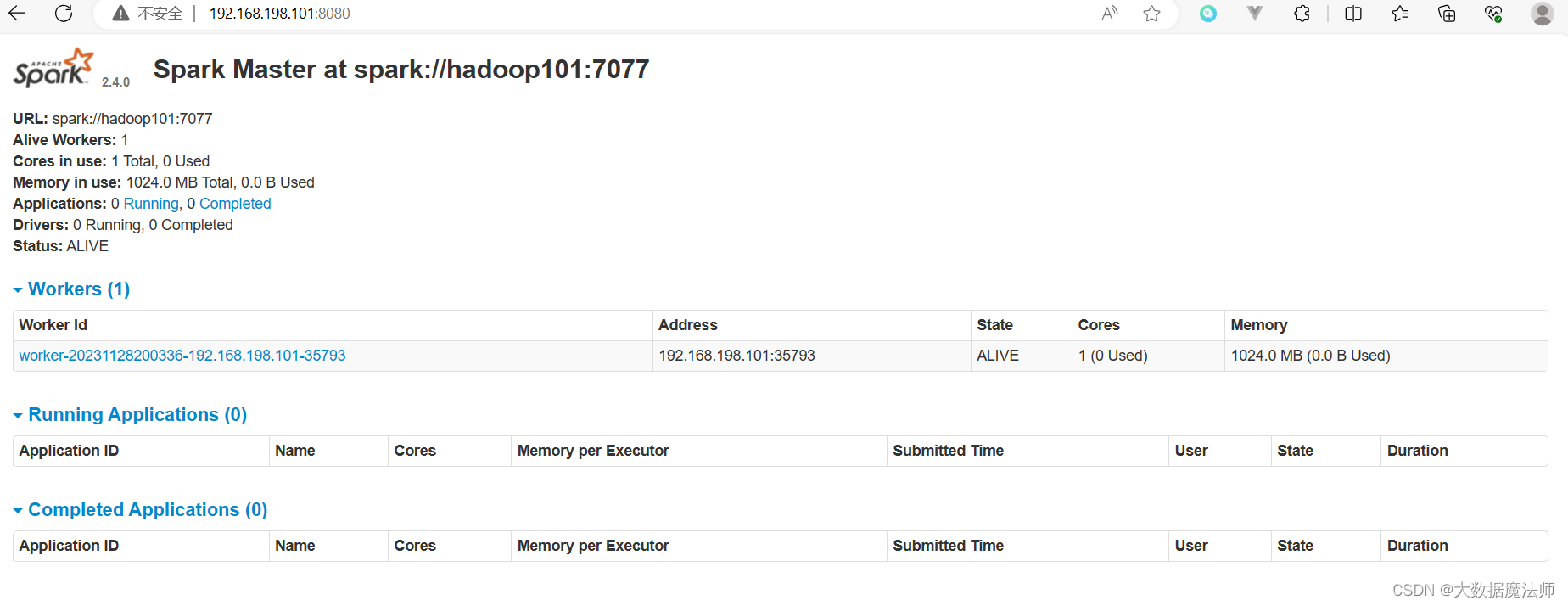
启动成功如下图:

浏览器访问sparkUI界面:http://192.168.145.103:8080/
如下图:
停止spark
/opt/module/spark-2.4.0/sbin/stop-all.sh
