阿里云实时数据仓库HologresFlink
1. 实时数仓Hologres特点
专注实时场景:数据实时写入、实时更新,写入即可见,与Flink原生集成,支持高吞吐、低延时、有模型的实时数仓开发,满足业务洞察实时性需求。
亚秒级交互式分析:支持海量数据亚秒级交互式分析,无需预计算,支持多维分析、即席分析、探索式分析、MaxCompute加速分析,满足所见即所得分析体验。
统一数据服务出口:支持多维分析、高性能点查、数据检索等多个场景,支持负载隔离,简化数据架构,统一数据访问接口,实践分析服务一体化(HSAP)。
开放生态:标准SQL协议,无缝对接主流BI和SQL开发框架,无需应用重写。支持数据湖场景,支持JSON等半结构化数据,OSS、DLF简易入仓。
2. 实时计算Flink服务
全托管Flink服务:开箱即用、开发远维全周期、计费灵活
丰富的企业级能力:流批一体的一站式开发运维平台、Flink CDC实时入湖入仓、动态CEP助力实时风控/营销、作业自动调优充分利用资源、智能冷断快速定位
性能强劲:内核引擎优化: CPU超秒数十万记录处理能力、Nexmark 测试性能技开源提升200%、状态存储后端优化
100%兼容开源:100%兼容Apache Flink、支持开源 Flink平滑迁移上云、无缝对接主流开源大教据生态
开放被集成能力强:自定义连按器、UXF能力扩展、Open API帮助用户集成自身系统、用户开发能力扩展与沉淀复用、用户自身系统集成
业界认可:中国信通院权威认证、中国唯一进入 Forrester 象限的实时流计算产品、金融实时数仓方案入围工信部信创典型目录
3. 数据仓库概念
数据仓库定义 ( Data Warehouse ):为企业所有决策制定过程,提供所有系统数据支持的战略集合。
传统的离线数仓无法实现当天数据的及时分析数据,所以需要开发实时数仓开填补空缺。
4. 阿里云技术框架
| 阿里云产品 | 简介 | 类比 |
| Flink实时计算平台 | 大数据计算框架 | Hadoop集群+Flink+调度器 |
| Hologres | 大数据存储框架 | Kafka+Redis+HBase+ClickHouse |
| DataHub | 数据流存储 | Kafka+元数据管理 |
| RDS | 关系型数据库 | MySql |
| DataV | 可视化数据展示工具 | Tableau、Echarts、Kibana |
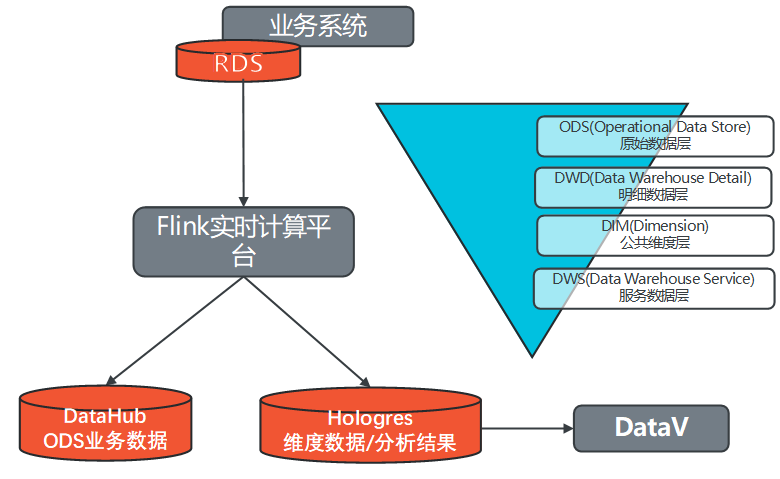
5. 系统数据流程设计
5. Hologres的购买和基础介绍




后来我总是找不到实例在哪。(我等了两个小时终于实例出来啦)
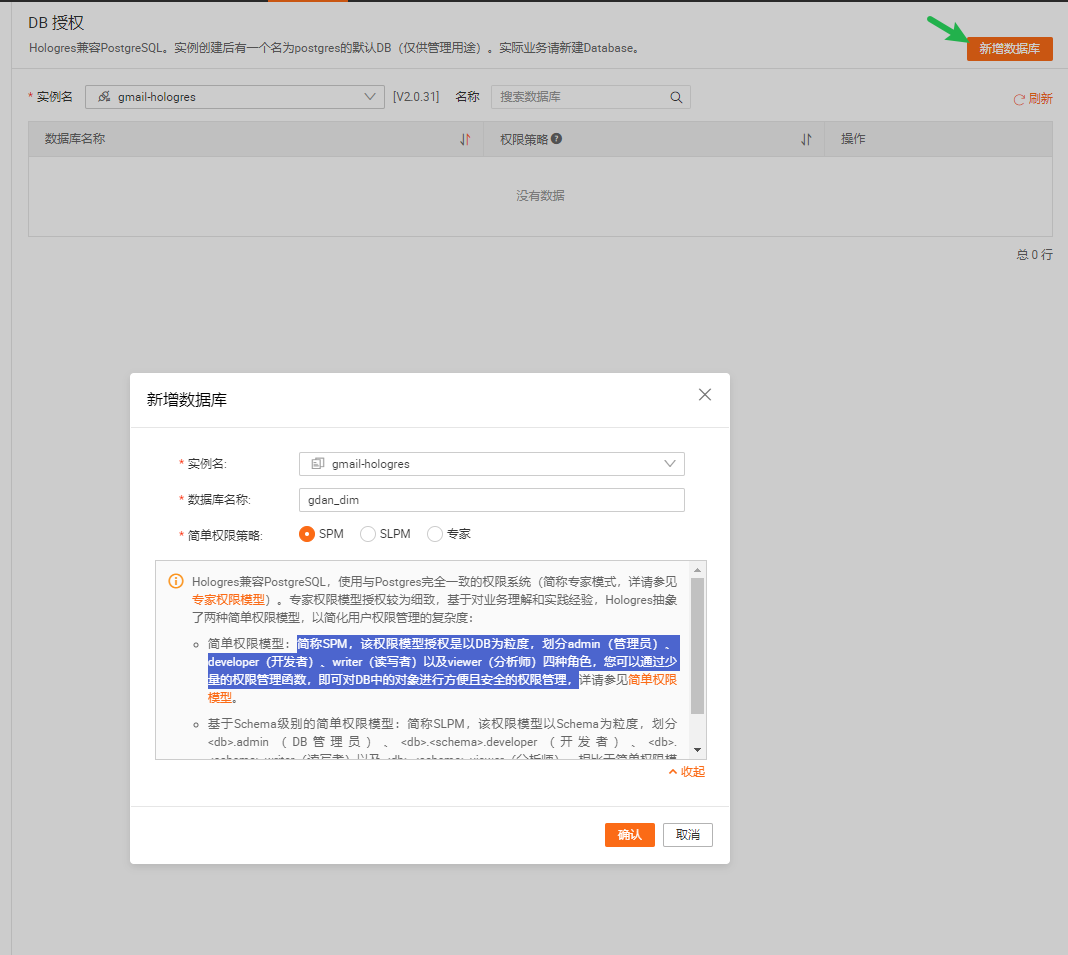
点击登录实例

点击连接实例
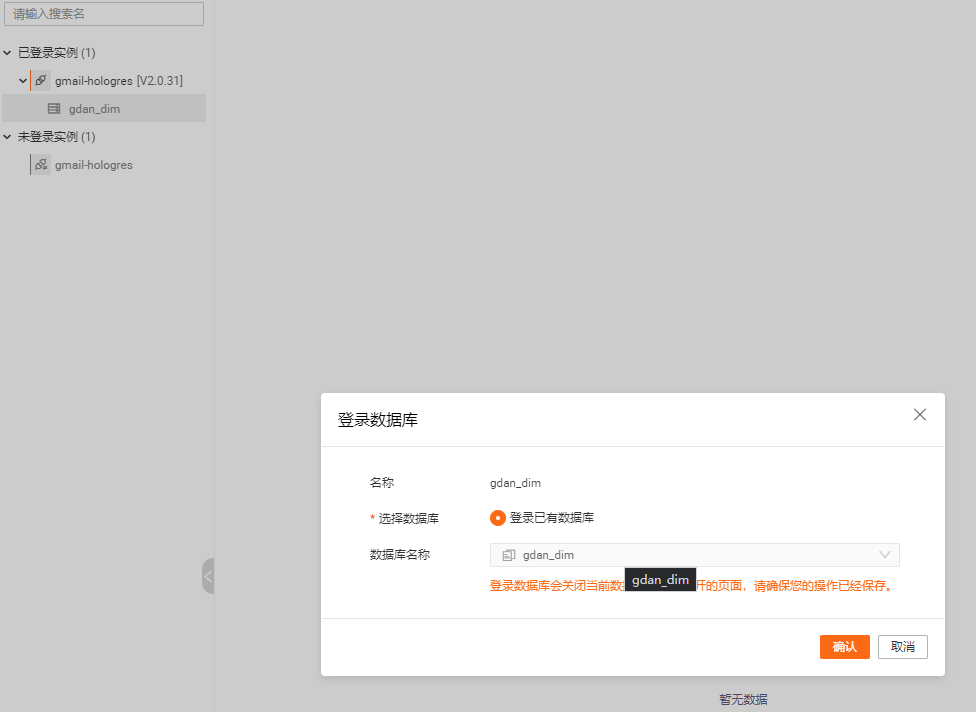
双击 登录库
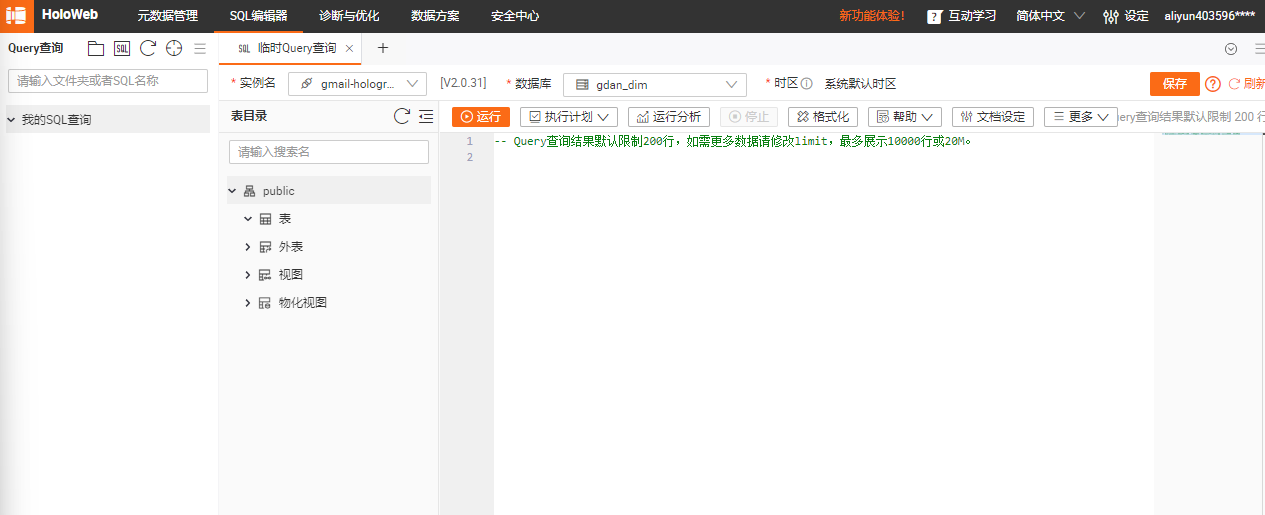
可以编辑SQL
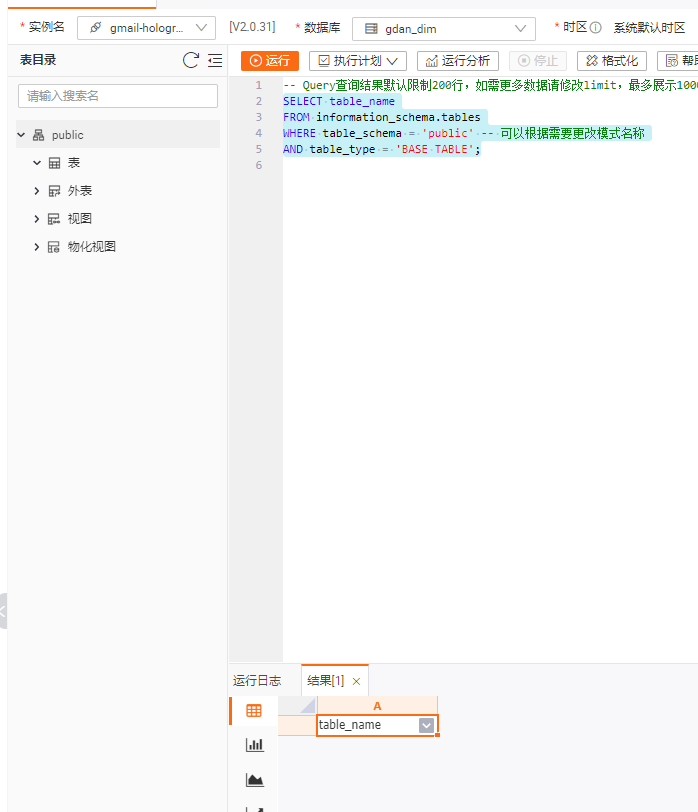
SELECT table_name
FROM information_schema.tables
WHERE table_schema = 'public' -- 可以根据需要更改模式名称
AND table_type = 'BASE TABLE';
6. Flink实时计算

开通之后点击立即试用


7. 数据总线Datahub
数据总线datahub是阿里云免费提供的服务,相当于大数据框架中的kafka,可以用作数据的缓存。
进入到datahub的主页面之后,点击项目管理,之后再点击新建项目。填写项目名称之后即可完成创建。


8. 业务表

一共7个表
9. 同步策略
数据同步策略的类型包括:全量同步(每天把完整的数据同步)、增量同步(有一条数据变化就同步过来)
实时数仓统一都要选择增量同步,细节在于维度表数据需要保持和业务数据库始终一致,同步修改和删除。而业务流程数据需要记录下每一次数据的变化。
10. RDS服务器购买
阿里云关系型数据库(Relational Database Service,简称RDS)是一种稳定可靠、可弹性伸缩的在线数据库服务。




使用的都是内网
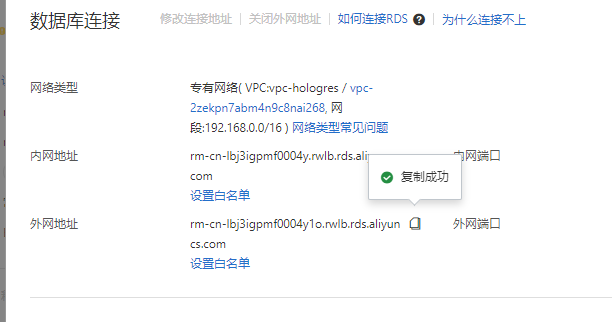

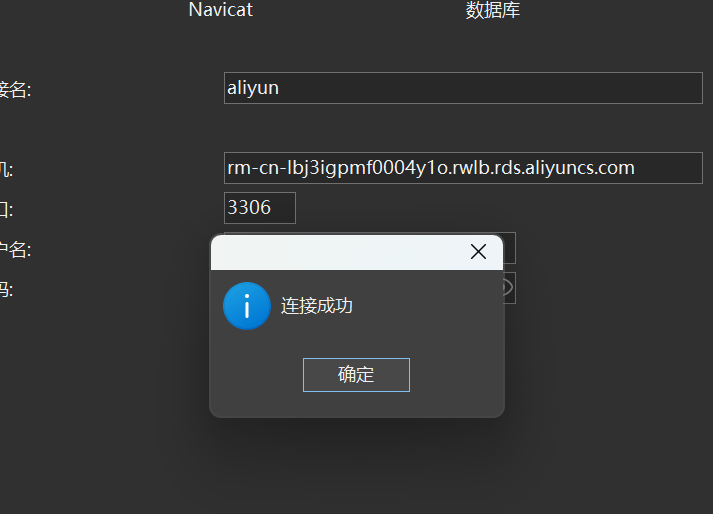

导入数据库

11. ODS数据同步
ODS层的数据同步需要将数据从业务表格监控数据的实时变化,将变化数据写入到DataHub中,同步业务表格RDS(MySQL)的变更数据有多种方法,较为简单的方法,可以直接使用阿里云的DataWorks数据同步功能,此处选择更加泛用的flinkCDC方法来实现。

12. FlinkCDC
CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件(datahub,类似kafka)中以供其他服务进行订阅及消费。
CDC主要分为基于查询和基于Binlog两种方式,我们主要了解一下这两种之间的区别:


基于批处理/基于流处理
Flink社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,
13. Flink Stream API完成数据同步
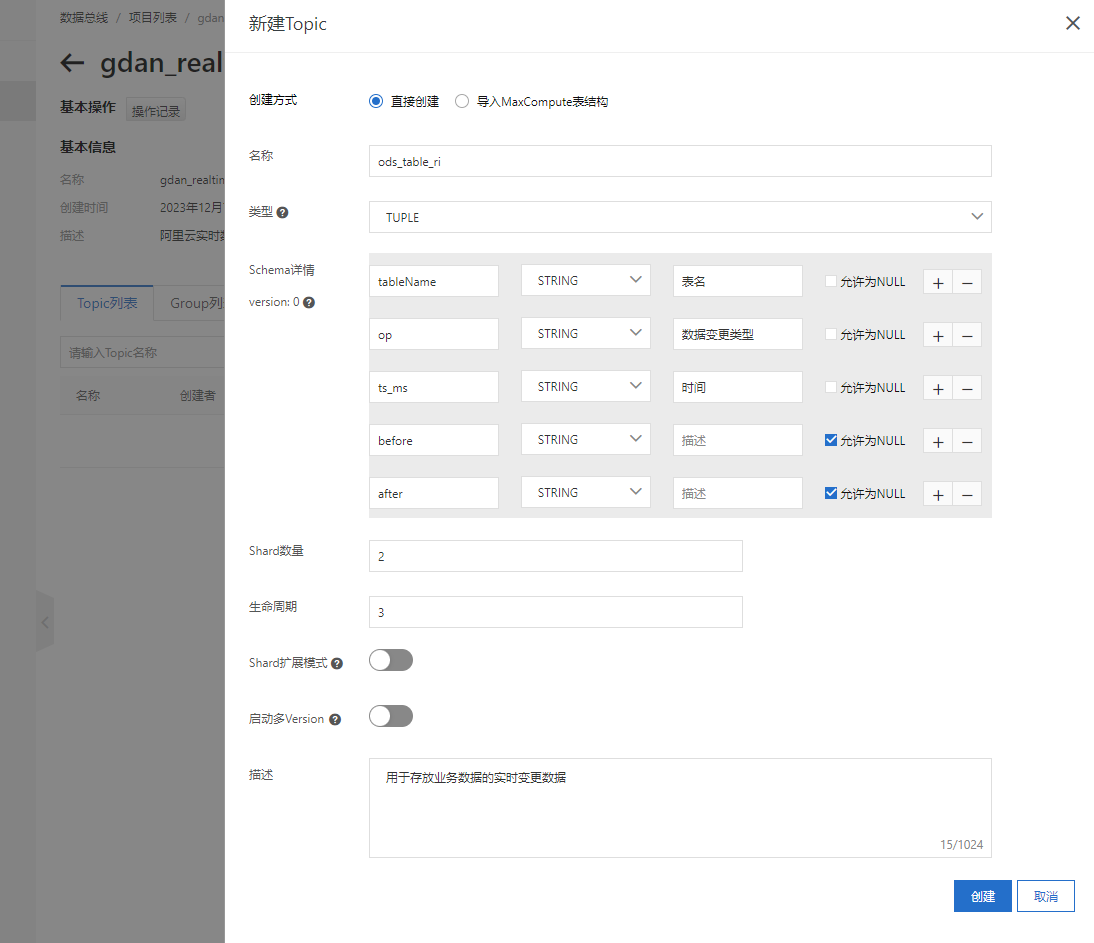
在数据总线DataHub中,先创建项目gmall_realtime,之后创建主题ods_table_ri用于接收数据,同时填写元数据信息。
13.1 创建IDEA项目
解决错误 “Plugin ‘maven-shade-plugin:3.1.1‘ not found“ 的方法详解
找到对应文件夹,更改成对应的版本号

解决方式是,删掉.idea这个文件夹,再导入一次项目

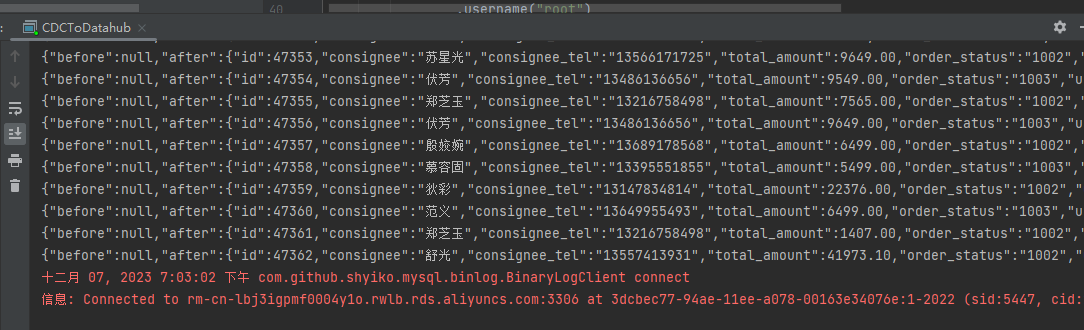
运行之后出现,需要把依赖添加进来

13.2 创建工具类
推荐使用阿里云官方提供的DataHubSink写出数据,可以直接添加DataHub的元数据对应。
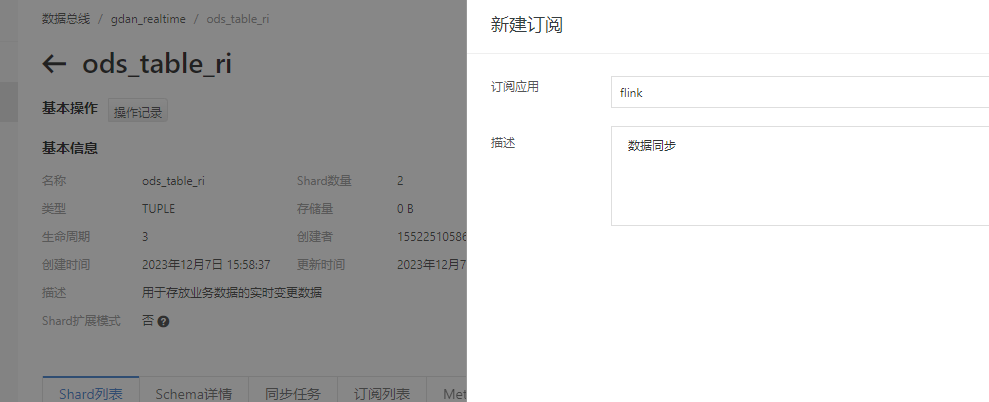

下面这些信息都在阿里的DataHub中找信息
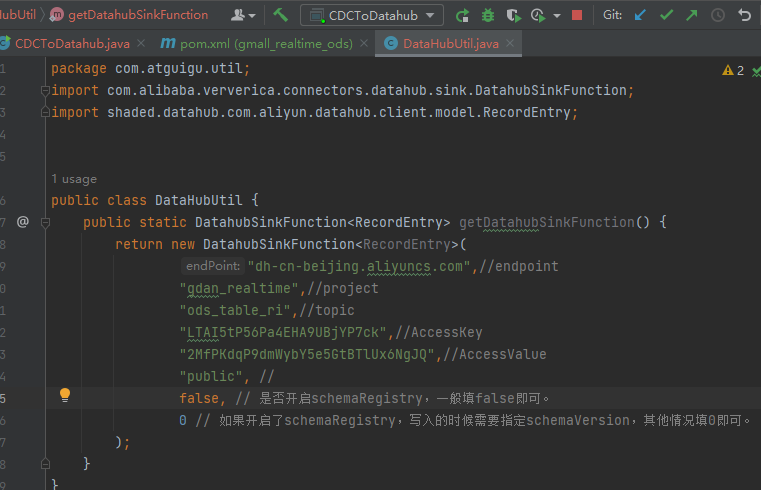
运行CDCToDataHub,就可以看到在官网上的结果。

13.3 打包上传
点击Maven的packeage功能。

在Flink平台部署jar包

测试是否能连通DataHub?