【Python】Python音乐网站数据+音频文件数据抓取(代码+报告)【独一无二】
👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【Python】Python音乐网站数据+音频文件数据抓取(代码+报告)【独一无二】
目录
- 【Python】Python音乐网站数据+音频文件数据抓取(代码+报告)【独一无二】
- 1. 页面分析
- 2. 关键技术
- 3. 部分代码
- 4. 运行截图
- 5. 总结
1. 页面分析
👇👇👇 关注公众号,回复 “音乐网站数据抓取” 获取源码👇👇👇
爬取页面是网易云音乐的飙升榜单页面,具体的URL是 https://music.xxx.com/xxx/xxx。这个页面包含了当前飙升榜上的音乐列表,每首歌曲都包括了歌曲名称和链接。爬取页面分析:代码使用了requests库来发送HTTP GET请求,获取网易云音乐飙升榜单页面的HTML内容。页面内容保存到了一个名为 ‘music.html’ 的本地HTML文件中,这样可以在之后的处理中使用。使用lxml库来解析HTML页面,将歌曲名称和链接提取出来。循环迭代处理每一首歌曲,提取歌曲名称和链接,并构建用于下载歌曲的URL。发送HTTP请求来下载每首歌曲,如果响应状态码为200,表示下载成功,将歌曲信息写入CSV文件中,并将音乐文件保存到本地以歌曲名称命名的文件中。如果响应状态码不为200,表示下载失败,会输出一条下载失败的消息。
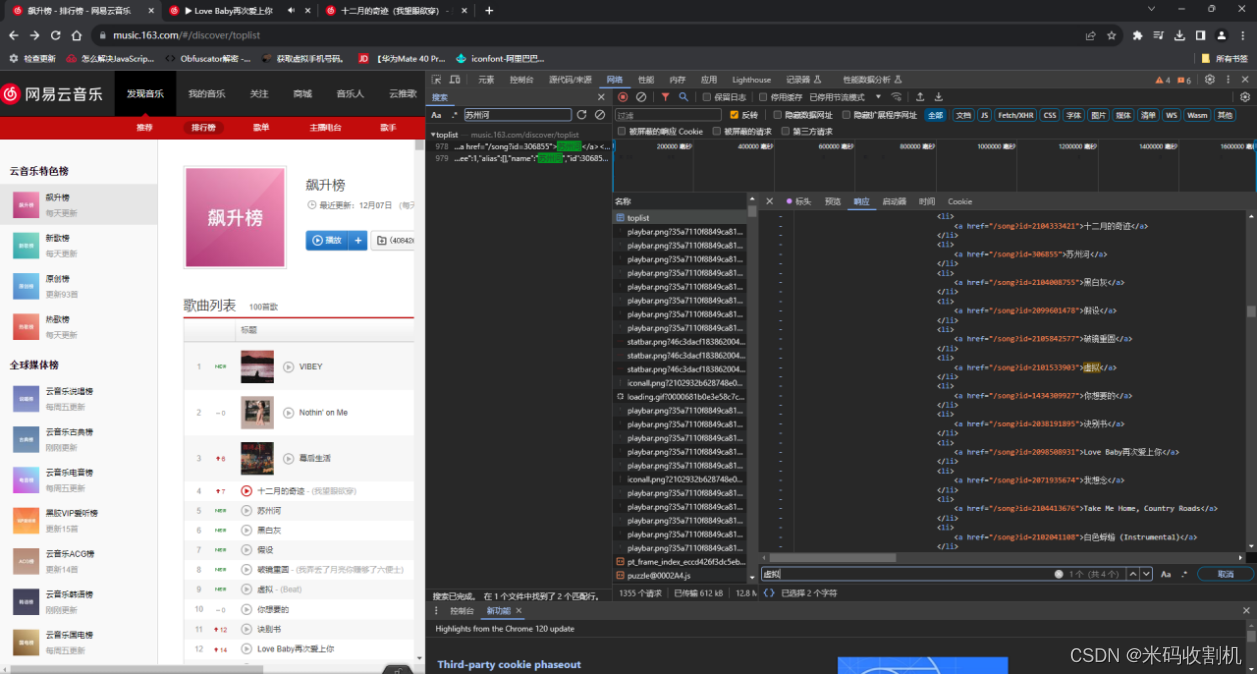
2. 关键技术
👇👇👇 关注公众号,回复 “音乐网站数据抓取” 获取源码👇👇👇
HTTP请求和响应:使用Python的requests库来发送HTTP GET请求,以获取网页的HTML内容。HTTP请求允许程序与网站交互,而HTTP响应包含网页内容,使其可供进一步处理。
HTML解析:使用lxml库来解析HTML文档。lxml是一个强大的库,用于解析和处理XML和HTML文档。XPath表达式用于定位和提取HTML页面中的特定元素,如歌曲名称和链接。
XPath表达式:代码中使用XPath表达式来定位和提取HTML页面中的数据。XPath是一种用于在XML和HTML文档中导航和选择元素的语言,它使得从HTML中提取所需信息变得更加便捷。
CSV文件操作:使用Python的内置csv库来创建和操作CSV文件。CSV文件用于存储爬取到的音乐信息,包括歌曲名称和下载链接。CSV文件是一种通用的数据存储格式,便于后续分析和处理。
3. 部分代码
url = 'https://music.xxx.com/xxxxx'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
with open('music.html', 'w', encoding='utf-8') as f:
f.write(response.text)
with open("music.html", 'r', encoding='utf-8') as f:
text = f.read()
txt = etree.HTML(text)
for i in range(1, xxx):
# ....略.....
mid = href.split('id=')[-1]
# ....略.....
4. 运行截图
👇👇👇 关注公众号,回复 “音乐网站数据抓取” 获取源码👇👇👇
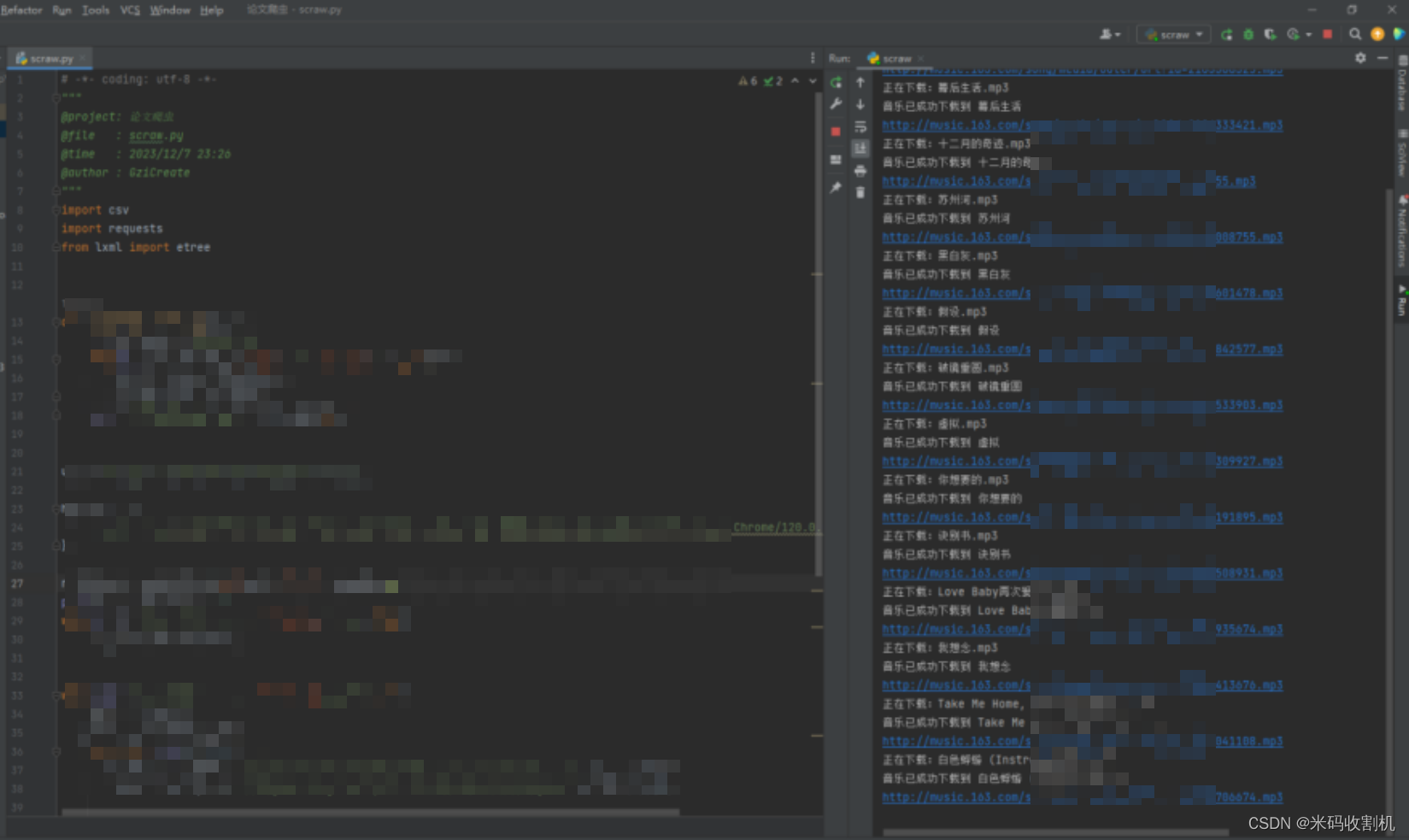
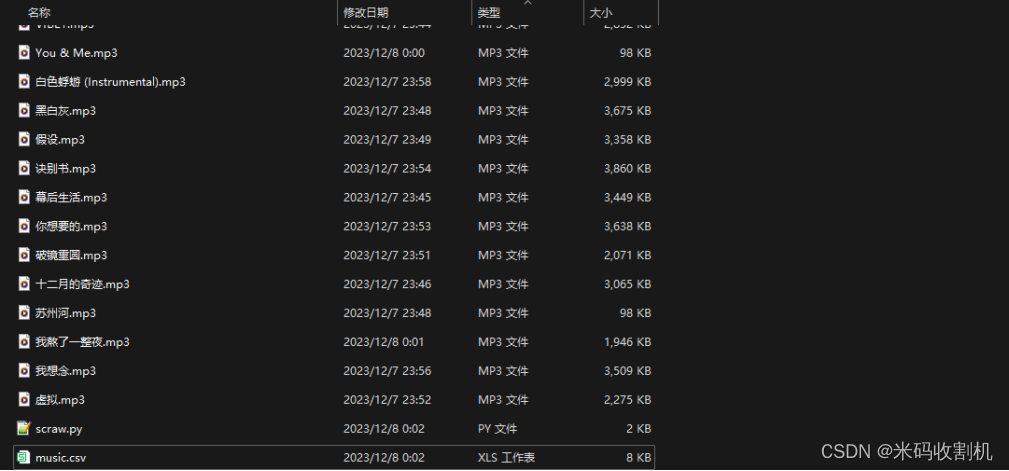
5. 总结
心得与体会:
在编写和执行这段代码的过程中,我学到了许多关于网络爬虫和数据采集的重要概念和技术。这个项目不仅让我更深入地理解了HTTP请求、HTML解析和文件操作,还让我明白了合法性和道德性在数据采集中的重要性。
首先,我体会到了HTTP请求和响应的基本原理。通过使用Python的requests库,我能够轻松地发送HTTP请求并获取网页内容。了解如何处理HTTP响应状态码是解决下载问题的关键之一,这帮助我更好地理解了网络通信过程。
不足之处:
尽管这个项目带来了许多宝贵的经验,但我也意识到了一些不足之处和改进的空间。
首先,代码的可维护性有待提高。在代码中硬编码了XPath表达式和URL,这使得如果网站结构发生变化,代码就需要进行修改。更好的做法是将这些参数和选择器提取为变量或配置文件,以便于维护和更新。
👇👇👇 关注公众号,回复 “音乐网站数据抓取” 获取源码👇👇👇