使用 PyTorch 进行 K 折交叉验证

一、说明
中号机器学习模型在训练后必须使用测试集进行评估。我们这样做是为了确保模型不会过度拟合,并确保它们适用于现实生活中的数据集,与训练集相比,现实数据集的分布可能略有偏差。
但为了使您的模型真正稳健,仅仅通过训练/测试分割进行评估可能还不够。
例如,假设您有一个由两个类的样本组成的数据集。数据集前 80% 中的大多数样本属于 A 类,而其他 20% 中的大多数样本属于 B 类。如果您采用简单的 80/20 保留分割,那么您的数据集将具有截然不同的分布——评估可能会得出错误的结论。
这是我们想要避免的事情。因此,在本文中,我们将了解另一种可以应用的技术——K 折交叉验证。通过跨多个折叠生成训练/测试分割,您可以使用不同的分割执行多个训练和测试会话。您还将了解如何将 K 折交叉验证与 PyTorch 结合使用,PyTorch 是当今领先的神经网络库之一。
读完这篇文章后,您将...
- 了解为什么 K 折交叉验证可以提高您对模型评估结果的信心。
- 了解 K 折交叉验证的工作原理。
- 了解如何使用 PyTorch 实现 K 折交叉验证
二、什么是 K 折交叉验证?
假设您的目标是构建一个能够正确分类输入图像的分类器 - 如下例所示。您输入代表手写数字的图像,输出预计为 5。
根据可选择的模型类型,构建此类分类器的方法有多种。但哪个最好呢?您必须评估每个模型才能了解其效果如何。

三、为什么使用训练/测试分割进行模型评估?
模型评估发生在机器学习模型训练之后。它通过从称为测试集的数据集中提供样本来确保模型也可以处理真实世界的数据,其中包含模型以前从未见过的样本。
通过将后续预测与这些样本也可用的真实标签进行比较,我们可以看到模型在此数据集上的表现如何。因此,如果我们在模型评估期间使用它,我们还可以看到它对现实世界数据的表现如何。
然而,在评估我们的模型时我们必须谨慎。我们不能简单地使用训练模型的数据,以避免成为一个给自己作业评分的学生。
因为这就是您使用训练数据进行评估时会发生的情况:随着模型已经学会捕获与特定数据集相关的模式,如果这些模式是虚假的,因此不存在于现实世界的数据中,则模型可能会表现不佳。特别是对于高方差模型,这可能会成为一个问题。
相反,我们使用该测试集来评估模型,该测试集已被选择并包含训练集中不存在的样本。但如何构建这个测试集是另一个问题。有多种方法可以做到这一点。我们先来看看一个简单的策略。然后我们就会明白为什么我们可以应用 K 折交叉验证。
四、简单的坚持分裂:一种幼稚的策略
这是一种简单的方法,也称为简单的保留分割:
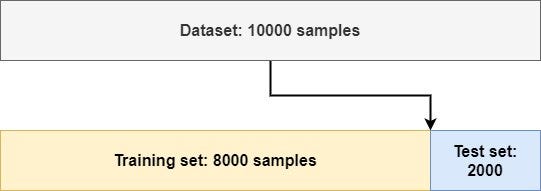
使用这种技术,您只需取出原始数据集的一部分,将其分开,并将其视为测试数据。传统上,这种分割以 80/20 的方式进行,其中 80% 的数据用于训练模型,20% 用于评估模型。
这是一种幼稚的方法,有几个原因:您必须始终牢记这些边缘情况(Chollet,2017):
- 数据代表性:所有数据集本质上都是样本,必须尽可能地代表总体中的模式。当您从样本(即从完整数据集)生成样本时,这一点变得尤其重要。例如,如果数据集的第一部分包含冰淇淋图片,而后一部分仅代表浓缩咖啡,则当您生成如上所示的分割时,肯定会遇到麻烦。随机洗牌可以帮助您解决这些问题。
- 时间之箭:如果您有时间序列数据集,您的数据集可能是按时间顺序排序的。如果你随机洗牌,然后执行简单的保留验证,你就可以有效地“根据过去预测未来”(Chollet,2017)。这种时间泄漏不会有利于模型性能。
- 数据冗余:如果某些样本出现多次,则带有随机改组的简单保留分割可能会在训练和测试数据集之间引入冗余。也就是说,相同的样本属于两个数据集。这也是有问题的,因为用于训练的数据会隐式泄漏到用于测试的数据集中。
这就是为什么更稳健地验证模型通常是更好的主意。让我们看一下 K 折交叉验证来实现这一点。
五、K 折交叉验证简介
如果我们可以尝试这种训练/测试拆分的多种变体会怎么样?然后,我们将拥有一个评估更加稳健的模型。
这正是K 折交叉验证的意义所在。
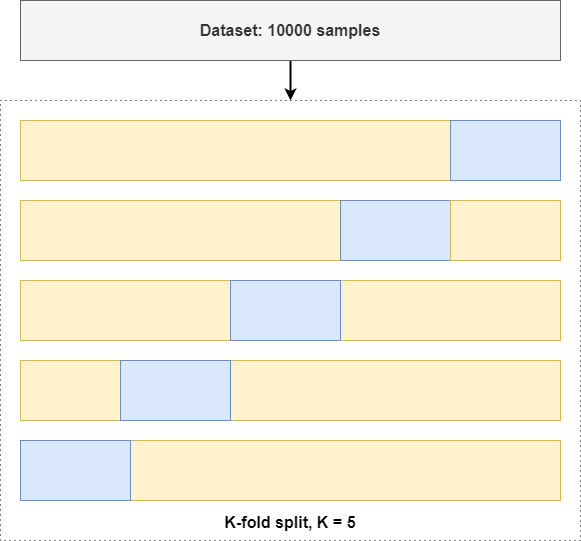
在 K 折交叉验证中,您将数字k设置为任何大于1 的整数值,并且将生成k个分割。每个分割都有属于测试数据集的1/k样本,而其余数据可用于训练目的。
由于在每次分割中,训练数据的不同部分将用于验证目的,因此您可以多次有效地训练和评估模型,从而使您能够比简单的保留分割更有信心地判断它是否有效。
现在让我们看看如何使用 PyTorch 实现 K 折交叉验证!
六、使用 PyTorch 实施 K 折交叉验证
现在您已经了解了 K 折交叉验证的工作原理,让我们看看如何将其应用于 PyTorch。将 K-fold CV 与 PyTorch 结合使用涉及以下步骤:
- 确保您的依赖项是最新的。
- 说明您的模型导入。
- 定义
nn.Module神经网络的类别以及权重重置函数。 - 在运行时代码中添加准备步骤。
- 加载您的数据集。
- 定义 K 折交叉验证器并生成折叠。
- 迭代每个折叠,训练和评估另一个模型实例。
- 对所有折叠进行平均以获得最终性能。
七、运行代码需要什么
运行此示例需要您安装以下依赖项:
- Python,运行一切。确保安装 3.12+,尽管它也可以运行稍旧的版本。
- PyTorch,这是您用来训练模型的深度学习库。
- Scikit-learn,用于生成折叠。
让我们打开一个代码编辑器并创建一个名为kfold.py. 显然,您可能还想在 Jupyter Notebook 中运行所有内容。这取决于你。
7.1 模型人口
我们要做的第一件事是指定模型导入。我们导入这些 Python 模块:
- 对于文件输入/输出,我们使用
os.
2. 所有 PyTorch 功能均导入为torch. 我们还有一些子导入:
- 神经网络功能导入为
nn. DataLoader我们导入的数据torch.utils.data用于将数据传递到神经网络。- 将
ConcatDataset用于连接 MNIST 数据集的训练和测试部分,我们将用它来训练模型。K-fold CV 意味着您自己生成分割,因此您不希望 PyTorch 为您执行此操作 - 因为您实际上会丢失数据。
3. 我们还导入与计算机视觉相关的特定功能 - 使用torchvision. 首先,我们MNIST从 导入数据集torchvision.datasets。我们还transforms从 Torch Vision 导入,这使我们能够稍后将数据转换为 Tensor 格式。
4. 最后,我们导入KFoldfromsklearn.model_selection以允许我们执行 K 折交叉验证。
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader, ConcatDataset
from torchvision import transforms
from sklearn.model_selection import KFold7.2 模型类
是时候开始一些真正的工作了!
让我们定义一个简单的卷积神经网络,即 a SimpleConvNet,它利用nn.Module基类 - 从而有效地实现 PyTorch 神经网络。
__init__我们可以通过指定构造函数定义和前向传递来实现它,如下所示。在__init__定义中,我们将神经网络指定为 PyTorch 层的顺序堆栈。您可以看到我们使用一个Conv2d带有 ReLU 激活的卷积层 ( ) 和一些Linear负责生成预测的层。由于 MNIST 数据集的简单性,这应该足够了。我们将堆栈存储在 中self.layers,我们在前向传递中使用它,如forward定义中所定义的。在这里,我们只是将可用的数据传递x到各层。
class SimpleConvNet(nn.Module):
'''
Simple Convolutional Neural Network
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=3),
nn.ReLU(),
nn.Flatten(),
nn.Linear(26 * 26 * 10, 50),
nn.ReLU(),
nn.Linear(50, 20),
nn.ReLU(),
nn.Linear(20, 10)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)在此之前class,我们还将添加一个def名为reset_weights. 在折叠过程中,它将用于重置模型的参数。这样,我们确保模型使用(伪)随机初始化的权重进行训练,避免权重泄漏。
def reset_weights(m):
'''
Try resetting model weights to avoid
weight leakage.
'''
for layer in m.children():
if hasattr(layer, 'reset_parameters'):
print(f'Reset trainable parameters of layer = {layer}')
layer.reset_parameters()7.3 运行时代码
现在我们已经定义了模型类,是时候编写一些运行时代码了。运行时代码是指您将编写在运行 Python 文件或 Jupyter Notebook 时实际运行的代码。您之前定义的类指定了一个骨架,您必须首先初始化它才能运行它。我们接下来就这样做。更具体地说,我们的运行时代码涵盖以下几个方面:
- 准备步骤,我们执行一些(毫不奇怪)准备步骤来运行模型。
- 加载数据集;准确地说,是 MNIST。
- 定义 K 折交叉验证器来生成折叠。
- 然后,生成我们实际上可以用于训练模型的分割,我们也这样做——每次折叠一次。
- 在对每个折叠进行训练后,我们评估该折叠的性能。
- 最后,我们对模型进行跨折叠的性能评估。
其实,就是这么简单!:)
7.4 准备步骤
下面,我们定义了一些在开始跨折叠集的训练过程之前执行的准备步骤。您可以看到我们运行了名称中的所有内容__main__,这意味着该代码仅在我们执行 Python 文件时运行。在这一部分中,我们做了以下几件事:
- 我们设置配置选项。我们将生成 5 折(通过设置 (k = 5),我们训练 1 epoch(通常,这个值要高得多,但这里我们只想说明 K 折 CV 的工作),我们将损失设置
nn.CrossEntropyLoss为功能。 - 我们定义一个字典来存储每次折叠的结果。
- 我们设置了一个固定的随机数种子,这意味着所有伪随机数初始化器都将使用相同的初始化令牌进行初始化。
if __name__ == '__main__':
# Configuration options
k_folds = 5
num_epochs = 1
loss_function = nn.CrossEntropyLoss()
# For fold results
results = {}
# Set fixed random number seed
torch.manual_seed(42)7.5 加载 MNIST 数据集
然后我们加载 MNIST 数据集。如果您习惯使用 PyTorch 数据集,您可能已经熟悉此代码。然而,第三行可能仍然有点不清楚——但实际上很容易理解这里发生的事情。
我们简单地将MNIST 数据集的train=True和train=False部分合并在一起,该数据集已经被 PyTorch 的torchvision.
我们不希望这样——回想一下,K 折交叉验证生成跨 k 折的训练/测试分割,其中 k-1 部分用于训练模型,1 部分用于模型评估。
为了解决这个问题,我们只需加载这两个部分,然后将它们连接到一个ConcatDataset对象中。不用担心数据的混洗——您将看到接下来会处理这个问题。
# Prepare MNIST dataset by concatenating Train/Test part; we split later.
dataset_train_part = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=True)
dataset_test_part = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=False)
dataset = ConcatDataset([dataset_train_part, dataset_test_part])7.6 定义 K 折交叉验证器
因为接下来,当我们初始化 K 折交叉验证器时,我们确实定义了洗牌。在这里,我们设置shuffle=True,这意味着在数据被分割成批次之前发生洗牌。k_folds表示折叠次数,正如您所期望的那样。
# Define the K-fold Cross Validator
kfold = KFold(n_splits=k_folds, shuffle=True)
# Start print
print('--------------------------------')7.7 生成分割并训练折叠模式
我们现在可以生成分割并训练我们的模型。您可以通过定义一个循环来迭代分割,指定该特定折叠的训练和测试fold样本的标识符列表来实现此目的。这些可用于执行实际的训练过程。
在 for 循环中,我们首先执行一条print语句,指示当前折叠。然后您执行训练过程。这涉及以下步骤:
- 从
train_ids或test_ids中采样实际元素SubsetRandomSampler。采样器可用于DataLoader仅使用特定样本;在这种情况下基于标识符,因为SubsetRandomSampler从列表中随机采样元素,没有替换。换句话说,您创建两个子采样器,它们遵循循环中指定的分割for。 - 使用数据加载器,您实际上将从完整的
dataset. 您可以使用适合内存的任何批处理大小,但批处理大小 10 几乎适用于所有情况。 - 为该特定折叠准备好数据集后,您可以通过初始化类来初始化神经网络 - 使用
SimpleConvNet(). - 然后,当神经网络初始化时,您可以初始化此特定训练会话的优化器 - 在本例中,我们使用 Adam,并具有
1e-4学习率。 - 在 PyTorch 中,您必须定义自己的训练循环。它相对简单:迭代 epoch 的数量;在一个时期内,在小批量上;每个小批量,您执行前向传递、后向传递和后续优化。这就是这里正在发生的事情。
# K-fold Cross Validation model evaluation
for fold, (train_ids, test_ids) in enumerate(kfold.split(dataset)):
# Print
print(f'FOLD {fold}')
print('--------------------------------')
# Sample elements randomly from a given list of ids, no replacement.
train_subsampler = torch.utils.data.SubsetRandomSampler(train_ids)
test_subsampler = torch.utils.data.SubsetRandomSampler(test_ids)
# Define data loaders for training and testing data in this fold
trainloader = torch.utils.data.DataLoader(
dataset,
batch_size=10, sampler=train_subsampler)
testloader = torch.utils.data.DataLoader(
dataset,
batch_size=10, sampler=test_subsampler)
# Init the neural network
network = SimpleConvNet()
# Initialize optimizer
optimizer = torch.optim.Adam(network.parameters(), lr=1e-4)
# Run the training loop for defined number of epochs
for epoch in range(0, num_epochs):
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = network(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished. Saving trained model.')八、折叠评价
在特定折叠内训练模型后,您还必须对其进行评估。这就是我们接下来要做的。首先,我们保存模型 - 以便以后您想重复使用它时可以将其用于生成产品。然后,我们执行模型评估活动 - 迭代并testloader为折叠分割的测试批次/测试部分中的所有样本生成预测。我们在评估后计算准确性,将print其显示在屏幕上,并将其添加到results该特定折叠的字典中。
# Print about testing
print('Starting testing')
# Saving the model
save_path = f'./model-fold-{fold}.pth'
torch.save(network.state_dict(), save_path)
# Evaluation for this fold
correct, total = 0, 0
with torch.no_grad():
# Iterate over the test data and generate predictions
for i, data in enumerate(testloader, 0):
# Get inputs
inputs, targets = data
# Generate outputs
outputs = network(inputs)
# Set total and correct
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
# Print accuracy
print('Accuracy for fold %d: %d %%' % (fold, 100.0 * correct / total))
print('--------------------------------')
results[fold] = 100.0 * (correct / total)九、模型评估
最后,一旦所有折叠都通过,我们就得到了results每个折叠的 。现在,是时候执行完整的模型评估了——我们可以更稳健地进行评估,因为我们拥有来自所有折叠的信息。以下是如何显示每次折叠的结果,然后在屏幕上打印平均值。
它允许你做两件事
- 查看您的模型是否在所有折叠上都表现良好;如果每次折叠的精度偏差不是太大,则确实如此。
- 如果确实如此,您就知道在哪个折叠中,并且可以仔细查看数据以了解那里发生了什么。
# Print fold results
print(f'K-FOLD CROSS VALIDATION RESULTS FOR {k_folds} FOLDS')
print('--------------------------------')
sum = 0.0
for key, value in results.items():
print(f'Fold {key}: {value} %')
sum += value
print(f'Average: {sum/len(results.items())} %')十、完整代码
您可能对简单地运行代码感兴趣,而不是阅读上面的解释。由于本文有点长,您可以在我的 Github 存储库中找到完整的代码。
运行代码会得到以下 5 次折叠的结果,每次折叠一个 epoch。
--------------------------------
FOLD 0
--------------------------------
Starting epoch 1
Loss after mini-batch 500: 1.875
Loss after mini-batch 1000: 0.810
Loss after mini-batch 1500: 0.545
Loss after mini-batch 2000: 0.450
Loss after mini-batch 2500: 0.415
Loss after mini-batch 3000: 0.363
Loss after mini-batch 3500: 0.342
Loss after mini-batch 4000: 0.373
Loss after mini-batch 4500: 0.331
Loss after mini-batch 5000: 0.295
Loss after mini-batch 5500: 0.298
Training process has finished. Saving trained model.
Starting testing
Accuracy for fold 0: 91 %
--------------------------------
FOLD 1
--------------------------------
Starting epoch 1
Loss after mini-batch 500: 1.782
Loss after mini-batch 1000: 0.727
Loss after mini-batch 1500: 0.494
Loss after mini-batch 2000: 0.419
Loss after mini-batch 2500: 0.386
Loss after mini-batch 3000: 0.367
Loss after mini-batch 3500: 0.352
Loss after mini-batch 4000: 0.329
Loss after mini-batch 4500: 0.307
Loss after mini-batch 5000: 0.297
Loss after mini-batch 5500: 0.289
Training process has finished. Saving trained model.
Starting testing
Accuracy for fold 1: 91 %
--------------------------------
FOLD 2
--------------------------------
Starting epoch 1
Loss after mini-batch 500: 1.735
Loss after mini-batch 1000: 0.723
Loss after mini-batch 1500: 0.501
Loss after mini-batch 2000: 0.412
Loss after mini-batch 2500: 0.364
Loss after mini-batch 3000: 0.366
Loss after mini-batch 3500: 0.332
Loss after mini-batch 4000: 0.319
Loss after mini-batch 4500: 0.322
Loss after mini-batch 5000: 0.292
Loss after mini-batch 5500: 0.293
Training process has finished. Saving trained model.
Starting testing
Accuracy for fold 2: 91 %
--------------------------------
FOLD 3
--------------------------------
Starting epoch 1
Loss after mini-batch 500: 1.931
Loss after mini-batch 1000: 1.048
Loss after mini-batch 1500: 0.638
Loss after mini-batch 2000: 0.475
Loss after mini-batch 2500: 0.431
Loss after mini-batch 3000: 0.394
Loss after mini-batch 3500: 0.390
Loss after mini-batch 4000: 0.373
Loss after mini-batch 4500: 0.383
Loss after mini-batch 5000: 0.349
Loss after mini-batch 5500: 0.350
Training process has finished. Saving trained model.
Starting testing
Accuracy for fold 3: 90 %
--------------------------------
FOLD 4
--------------------------------
Starting epoch 1
Loss after mini-batch 500: 2.003
Loss after mini-batch 1000: 0.969
Loss after mini-batch 1500: 0.556
Loss after mini-batch 2000: 0.456
Loss after mini-batch 2500: 0.423
Loss after mini-batch 3000: 0.372
Loss after mini-batch 3500: 0.362
Loss after mini-batch 4000: 0.332
Loss after mini-batch 4500: 0.316
Loss after mini-batch 5000: 0.327
Loss after mini-batch 5500: 0.304
Training process has finished. Saving trained model.
Starting testing
Accuracy for fold 4: 90 %
--------------------------------
K-FOLD CROSS VALIDATION RESULTS FOR 5 FOLDS
--------------------------------
Fold 0: 91.87857142857143 %
Fold 1: 91.75 %
Fold 2: 91.85 %
Fold 3: 90.35714285714286 %
Fold 4: 90.82142857142857 %
Average: 91.33142857142857 %事实上,这是 MNIST 数据集,我们仅通过有限的迭代就获得了很好的结果 - 但这是我们所期望的。
然而,我们还看到,各方面的性能相对相同,因此我们没有看到任何奇怪的异常值,这些异常值会影响我们的模型评估工作。
这确保了数据在各个分割中的分布相对相等,并且如果它具有相对相似的分布,则它可能适用于现实世界的数据。
一般来说,我现在经常做的是使用完整的数据集重新训练模型,而不对保留分割(或非常小的分割 - 例如 5%)进行评估。我们已经看到它具有概括性,并且是跨领域的。我们现在可以使用手头的所有数据来进一步提高性能。
十一、概括
在本教程中,我们研究了将 K 折交叉验证与 PyTorch 框架应用于深度学习。我们看到 K 折交叉验证使用数据集生成k 种称为折叠的不同情况,其中数据分为k-1 个训练批次和每个折叠 1 个测试批次。K 折交叉验证可用于更彻底地评估您的 PyTorch 模型,让您更加确信性能并未因数据集中的奇怪异常值而受到影响。
除了理论知识之外,我们还提供了一个 PyTorch 示例,展示了如何将 K 折交叉验证与框架结合 Scikit-learn 的KFold功能应用。我希望你们中的一些人从中学到了一些东西。如有任何意见、问题或建议,我们非常欢迎。感谢您的阅读!
参考
乔莱,F.(2017)。使用 Python 进行深度学习。纽约州纽约:曼宁出版社。
PyTorch 闪电。(2021 年 1 月 12 日)。Lightning AI
火炬。(nd)。https://pytorch.org