数据分析基础之《pandas(8)—综合案例》
一、需求
1、现在我们有一组从2006年到2016年1000部最流行的电影数据
数据来源:https://www.kaggle.com/damianpanek/sunday-eda/data
2、问题1
想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
3、问题2
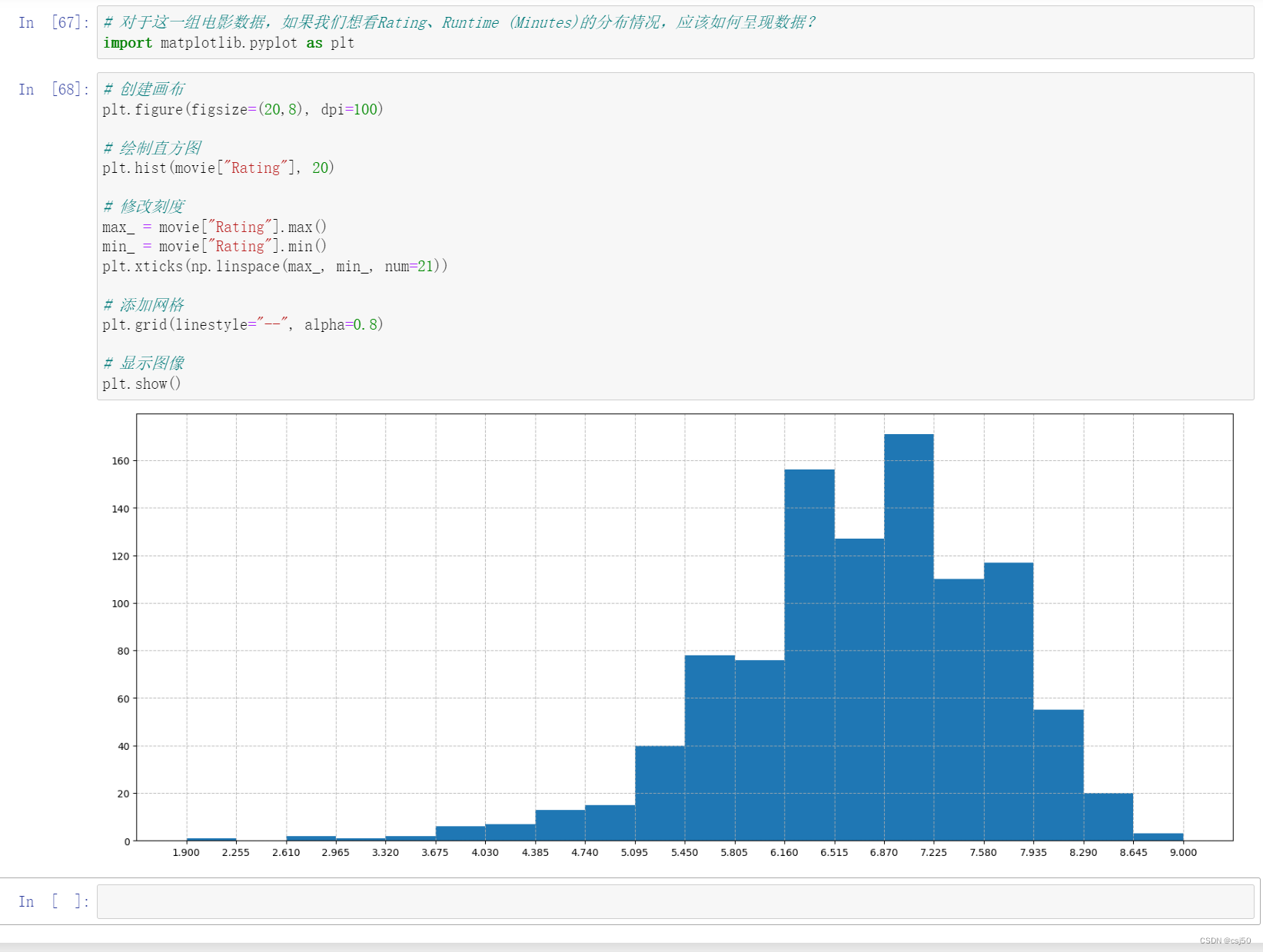
对于这一组电影数据,如果我们想看Rating、Runtime (Minutes)的分布情况,应该如何呈现数据?
4、问题3
对于这一组电影数据,如果我们希望统计电影分类genre的情况,应该如何处理数据?
二、实现
1、问题1
# 综合案例
movie= pd.read_csv("./IMDB-Movie-Data.csv")
movie
# 想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
# 评分的平均分
movie["Rating"].mean()
# 导演的人数信息
np.unique(movie["Director"]).size
2、问题2
# 对于这一组电影数据,如果我们想看Rating、Runtime (Minutes)的分布情况,应该如何呈现数据?
import matplotlib.pyplot as plt
# 创建画布
plt.figure(figsize=(20,8), dpi=100)
# 绘制直方图
plt.hist(movie["Rating"], 20)
# 修改刻度
max_ = movie["Rating"].max()
min_ = movie["Rating"].min()
plt.xticks(np.linspace(max_, min_, num=21))
# 添加网格
plt.grid(linestyle="--", alpha=0.8)
# 显示图像
plt.show()