点云目标检测
3D点云特点
云特性 :
无序性
三维空间中的点云不会像图像那样,规规矩矩的在一个个的像素点排好队,点云并没有顺序,这给处理上带来极大的困难。一个物体如果使用N个点云表示,那么它的排列方式具有N!种,但是表示的却是同一个物体,这是不可想象的处理难度。因而,点云的处理需要实现置换不变性。

点云特性 :
稀疏性
不同于图像,三维点云在表示物体时,只有物体表面有点云数据,如果实在实际的场景下,往往只有面向雷达的一面才会有数据产生。而且限于雷达的工作原理,远处物体的点云数据更加稀疏。因而,在点云上直接进行三维卷积需要很大的计算量,而其中很大一部分资源都是在处理空数据。在KITTI数据集中,如果把原始的激光雷达点云投影到对应的彩色图像上,大概只有3%的像素才有对应的雷达点。这种极强的稀疏性让基于点云的高层语义感知变得尤其困难。非结构化
点云是分布在空间中的XYZ点。没有结构化的网格来帮助CNN滤波器

3D点云目标检测
3D检测用于描述检测环境中的三维物体,获取物体在三维空间中的位置和类别Pitch信息,给出物体的Bounding Box。主要基于点云、双目、单目和多模态数据等方式相比于2D,3D的Bounding Box的表示除了多了一个维度的位置和尺寸,还多了三个姿态角。


3D目标检测数据集KITTI
地址:The KITTI Vision Benchmark Suite

gt_datbase 每一帧裁减出来的目标,用于数据增强
training 训练数据
calib 标定文件
label_2 帧值信息都是相机坐标系下的,并且3Dbox中心点xyz是底面信息,不是3Dbox中心
velodyne 是bin格式的点云
Imagesets Kitti数据集的分割
参考
velodyne文件是激光雷达的测量数据,以浮点二进制文件格式存储,每行包含8个数据,每个数据由四位十六进制数表示(浮点数),每个数据通过空格隔开一个点云数据由四个浮点数数据构成,分别表示点云的x、y、z、r(强度or 反射值),点云的存储方式如下表所示 :

3D点云深度学习分类
第二章:基于Point的深度学习网络
第一节: PointNet 及 PointNet++
-3D深度学习点云表示
多视角(muti-view):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征聚合起来形成三维物体;
体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5x5x5),但同时因为多了一个维度,时间和空间复杂度都非常高,目前三维卷积已经不是主流的方法了;点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割Mesh图(manifold,graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间连接关系表现为图的结构

PointNet提出背景:
存在的问题
点云数据是一种不规则的数据,在空间上和数量上可以任意分布,之前的研究者在点云上会先把它转化成一个规则的数据,比如栅格让其均匀分布,然后再用3D-cnn 来处理栅格数据

缺点|Motivation
Volumetric CNNs:对体素应用3DCNN。缺点是点云的坐标空间的稀疏性导致转成体素后的分辨率问题,以及3D卷积带来的开销。在未提出之前,主流做法:先进行体素化,然后进行3D的卷积(3D卷积带来的问题,计算量比较大,相对于2D来说,它多出了一个维度)
MultiviewCNNs:用3D点云数据投影到2D平面上用2D cnn 进行训练,使用传统的图像卷积来做特征学习。这种方法确实取得了不错的效果,但是缺点是应用非常局限,像分割、补全等任务就不太好做 在未提出之前,多视角方法
能否直接设计一种能够直接在原始点云上学习的统一框架?

semantic scene parsing 语义场景解析
PointNet设计思想
PointNet网络结构的灵感来自于欧式空间里的点云的特点。对于一个欧式空间里的点云,有三个主要特征:
无序性:虽然输入的点云是有顺序的,但是显然这个顺序不应当影响结果。点之间的交互:每个点不是独立的,而是与其周围的一些点共同蕴含了一些信息,因而模型应当能够抓住局部的结构和局部之间的交互。
变换不变性:比如点云整体的旋转和平移不应该影响它的分类或者分割
无序性: 系统化的解决方案:对称函数,具有置换不变性(下面是对等函数)
无序性不能用2D的网络来处理

神经网络本质是一个函数,如何用神经网络构建对称函数。最简单的例子:
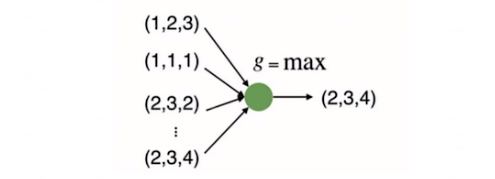
对每一维取最大值,找到了最远点,损失了很多几何信息
虽然是置换不变的,但是这种方
式只计算了最远点的边界,损失
了很多有意义的几何信息,如何
解决呢 ?
第二节: PointRCNN原理及代码精讲第三节: View-based 网络介绍
第三章:基于Voxel的深度学习网络
第一节: VoxelNet和Second
第二节:PointPillar原理及代码精讲
第三节:PV-RCNN原理及架构
第四节:其他Voxel-based网络介绍
第四章:点云-图像融合的深度学习网络
第一节:点云-图像前融合深度学习网络
第二节:点云-图像后融合深度学习网络