Kotlin进阶之协程从上车到起飞
公众号「稀有猿诉」 原文链接 Kotlin进阶之协程从上车到起飞
通过前面的一篇文章我们理解了协程的基本概念,学会协程的基本使用方法,算是正式入门了,接下来就是要深入的学习技术细节和高级使用方法,以期完全掌握Kotlin协程并能熟练的正确的使用协程,发挥出协程应有的并发编程能力。

本篇为协程三步曲中的第二篇:
- 初级篇:Kotlin进阶之协程从入门到放弃
- 高级篇:Kotlin进阶之协程从上车到起飞
- 终极篇:Kotlin进阶之协程从专家到出家
本篇将细致的讨论协程中的一些重要的话题,以期更好的理解协程的原理和正确的使用协程,将从协程运行的上下文开始。
深究协程上下文

创建协程的方法launch/async一共有3个参数,除了最后一个是协程的代码块以外,另外两个参数都是用来控制协程的,如协程上下文是用以控制协程运行环境的,包括在什么线程中去运行,句柄和树形关系以及何时切换线程,通过传递给launch/async的参数CoroutineContext。以及CoroutineStart就可以控制协程的运行。
fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T>
首先我们来看一下协程上下文对象CoroutineContext。
CoroutineContext
CoroutineContext是一个集合,具体元素类型是Element,Element重载了操作符,可以通过**+来形成集合。CoroutineContext是类似于Map的,每个Element有自己的Key,这是为了保证每个CoroutineContext对象中每个Key只能有一个Element对象。可以把CoroutineContext看成是Map,因此可以使用[]**来获取Key对应的Element,如取Job,可以用context[Job],取名字时可以用context[CoroutineName]等。
具体Element有四种:
- Job:协程的句柄,或者说唯一标识,用以具体控制每个协程的(cancel和join等),具有树形关系
- CoroutineDispatcher:用以指定协程的运行线程
- CoroutineName:给协程取个名字,方便调试
- CoroutineExceptionHandler:指定协程的异常处理器,用以处理未被捕获的异常
这里主要介绍一下Job,CoroutineDispatcher和Name,至于ExceptionHandler留到后面讲异常处理时再细讲。
Job
用launch创建一个协程时也会返回一个Job对象,它就是新创建的协程的句柄,但更好的方式是通过launch的参数,在上下文中指定一个Job对象作为协程的句柄。前面了讲过了,Job用以控制协程的,更为重要的是它能维持树形关系,父协程是可以控制子协程的,像cancel是会传导到所有的子协程的。自己创建Job对象就可以自由指定父协程,而不是默认的从CoroutineScope中继承。
另外,Job也会影响Exception handling,会在后面异常处理部分详细的讲。
CoroutineDispatcher
这个是在平时用的最多的,因为协程是一种并发编程范式,而要想真并发,必然要涉及线程的切换,不可能指望着主线程把所有的事情都干了,而Dispatcher的作用就是用于主动的指定协程的运行线程。与Java中的Executor,和RxJava中的Schedulers作用是一样的。有一些预定义好的Dispatcher可以用,它们定义在Dispatchers里面:
- Main 主线程,主函数所在的主线程,以及像UI框架(如Swing和Android)等的UI线程(主线程)
- IO 适合I/O密集型的协程,如网络操作(上传/下载),文件读写,数据库读写等等。它背后是线程池,线程的数量是比较多的。因为I/O虽然耗时,但一般都耗在等待上面,所以线程的数量可以多一些。
- Default 适合CPU密集型的协程,比如计算类型的,图形的计算,矩阵计算,多媒体文件的编解码,压缩解压缩,或者算法时间复杂度较高的任务等等。也是线程池,线程的数量一般是CPU的核数。这个线程池的数量很少,因为这是CPU密集型的任务,需要大量占用着CPU,使CPU一直处于忙碌状态,因此线程数量即使多了,也是没有用处的,因为多创建的线程根本得不到操作系统的调试,没有多余的CPU给线程跑。
- Unconfied 未给协程指定线程,协程会在当前的线程中执行(也就是调用者的线程),直到协程被挂起(suspended)。挂起后再继续(resume)时,由在恢复的线程中继续执行。很混乱吧,是的并发虽然讲究效率,虽然线程/协程啥时候进行,挂起并不能直接完全控制,但是我们仍希望并发要有秩序和确定性。一定要为新创建的协程指定其线程运行环境,因此,Unconfined不应该被使用。
一般情况下,框架预定义好了的这些dispatcher已经够用了。但如果真的不够用,也可以自定义dispatcher,用扩展函数asCoroutineDispatcher可以非常方便的把Java中的线程池Executors转化为dispatcher:
val dispatcher = Executors.newSingleThreadExecutor().asCoroutineDispatcher
launch(dispatcher) {
delay(1000)
println("Single thread dispatcher")
}
CoroutineName
CoroutineName是比较简单的结构,的构造方法可以传一个字符串用以指定协程的名字。协程的名字只有调试的意义,对于代码的运行没有任何影响。比如在调试的时候,或者在性能分析Profiling的时候,可以用名字更加方便的区分不同的协程,进而缩小调试的范围。
CoroutineStart
CoroutineStart,是一个枚举类型,用以控制协程的启动方式,具体有四种模式类型:
- DEFAULT 默认,如果未指定这个参数 时也是默认模式,根据指定的上下文环境,立即调度此协程
- LAZY 只有当需要此协程时才调度它。比较有意思,具体啥是需要呢,也就是当await其结果时,或者需要此协程去**生产事件(produce)或者消费事件(consume)**时。
- ATOMIC 以原子化的方式来调度此协程,也就是以不可取消的方式来调度协程。也就是说在协程代码块执行之前是不可取消的。
- UNDISPATCHED 在当前的线程环境(也就是调用者的线程)中立即执行协程直到协程的第一个挂起点。挂起之后,继续时则在指定的上下文中的线程运行。
一般情况下,我们用默认的就行了。但当熟悉了协程以后,在适当的场景使用不同的启动方式参数可以更大限度的发挥协程的威力。
延展阅读:
- Coroutine context and dispatchers
- 揭秘kotlin协程中的CoroutineContext
- 深入Kotlin协程系列|图解上下文
- 协程是怎么切换线程的
启动,挂起,让度和延续
知道了如何创建协程,以及如何通过参数指定它运行的上下文和影响启动的参数后,就需要详细的了解一下协程的几中运行状态,以及什么是挂起,如何让度再到咋回到延续。
协程的状态
与Java中的线程类似,协程也是有几种不同的状态的,可以参考下表:
| 协程状态 | 描述 | isActive | isCompleted | isCancelled |
|---|---|---|---|---|
| New | 协程刚被创建,但还未被调度,未运行 | false | false | false |
| Active | 已被调度,已运行 | true | false | false |
| Completing | 等待子协程结束中 | true | false | false |
| Cancelling | cancel子协程中 | false | false | true |
| Cancelled | 已被取消,是最终状态 | false | true | true |
| Completed | 已结束,是最终状态 | false | true | false |
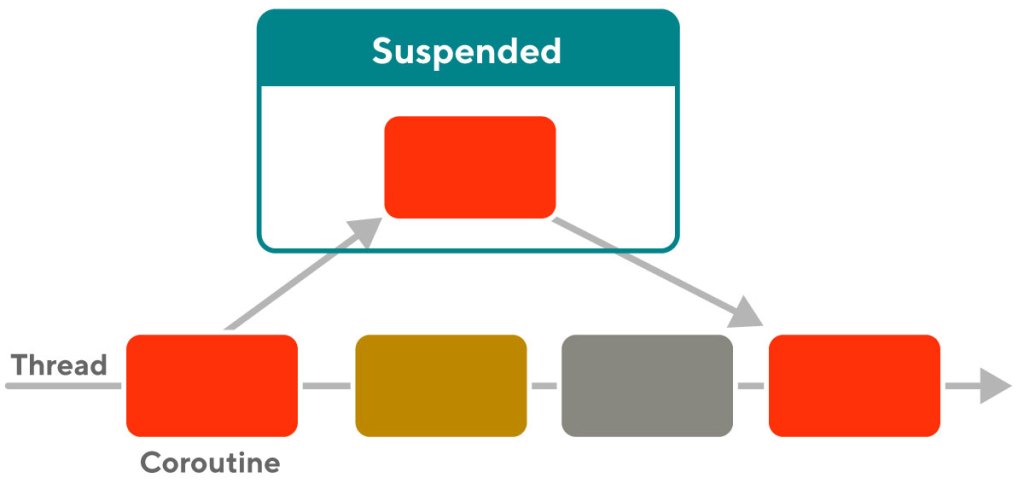
需要注意,这些状态是由接口Job来定义的,它是一个广义上的异步并发任务,协程是它的一个实现而已,协程返回的也是对象Job,可以通过Job的方法如join,cancel,isActive等方法来控制协程和查询状态。协程的状态转移可以看这张图:

协程的挂起,让度和延续
用suspend修饰的函数必须在协程里调用,因为它们在运行的时候可以让协程挂起,协程遇到delay或者join以及await/awaitAll时就会被挂起。除此之外,还可以调用yield主动进行挂起,这会释放线程,让其他协程得以运行,这便是让度。挂起,是可能导致线程切换的,这取决 于我们如何设置协程的上下文以及start参数。
那么,Kotlin中的协程是如何做到协程延续(resume)时,协程的运行状态和本地变量等是如何得以在线程之间保存和传播的呢?这就涉及到了Continuation,在挂起的时候会创建一个Continuation对象,它把恢复协程所需要的数据都会打包起来,延续运行的的时候只需要调用Continuation#resume就可以了。一般情况下,我们不需要了解Conitnuation的创建过程,因为这过于底层了,Kotlin的编译器会帮我们做好一切。
扩展阅读:
- 一文搞懂 Kotlin Coroutine Job 的工作流程
- 详解Kotlin协程实现原理
- 源解 Kotlin 协程
无限序列
在继续深入学习其他话题之前先来看一个实际的妙用协程的例子,使用协程创建异步无限序列。集合(Collections)是对象的容器,用来存储对象实例(objects)的,把对象放入到集合中,也就是说在『放入』的过程中时,元素必须已经创建好了。而序列(Sequences)并不存储对象实例,它按需生成对象,也就是说只有需要某个元素时,序列才会生成它,并且序列可以有无限个元素,它是按需生成元素,如果需要可以有无限发子弹。
序列是按需生成元素,因此它具有延迟化,占用资源少的特点。对于用sequence builder来创建无限序列时,其实就用到了协程,比如说创建一个质数的序列:
fun primes(start: Int): Sequence<Int> = sequence {
println("Infinite prime sequence:")
var n = start
while (true) {
if (n > 1 && (2 until n).none { i -> n % i == 0 }) {
yield(n)
println("\tGenerating next prime after $n")
}
n++
}
}
fun main() {
for (prime in primes(start = 10)) {
println("Received $prime")
if (prime > 30) {
break
}
}
}
这段代码的输出是:
Infinite prime sequence:
Received 11
Generating next prime after 11
Received 13
Generating next prime after 13
Received 17
Generating next prime after 17
Received 19
Generating next prime after 19
Received 23
Generating next prime after 23
Received 29
Generating next prime after 29
Received 31
序列生成器之所以能够一个一个的生成元素,并返回给调用者的原因就是在于yield()函数,它是一个suspend函数,执行后就会挂起,然后调用者的代码得以继续执行。如果没有把sequence生成器挂起的话,它会陷入死循环。我们可以详细的看一眼sequence的签名:
fun <T> sequence(
block: suspend SequenceScope<T>.() -> Unit
): Sequence<T>
可以发现sequence builder的参数是一个运行在SequenceScope中的挂起函数,内部一定是会创建一个协程来运行此代码块。并且,我们在此代码块中一定要让协程挂起,否则可能会陷入死循环。
拓展阅读 Sequence builders in Kotlin Coroutines。
协程取消
创建协程能得到协程的句柄即Job对象,可以用来控制协程,最重要的一个操作就是取消协程,通过cancel方法,目的是终止协程的运行。我们先来看一个示例:
val job = launch {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancel() // cancels the job
job.join() // waits for job's completion
println("main: Now I can quit.")
输出如下:
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
main: Now I can quit.
协程取消的特性
协程只有处于挂起状态时才能被取消,这个可以看上面Job的状态表格。父协程被取消,它同时也会取消所有的子协程,并且父协程只有在所有子协程退出后才会退出,这种树形管理关系是结构化并发的基础。另外就是,为了更好的实现可取消性,在协程内部要在关键的地方检查isActive,比如循环时,或者做一些耗时操作时,以及时响应cancel。
为了更全面的响应取消操作,也要捕获CancellationException,并在finally中清理占用的资源,这是因为对于挂起的库函数,当被cancel时会抛出CancellationException。如果有Java的并发经验的同学可以发现,这跟取消Thread是一样的(即interrupt一个Thread)。
不可取消协程
有时候可能希望协程不被取消,也就是不能被取消,因为可能在执行一些关键的初始化工作,不可被打断和取消,这时可以用withContext(NonCancellable) { … }来作为协程的上下文环境,这坨代码块就不可被取消了,只有执行完才会返回,任外部如何cancel都没用:
val job = launch {
try {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
} finally {
withContext(NonCancellable) {
println("job: I'm running finally")
delay(1000L)
println("job: And I've just delayed for 1 sec because I'm non-cancellable")
}
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")
这段代码非常有意思,父协程启动了子协程后就取消它,子协程中的try代码块会被取消,repeat不会执行完,但它的finally代码块是不可以取消的,一定要执行完子协程才能返回。
扩展阅读Cancellation and timeouts。
超时处理
对于异步和并发编程来说,超时处理是非常关键的,虽然异步地或者并发地去执行任务,但对于主线程来说不可能永远等待任务,比如请求网络时,如果在网络库未设置连接超时,那么主线程或者说主协程就有可能面临无限等待。一般的做法是把问题丢给用户,用户受不了了,不想等了,那就返回或者退出,返回或者退出自然会去cancel掉所有的异步任务,无论是协程还是线程。
但是,更为优雅的方式是对于每一个启动的异步任务,都主动的设置一个超时时间,在给定的时间内任务仍未结束,那就取消它,终止它。这样整体的并发会更加的有秩序和可控,当然了,取消随时仍可能发生,超时时间未到时,仍是可以主动取消的。
在Kotlin中,给协程加上超时时限非常的方便,用扩展函数withTimeout(limit) {…}就可以非常方便的给代码块加上超时时限,当超时时限达到时,如果协程仍未返回,会终止协程并抛出异常TimeoutCancellationException。
withTimeout(1300L) {
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500L)
}
}
//I'm sleeping 0 ...
//I'm sleeping 1 ...
//I'm sleeping 2 ...
//Exception in thread "main" kotlinx.coroutines.TimeoutCancellationException: Timed out waiting for 1300 ms
扩展阅读 探索 Kotlin 协程 withTimeout 原理。
异常处理
程序运行总会遇到异常情况,至少有一半的代码都是在处理各种异常情况。协程就是以异常的方式运行一坨代码块,这些代码块自然也可能会抛出异常,这时要如何处理呢?有同学举手了,好办啊,try-catch不就行了?这位同学先坐下,对于同步的代码是可行的,但对于异步代码并不总是可行。并发编程中的异常处理略微稍复杂一些,我们来详细的看看协程中的异常处理方法。
协程中异常的传播
对于同步代码来说,在外面调用层包裹try-catch总是管用的,比如说:
fun boo() {
try {
// do some sync works that may throw exceptions
} catch (e: Exception) {
println("Got you, no where to run!!!")
}
}
但对于异步代码,这不管用,比如说想在协程外面try-catch异常,是行不通的:
fun main() = runBlocking {
try {
val job = launch(Dispatchers.Default + SupervisorJob()) {
println("Ready to run!")
delay(400)
throw Exception("You will never catch me, hahaha!")
}
job.join()
} catch (e: Exception) {
println("Try to handle everything: ${e.message}")
}
}
//Ready to run!
//Exception in thread "DefaultDispatcher-worker-1" java.lang.Exception: You will never catch me, hahaha!
协程中抛出了异常,但外层并没有能catch住,这段代码会crash。我们再看看async的情况:
fun main() = runBlocking {
try {
val deferred = async(Dispatchers.Default + SupervisorJob()) {
println("Ready to run!")
delay(400)
throw Exception("You will never catch me, hahaha!")
}
deferred.await()
} catch (e: Exception) {
println("No where to run: ${e.message}")
}
}
//Ready to run!
//No where to run: You will never catch me, hahaha!
这回外层的catch是生效的,能把协程中的异常捕获住!到此,我们可以总结一下协程中的异常的传播:launch创建的协程异常是不可在外面捕获的,而async则可以。
**注意:**无论是launch还是async,如果父协程不去join或者await等待子协程的话,则是死活都无法捕获到子协程的异常的,因为协程是异步的,launch/async很快就返回了,会立马执行它后面的语句,所以,当协程运行时,外面的代码(即launch/async后面的语句)可能已执行完了,自然是不可能捕获到任何异常的,可以通过把上面两个例子中的join和await去掉,然后运行试试看,都会crash。
那么,要想处理协程中的异常,一是让协程自己去try-catch,另外就是使用CoroutineContext的另一个Element,叫作CoroutineExceptionHandler。
未捕获异常处理器CoroutineExceptionHandler
如果协程内部出现了未捕获的异常(uncaught exceptions)时,会先看协程上下文中有没有指定未捕获异常处理器(uncaught exception handler),如果没有则会按前面说的方式再传播。在指定协程上下文时可以用一个CoroutineExceptionHandler对象来当作uncaught excpetion handler,以处理未捕获异常:
fun main() = runBlocking {
val handler = CoroutineExceptionHandler { _, exception ->
println("Totally under control: ${exception.message}")
}
val job1 = launch(Dispatchers.Default + SupervisorJob() + handler) {
delay(200)
throw Exception("Exploded!!!")
}
val job2 = launch(Dispatchers.Default + SupervisorJob() + handler) {
delay(800)
throw Exception("Can I run away???")
}
val deferred = async(Dispatchers.Default + SupervisorJob() + handler) {
delay(400)
throw Exception("You will never catch me, hahaha!")
}
joinAll(job1, job2, deferred)
}
//Totally under control: Exploded!!!
//Totally under control: Can I run away???
可以发现通过给launch指定CoroutineExceptionHandler可以捕获其uncaught excpetions。但是注意看async创建的协程似乎没效果,这是因为async本来就会把异常传播给其父协程,不会给CoroutineExceptionHandler处理,所以对于async来说指定了handler也是没有效果的,会被async忽略掉。
还需要注意的是,只有根协程(root coroutine)的上下文中的CoroutineExceptionHandler是有效的,被用于处理uncaught exceptions。协程是有树形关系的,一个协程出现未捕获异常(uncaught exception)时,它会把它丢给它的父协程处理,一层一层的传播直到根协程(root coroutine),如果根协程的上下文环境中有handler,那就用它来处理,否则就crash。换句话说,只有最外层的协程(root coroutine)设置一个handler给其context就够了,其他的子协程即使设置了handler也是没有用处的。
fun main() = runBlocking {
val handler = CoroutineExceptionHandler { _, exception ->
println("Totally under control: ${exception.message}")
}
val job1 = launch(Dispatchers.Default + SupervisorJob() + handler) {
val subHandler = CoroutineExceptionHandler { _, exp ->
println("Try to intercept exceptions: ${exp.message}")
}
val subJob = launch(Dispatchers.Default + subHandler) {
val grandJob = launch(Dispatchers.Default + subHandler) {
throw Exception("Bad thing happened deep down!")
}
grandJob.join()
}
subJob.join()
}
val job2 = launch(Dispatchers.Default + SupervisorJob() + handler) {
delay(800)
throw Exception("Can I run away???")
}
joinAll(job1, job2)
}
//Totally under control: Bad thing happened deep down!
//Totally under control: Can I run away???
是的,聪明的你一定发现了,这里的规则其实与Java中的Thread.UncaughtExceptionHandler是一样一样的,它也是只需要有一个所以用static成员就可以了。
链式反应
当协程发生未捕获异常(uncaught exceptions)而被动终止时,它自己肯定是会被终止的,这个异常会沿树形向上传给它的父协程,其父协程也会被终止(cancle),由于结构化并发,父协程被cancel时,会cancel其所有的子协程。就像链式反应一样,在未经特殊处理情况下,一旦子协程发生异常,就会导致其所在的树形结构的所有协程被终止,可以通过一个示例来验证一下:
fun main() = runBlocking {
val handler = CoroutineExceptionHandler { _, exception ->
println("Totally under control: ${exception.message}")
}
val root = launch(Dispatchers.Default + SupervisorJob() + handler) {
val subJob1 = launch {
val grandJob = launch {
delay(100)
throw Exception("Bad thing happened from deep down!")
}
grandJob.join()
println("Sub coroutine #1 completed")
}
val subJob2 = launch {
try {
delay(60 * 1000)
} finally {
println("Sub coroutine #2 cancelled!!")
}
}
val subJob3 = launch {
try {
delay(60 * 1000)
} finally {
println("Sub coroutine #3 cancelled!!!")
}
}
val subJob4 = launch {
try {
delay(60 * 1000)
} finally {
println("Sub coroutine #4 cancelled!!!!")
}
}
joinAll(subJob1, subJob2, subJob3, subJob4)
}
root.join()
}
//Sub coroutine #2 cancelled!!
//Sub coroutine #4 cancelled!!!!
//Sub coroutine #3 cancelled!!!
//Totally under control: Bad thing happened from deep down!
其他几个子协程subJob2,subJob3和subJob4都在工作中,但被grandJob的未捕获异常给终止掉了。另外,我们还可以发现这个异常是在根协程(root)里面的Uncaught exception handler中处理了,同时还可以发现,异常处理handler是在所有子协程被终止结束后才得以处理。再来看一个来自官方教程上面的例子:
val handler = CoroutineExceptionHandler { _, exception ->
println("CoroutineExceptionHandler got $exception")
}
val job = GlobalScope.launch(handler) {
launch { // the first child
try {
delay(Long.MAX_VALUE)
} finally {
withContext(NonCancellable) {
println("Children are cancelled, but exception is not handled until all children terminate")
delay(100)
println("The first child finished its non cancellable block")
}
}
}
launch { // the second child
delay(10)
println("Second child throws an exception")
throw ArithmeticException()
}
}
job.join()
//Second child throws an exception
//Children are cancelled, but exception is not handled until all children terminate
//The first child finished its non cancellable block
//CoroutineExceptionHandler got java.lang.ArithmeticException
这个例子非常的有意思,用到了好几个特性,先是第二个子协程发生了未捕获异常(ArithmeticException),导致其父协程job被取消,但job还有其他子协程,所以还会去cancel仍在运行中的子协程,这个子协程被取消了,它正在delay,这时cancel它会抛CancellationException而终止delay,进入finally,finally中有一个不可以被打断的任务。而只有当所有子协程都终止完成了,job的handler才得以处理这个异常(ArithmeticException)。
监管责任(Supervision)
链式反应,异常会在树形关系中传递导致整个树形协程都被终止,这样设计的目的在于结构化并发,它能让整体结构的行为较一致,形成一个整体结构。很多时候这并不是想要的行为,比如说启动四个协程去服务器取四段数据,然后拼成一个整体使用,即使某段异常了,取不到,也没有必须把整体都取消掉。
可以给父协程加上监管责任,这样当其某一个子协程失败了,它会履行监管责任,保障其他子协程仍能运行,可以用一个例子来看一下:
val supervisor = SupervisorJob()
with(CoroutineScope(coroutineContext + supervisor)) {
// launch the first child -- its exception is ignored for this example (don't do this in practice!)
val firstChild = launch(CoroutineExceptionHandler { _, _ -> }) {
println("The first child is failing")
throw AssertionError("The first child is cancelled")
}
// launch the second child
val secondChild = launch {
firstChild.join()
// Cancellation of the first child is not propagated to the second child
println("The first child is cancelled: ${firstChild.isCancelled}, but the second one is still active")
try {
delay(Long.MAX_VALUE)
} finally {
// But cancellation of the supervisor is propagated
println("The second child is cancelled because the supervisor was cancelled")
}
}
// wait until the first child fails & completes
firstChild.join()
println("Cancelling the supervisor")
supervisor.cancel()
secondChild.join()
}
//The first child is failing
//The first child is cancelled: true, but the second one is still active
//Cancelling the supervisor
//The second child is cancelled because the supervisor was cancelled
有两种方式加上监管责任,一种是在协程上下文时指定一个SupervisorJob对象,比如前面那个例子,可以这样修改:
fun main() = runBlocking {
val handler = CoroutineExceptionHandler { _, exception ->
println("Totally under control: ${exception.message}")
}
val root = launch(Dispatchers.Default + SupervisorJob() + handler) {
val subJob1 = launch {
val grandJob = launch(SupervisorJob()) {
delay(100)
throw Exception("Bad thing happened from deep down!")
}
grandJob.join()
println("Sub coroutine #1 completed")
}
val subJob2 = launch {
try {
delay(10 * 1000)
} finally {
println("Sub coroutine #2 cancelled!!")
}
}
val subJob3 = launch {
try {
delay(20 * 1000)
} finally {
println("Sub coroutine #3 cancelled!!!")
}
}
val subJob4 = launch {
try {
delay(30 * 1000)
} finally {
println("Sub coroutine #4 cancelled!!!!")
}
}
joinAll(subJob1, subJob2, subJob3, subJob4)
}
root.join()
}
//Totally under control: Bad thing happened from deep down!
//Sub coroutine #1 completed
//Sub coroutine #2 cancelled!!
//Sub coroutine #3 cancelled!!!
//Sub coroutine #4 cancelled!!!!
除了单独的为每个协程上下文指定SupervisorJob以外,还有更为优雅的方式就是在合适的层级使用扩展函数superivorScope来创建一个scope,我们用此方法改造另一 个例子:
fun main() = runBlocking {
val handler = CoroutineExceptionHandler { _, exception ->
println("CoroutineExceptionHandler got $exception")
}
val job = GlobalScope.launch(handler) {
supervisorScope {
launch { // the first child
try {
delay(10 * 1000)
} finally {
withContext(NonCancellable) {
println("Children are cancelled, but exception is not handled until all children terminate")
delay(100)
println("The first child finished its non cancellable block")
}
}
}
launch { // the second child
delay(10)
println("Second child throws an exception")
throw ArithmeticException()
}
}
}
job.join()
}
//Second child throws an exception
//CoroutineExceptionHandler got java.lang.ArithmeticException
//Children are cancelled, but exception is not handled until all children terminate
//The first child finished its non cancellable block
取消异常(CancellationException)不是异常
需要注意取消异常CancellationException并不是常规的异常,不遵循前面说的规则,它会被忽略掉。这是因为CancellationException只会发生在主动取消协程时Job#cancel,这是自上而下的取消协程,并不需要链式反应和异常处理。
扩展阅读:
- Coroutine exceptions handling
- 彻底掌握kotlin 协程异常处理
- Kotlin篇 > > 协程中的异常及异常处理
调试
调试总是必须且难免的,有时候代码运行与预期不符,但又想不通为啥时就需要进行调试以弄清楚为啥会产生那样的结果。与常规的代码一样,调试有两种方式,一是通过IDE中的『Debug』功能,step-by-step的运行代码,修改代码;另一种就是通过加日志。
在IDE中『Debug』
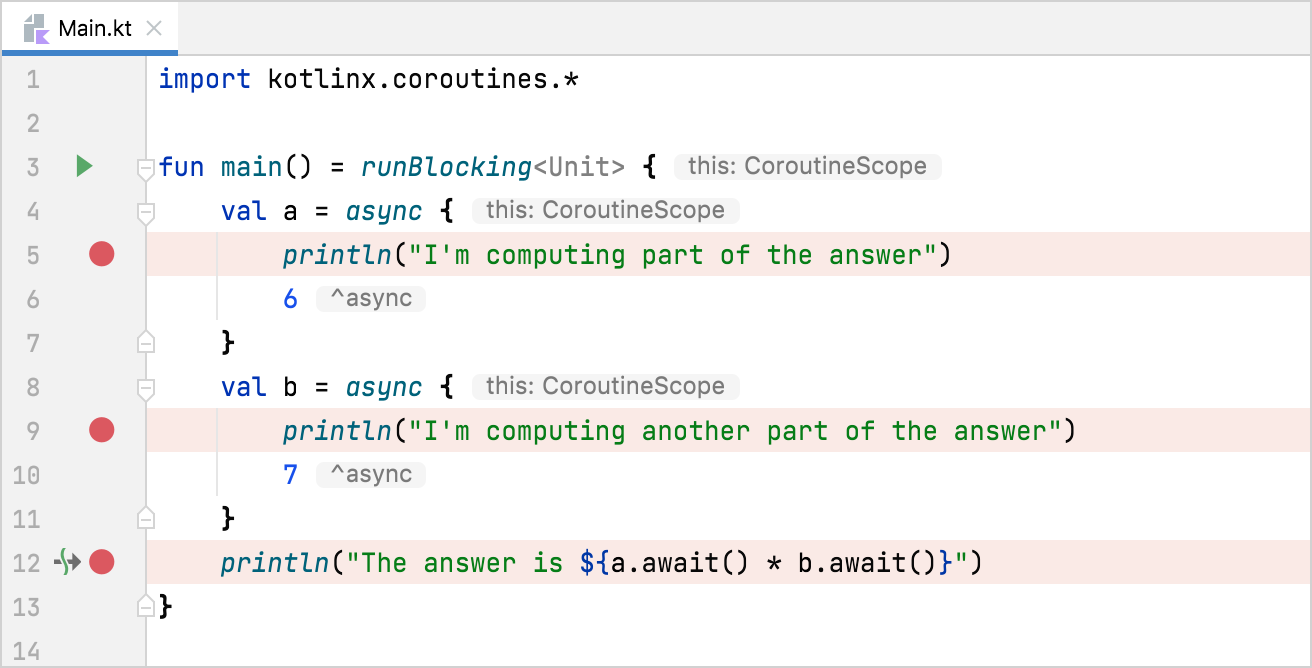
凡是IDE,或者说敢称自己是IDE的,肯定有调试功能,也就是step-by-step式的单步跟踪功能。对Kotlin比较友好的IDEA和Android Studio自然也不例外。协程也是标准的Kotlin代码,所以也是可以调试的,并且在调试方面其实没有区别。都是先在代码中设置断点,然后使用虫子图标的『Debug』功能就好了。对于IDEA系(包括Android Studio),设置断点就是在代码编辑器行号旁边点一下就可以了:
然后点虫子图标进行『Debug』即可:
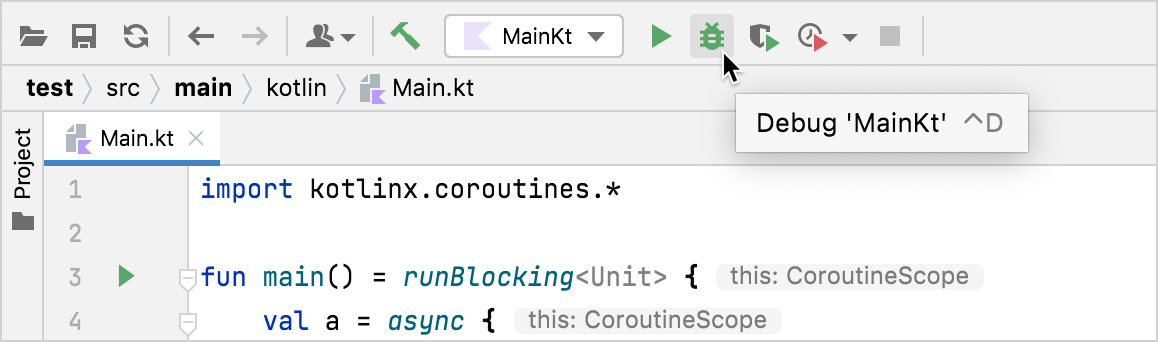
这时代码会运行,然后在预设置的断点处停止,并出现调试窗口,这里面可以单步跟踪,继续执行,或者查看代码的运行状态。对于协程来说,会比较方便的显示每个协程的状态,比如是SUSPENDED还是RUNNING等。

注意,对于异步流程和并发流程比较多的代码来说,『Debug』会扰乱原本的时序,因为JVM必须在断点处停下来。因此,『Debug』更适用于比较复杂的大段的同步代码的调试,比如协程内部的某一段逻辑。
用日志来调试
另外的方式就是用日志来查看代码的运行状态,其实这跟协程也没啥关系,用日志输出想要输出的信息就可以了。只不过对于协程,我们需要知道协程信息,也就是说要知道每条日志是哪个协程输出的。这就需要一个能够输出当前协程名字的方法,一个办法是在打日志时输出CoroutineName,可以通过context[CoroutineName];更为方便的方法是直接输出线程名字Thread.currentThread().name,然后给JVM加上选项**-Dkotlinx.coroutines.debug**就可以得到协程的详细名字:
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() = runBlocking {
val a = async {
log("I'm computing a piece of the answer")
6
}
val b = async {
log("I'm computing another piece of the answer")
7
}
log("The answer is ${a.await() * b.await()}")
}
//[main @coroutine#2] I'm computing a piece of the answer
//[main @coroutine#3] I'm computing another piece of the answer
//[main @coroutine#1] The answer is 42
从日志中可以看每条日志所在的线程名字(即前面的main)和协程名字(即@后面的内容)。注意,一定要给VM加上选项**-Dkotlinx.coroutines.debug**,要不然不会带有协程名字,只有线程名字:
# Output without -Dkotlinx.coroutines.debug
[main] I'm computing a piece of the answer
[main] I'm computing another piece of the answer
[main] The answer is 42
对于Android应用来说,是没有办法直接给VM加上选项的,这时可以通过设置系统属性,在应用的入口处,比如在Application#onCreate或者Activity#onCreate时,设置属性即可:
System.setProperty("kotlinx.coroutines.debug", if (BuildConfig.DEBUG) "on" else "off")
对于异步流程和并发流程较多的地方,用日志是比较理想的调试手段,因为它对程序运行的干扰相对较小。
当然了,并发编程最大的问题就是比较难调试,调试必然需要知道程序运行的状态,无论是日志还是单步调试都会对程序的运行造成影响,从而使原本的逻辑发生改变。相信同学们都会遇到类似的情景:加了几句日志,Bug就不复现了。这就好比量子世界里面观察者对量子的影响一样,听起来不可思议,但确实会发生。并发编程需要在编码之前做好功课,用什么样的模型,选什么样的范式,谁是生产者,谁是消费者,用图形画一画,厘清思路,之后再去编码实现。而不是上来就编码,边想边做,发现线程不够用了,就多开一个吧,A数据回来的太快了,消费者还没有准备好,那就先用一个Map存着吧,这样乱撞式的开发,最后可能会实现需求,但出现Bug必然是极难调试的。
扩展阅读:
- Debugging coroutines and threads
- Debug coroutines using IntelliJ IDEA – tutorial
- Kotlin Jetpack 实战 | 08. 协程“不为人知”的调试技巧
协程间通信
大多数时候协程之间是需要通信的,比如说一个协程在从网络拉取数据,另一个协程可能需要显示进度。可以通过一些共享变量来实现,但这会有潜在的问题,因为协程随时可能会切换线程运行环境,这时共享变量就会存在线程安全问题。Kotlin则提供了更为优雅的方式,即Channel。
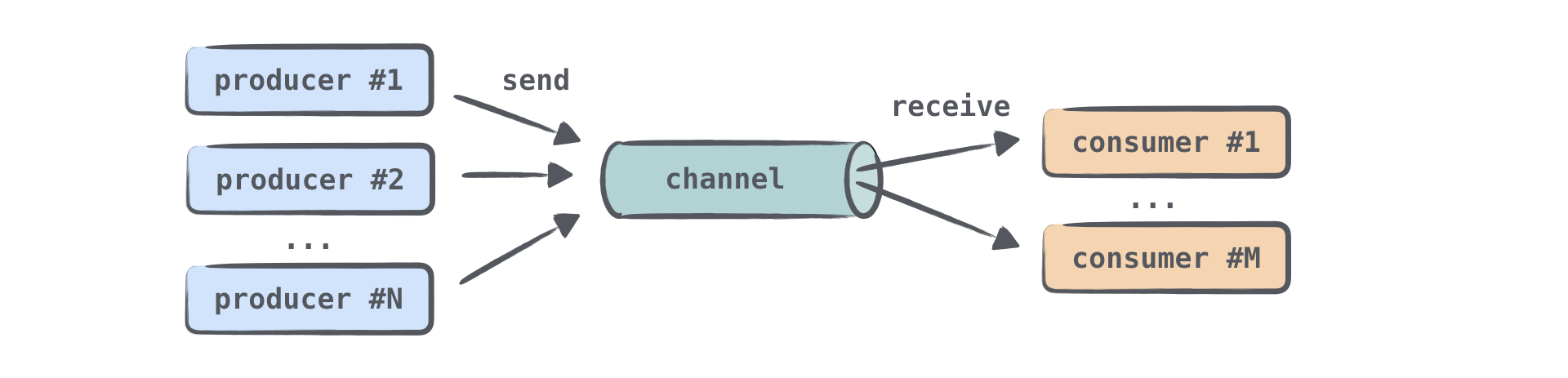
Channel是一个生产者-消费者模式,它是线程安全的,可以在生产者与消费之间传递数据。它与Java中的BlockingQueue是类似的,不同之处在于,它是为协程而生的,它的操作只会挂起不会阻塞,但都是线程安全的。生产者通过send来生产数据,消费者通过receive来消费数据。生产者和消费者都可以用协程来实现,所以Channel是一个非常优雅的协程通信方式,高效,可靠且线程安全,来看个小示例:
fun main() = runBlocking<Unit> {
val channel = Channel<String>()
launch(Dispatchers.Default) {
channel.send("A1")
delay(10)
channel.send("A2")
logd("Producer A done")
}
launch(Dispatchers.IO) {
channel.send("B1")
logd("Producer B done")
}
launch {
repeat(3) {
val x = channel.receive()
logd("Got $x")
}
}
}
fun logd(message: Any?) {
println("[${Thread.currentThread().name}] $message")
}
//[main @coroutine#4] Got A1
//[main @coroutine#4] Got B1
//[DefaultDispatcher-worker-1 @coroutine#3] Producer B done
//[DefaultDispatcher-worker-2 @coroutine#2] Producer A done
//[main @coroutine#4] Got A2
进一步学习:
- Coroutines and Channels
- More about channels
- Kotlin协程之一文看懂Channel管道
- Kotlin协程之Channel的使用与原理
- Channel in Kotlin Coroutines
在安卓中使用协程

从2019年开始,安卓开发生态中已经是Kotlin first了,Kotlin是推荐的编程语言,因此协程自然也变成了推荐的异步和并发编程方式。想要在Android应用开发中用好协程,除了协程本身的知识以外,还需要注意的就是Android本身的东西。Android本身是有框架和相当多组件的,并不像我们前面写demo那样,都是从主函数main开始。因此,我们需要注意的就是多多使用框架和组件已经为我们定义好的协程工具,比如UI逻辑层的协程都要在viewModelScope中启动;以及要符合一些架构上的原则,比如Repository要有自己的scope和dispatcher。
扩展阅读:
- Kotlin coroutines on Android
- Improve app performance with Kotlin coroutines
- Best practices for coroutines in Android
书籍推荐
当对Kotlin以及协程有了基本的认识之后,如果想要进阶的学习,就需要读一些专题书籍,这里推荐两本:
- 《Learn Concurrency in Kotlin》 这本书以并发为主题,只不过是用Kotlin协程的方式来实现并发,所以它的重点在于并发编程Concurrency,具体实现方式其实可以多种多样。
- 《深入理解Kotlin协程》 这本书的优点在于会横向的介绍其他编程语言中的并发范式,从而能够深入的理解协程,对于有一定编程经验的人来说,横向比较的方式是非常有效的。
参考资料
- Mastering Kotlin Coroutines
- The Beginner’s Guide to Kotlin Coroutine Internals
- Understanding Kotlin Coroutines
欢迎搜索并关注 公众号「稀有猿诉」 获取更多的优质文章!
原创不易,「打赏」,「点赞」,「在看」,「收藏」,「分享」 总要有一个吧!