xAI开发的一款巨大型语言模型(HLM)--Grok 1

在xAI发布Grok的权重和架构之后,很明显大型语言模型(LLM)的时代已经过去,现在是巨大型语言模型(HLM)的时代。这个混合专家模型发布了3140亿个参数,并且在Apache 2.0许可下发布。这个模型没有针对任何特定应用进行微调。

The cover image was generated using Midjourney based on the following prompt proposed by Grok: A 3D illustration of a neural network, with transparent nodes and glowing connections, showcasing the varying weights as different thicknesses and colors of the connecting lines.
什么是Grok?
Grok-1拥有3140亿个参数,是目前为止市场上最大的开源模型。与OpenAI的GPT-3相比,Grok的参数大小是GPT-3的三倍多。
Grok 旨在以机智的方式回应,并在其回答中加入一些幽默元素。与其他大型语言模型(LLMs)不同,Grok 拥有来自 X 平台的实时世界知识。它还能回答大多数大型语言模型所拒绝的问题。
Grok仍处于测试阶段,因为仅训练了2个月。但它的性能将日益提高。
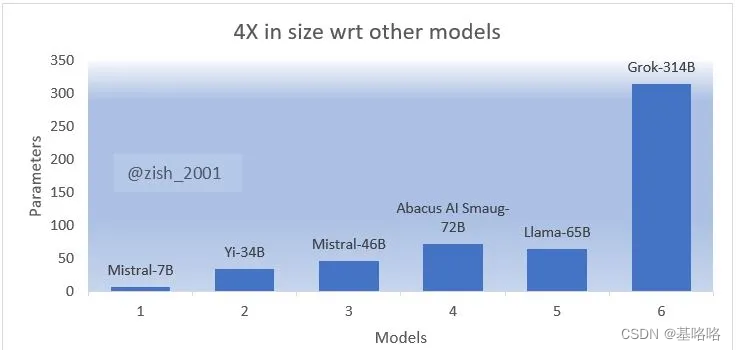
Grok的特性
- 混合专家(MoE)架构:MoE架构是一种设计神经网络的方法,它由多个专门的“专家”组成,这些专家结合起来进行预测。在这个案例中,Grok有8个专家,但同时只有2个是活跃的。这种方法允许模型有效地扩展到大量参数,通过在多个专家之间分配工作负载来实现。
- 旋转位置嵌入(RoPE):RoPE是一种技术,使模型能够有效地处理序列位置信息。传统的位置嵌入在计算上可能较为昂贵,但RoPE旨在更高效地实现位置信息的优点。
- 上下文大小:Grok的上下文大小为8192个标记。这指的是模型一次可以处理的标记(通常是词或子词)的最大数量。更大的上下文大小允许模型处理更长的序列,这对于翻译、摘要或其他任何需要远距离上下文的序列基础任务来说是有益的。
- 词汇量:Grok的词汇量为131072。这是模型可以表示或预测的独特标记(例如,词或子词)的数量。更大的词汇量允许模型处理更广泛的输入。
- 许可:Grok是开源的,并遵循Apache 2.0许可。这个许可允许自由使用、修改和分发软件,只要对任何派生作品也授予相同的自由。
- 量化权重:为了提高存储和计算效率,Grok使用了量化权重。量化是一个减少权重精度的过程,以减小模型大小和加快推理速度。在将深度学习模型部署到生产环境时,这是一种常见的做法,因为资源可能受限。
- 训练数据:模型在大量文本数据上进行训练,但没有针对任何特定任务进行微调。这意味着Grok可能是一个通用的NLP模型,能够执行广泛的NLP任务,而不需要进行特定任务的调整,尽管不进行特定任务的微调可能会导致在没有进一步训练的情况下模型在某些NLP任务上性能不佳。
Grok评测
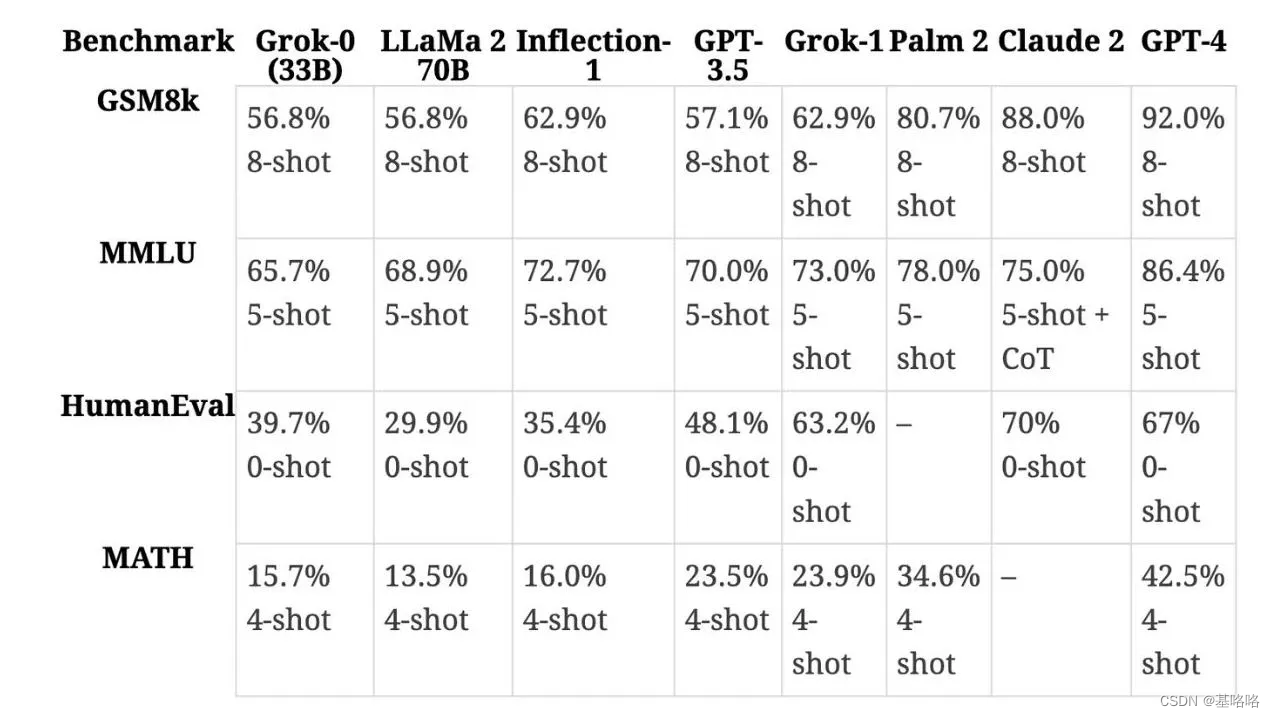
Grok 的 MMLU 得分为 73%,超过了 Llama 2 70B 的 68.9% 和 Mixtral 8x7B 的 70.6%。
Grok安装
有关加载和运行 Grok-1 的说明在此 GitHub (GitHub - xai-org/grok-1: Grok open release)中进行了解释。将代码隆到本地即可,其中包含用于加载和运行 Grok-1 开放权重模型的 JAX 示例代码。
确保下载检查点并将 ckpt-0 目录放入checkpoints :
测试运行代码:
pip install -r requirements.txt
python run.py该脚本在测试输入上加载模型中的检查点和样本。
由于模型规模较大(314B参数),需要有足够GPU内存的机器才能使用示例代码测试模型。该存储库中 MoE 层的实现效率不高。选择该实现是为了避免需要自定义内核来验证模型的正确性。
权重下载
1. 可以使用 torrent 客户端和此磁力链接下载权重:
magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
2. 或者从HuggingFace 🤗 Hub下载:
git clone https://github.com/xai-org/grok-1.git && cd grok-1
pip install huggingface_hub[hf_transfer]
huggingface-cli download xai-org/grok-1 --repo-type model --include ckpt-0/* --local-dir checkpoints --local-dir-use-symlinks False模型总结
Grok-1 目前设计有以下规格:
参数:314B
架构:8 名专家的组合 (MoE)
专家利用率:每个代币使用 2 名专家
层数:64
注意头:48 个用于查询,8 个用于键/值
嵌入大小:6,144
标记化:具有 131,072 个标记的 SentencePiece 标记生成器
附加功能:
旋转嵌入 (RoPE)
支持激活分片和8位量化
最大序列长度(上下文):8,192 个标记
参考
- 论文: Open Release of Grok-1
- 代码: GitHub - xai-org/grok-1: Grok open release
- https://huggingface.co/xai-org/grok-1
- https://huggingface.co/Xenova/grok-1-tokenizer