巧用时间换空间:解读 ArcGraph 如何灵活应对有限内存下的图分析
导读:ArcGraph 是一款云原生架构、存查分析一体化的分布式图数据库。本文将详细解读 ArcGraph 如何灵活应对有限内存下的图分析。
01 引言
在图分析技术广泛应用的当下,学术界和各大图数据库厂商热衷于提升图分析技术的高性能指标。然而,追求高性能计算的过程中,常采用“以空间换时间”的方式,即通过增大内存使用量来加速计算。但现阶段外存图计算尚不成熟,图分析仍依赖全内存计算,这导致高性能图计算引擎对大内存产生强依赖,内存不足时图分析任务将无法执行。
我们从过往诸多客户案例中发现,客户投入到图分析中的硬件资源通常是固定且有限的,测试环境的资源则比生产环境更有限。客户对图分析的时效性要求通常为 T+1, 属于典型的离线分析需求。因此,客户期望图计算引擎降低对 CPU 和内存等资源的需求量,而不过于追求算法高性能,只要满足 T+1 即可。这对于大部分图计算引擎而言是一个不小的挑战。CPU 的需求量相对较容易控制,而内存需求则很难在较短研发周期内大幅优化。
ArcGraph 同样面临以上挑战,但我们通过在客户交付实践中的不断总结和打磨,使其图计算引擎具备了在时间与空间上平衡处理的灵活性。目前,ArcGraph 内置的图计算引擎在图分析性能指标方面处于业界领先地位,并还在持续优化与提升。接下来,我们将从引擎底层的数据结构到上层算法的调用等多角度,解读 ArcGraph 如何巧用时间换空间应对有限内存下的图分析。
02 点 ID 的类型的选择
ArcGraph 图计算引擎支持三种点 ID 类型:string、int64、int32。string点类型的支持,可提高对源数据的兼容性,但相对于 int64 而言,因为需要在内存中维护一份 string 到 int64 的点 id 映射表,会增加内存使用量。若指定点类型为 int64,则 ArcGraph 会将源数据中的 string 类型点 ID 生成一份 int64 映射表,并置于外存中,内存中只保留映射后的int64 类型点边数据。待计算完成后,再将映射表读入内存做 string id 还原。因此,使用 int64 类型的点 ID,会增加用于映射表在外存与内存间交换的额外时间消耗,但也会显著降低整体的内存使用量,节省的内存大小取决于原始 ID 的长度及点数据量。
此外,ArcGraph 图计算引擎还对 int32 做了支持,对于源数据总点数在 4000 万以下的场景,相较于 int64 可进一步降低约 30%的内存使用量。
以下为在 ArcGraph 的执行图算法 API 中指定载图点 ID 类型的示例:
curl -X 'POST' 'http://myhost:18000/graph-computing?reload=true&use_cache=true' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"algorithmName": "pagerank",
"graphName": "twitter2010",
"taskId": "pagerank",
"oid_type": "int64",
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"props": [],
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
]
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": []
}
]
},
"algorithmParams": {
}
}'
03 开启 Varint 编码
Varint 编码用于对整数进行压缩和编码,是一种可变长度的编码方法。以 int32 为例,正常存储一个数值需要 4 个字节。而常规 Varint 编码中,每个字节用后 7 位表示数据,最高位为标志位。

- 如果最高位为 0,表示到当前字节的后 7 位即为该数据的全部,后续字节与该数据无关。例如上图中的整数 1,仅需要一个字节表示:00000001,而后续字节则不属于整数 1 的数据。
- 如果最高位为 1,表示后续字节依然是该数据的一部分。例如上图中的整数 511,需要 2 个字节来表示:11111111 00000011,后续字节则是 131071 的数据。
利用这种思想,32 位的整数均可用 1-5 个字节表示。相应的,64 位整数可用 1-10 个字节表示。在实际使用场景中,小数字的使用率远远高于大数字,尤其对于 64 位整数而言。因此,通过 Varint 编码通常能起到明显的压缩效果。Varint 编码有多个变种,开源实现也有多种。
ArcGraph 图计算引擎支持使用 Varint 编码来压缩内存中的边数据存储(主要为 CSR/CSC)。当开启 Varint 编码后,边数据所占内存可显著降低,实测可达 50%左右。同时,因编解码带来的性能损耗也会高达 20%左右。因此,在开启前,需要清晰了解使用场景和客户需求,确保因节省内存而带来的性能损耗在可接受范围内。
以下为在 ArcGraph 的载图 API 中开启图计算的 Varint 编码示例:
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true"
}'
04 开启 Perfect HashMap
Perfect HashMap 于其他 HashMap 的区别在于其采用了 Perfect Hash Function(PHF)。函数 H 将 N 个 key 值映射到 M 个整数上,这里 M>=N,且满足 H(key1)≠ H(key2)∀key1,key2,则该函数是完美哈希函数。如果 M=N,则 H 是最小完美哈希函数(Minimal Perfect Hash Function,简称 MPHF)。此时 N 个 key 值会被映射到 N 个连续的整数上。
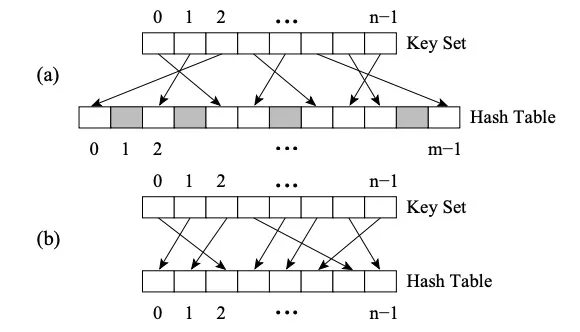
图(a) 为PHF,图 (b)为MPHF
上图是两级哈希的 FKS 策略 。首先将数据通过第一级哈希映射到 T 空间中,然后冲突的数据随机选取新的哈希函数映射到 S 空间中,且 S 空间的大小 m 是冲突数据的平方(例如,T2 中有三个数字产生冲突,则映射到 m 为 9 的 S2 空间中),此时可以容易找到避免碰撞的哈希函数。适当选择哈希函数减少一级哈希时的碰撞,则可以使预期存储空间为 O(n)。
ArcGraph 图计算引擎在内存中会维护一份原始点 id 到内部点 id 的映射,内部点是连续的长整形类型,便于做数据压缩以及向量化优化。该映射本质是一个 hashmap,但在底层实现上 ArcGraph 提供了两种方式:
- Flat HashMap - 优势是构建速度快,劣势是通常需要更大的内存空间,以减少频繁的 hash 碰撞。
- Perfect HashMap - 优势是可用较少的内存保证最坏情况为 O(1)效率的查询,而劣势是事先需要知道所有 key,且构建时间长。
因此,开启 Perfect HashMap 也可以达到以时间换空间的目的。根据测试发现,对于原始点到内部点 id 的映射集,Perfect HashMap 的内存占用通常仅为 Flat HashMap 的 1/5 左右,但相应的,其构建时间也是其 2-3 倍。
以下为在 ArcGraph 的载图 API 中开启图计算的 Perfect HashMap 示例:
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true",
"use_perfect_hash": "true"
}'
05 优化算法实现与结果处理
算法实现层面的内存使用取决于算法的具体逻辑,我们从实践中总结出以下几点,可达到以时间换空间的目的:
适当减少算法中的多线程处理以及 ThreadLocal 对象的使用。算法中经常会涉及临时点边集合的存储,这些存储如果出现在多线程逻辑中,则整体内存会随线程数增加而增加。适当降低线程并发数量,或减少 ThreadLocal 大对象的使用,都会有助于内存的降低。
适当增加内外存的数据交换。根据算法的具体逻辑,将暂时不用的大对象序列化到外存中,而在使用该对象时,以流式读取的方式读入内存,以避免多个大对象同时占据大量内存。
以下为体现以上两点做法的一个算法实现示例:
void IncEval(const fragment_t& frag, context_t& ctx,
message_manager_t& messages) {
...
...
if (ctx.stage == "Compute_Path"){
auto vertex_group = divide_vertex_by_type(frag);
//此处采用单线程for循环而非多线程并行处理,意在防止多个path_vector同时占内存导致OOM。
for(int i=0; i < vertex_group.size(); i++){
//此处path_vector是每个group中任意两点间的全路径,可理解为一个超大对象
auto path_vector = compute_all_paths(vertex_group[i]);
//拿到该对象后不会在当前stage使用,所以先序列化到外存中。
serialize_path_vector(path_vector, SERIALIZE_FOLDER);
}
...
...
}
...
...
if (ctx.stage == "Result_Collection"){
//在当前stage中,将之前stage生成的多个序列化文件合并为一个文件,并把文件路径返回。
auto result_file_path = merge_path_files(SERIALIZE_FOLDER);
ctx.set_result(result_file_path);
...
...
}
...
...
}
计算结束后,结果写入外存并释放图计算引擎的相关内存。某些场景下,结果处理程序会运行在图计算集群服务器上,读取图计算结果并进一步处理。如果图计算引擎内存一直未释放出计算结果,最坏情况下将会导致当前服务器内存中有两份结果数据。而在大数据量场景下,一份结果数据就会占用非常高的内存。因此,在该类场景中需优先考虑将计算结果写入外存,并及时释放图计算引擎内存。
同时,对于高性能和低资源占用的“既要又要”,ArcGraph 团队也将继续挑战,联合学术界与业界合作伙伴,对载图内存与计算效率做进一步打磨,实现技术的进一步突破。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.kler.cn/a/328449.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!