MySQL开发02-数据库设计
文章目录
- 1、数据库设计概述
- 2、数据库逻辑设计
- 2.1、创建并检查ER模型
- 2.2、将ER模型映射为表
- 3、数据库物理设计
- 3.1、数据库物理设计概述
- 3.2、分析事务
- 3.3、选择文件组织方式
- 3.4、选择索引
- 3.4.1、推荐不建索引的场景
- 3.4.2、推荐建索引的场景
- 3.5、反范式设计
- 3.6、列出最终表的详细说明
- 4、总结
1、数据库设计概述
MySQL数据库设计分为逻辑设计和物理设计两个步骤。
2、数据库逻辑设计
数据库逻辑设计分为设计ER模型和将ER模型映射为表两个步骤。
2.1、创建并检查ER模型
- 数据库设计人员将根据需求文档,创建与数据库相关的那部分实体关系图(ERD)/类图。这些图形和需求文档相结合,将有助于相关人员更好地理解业务逻辑和实际的表设计。互联网的一些应用往往比较简单,所以经验丰富的研发人员直接设计数据表也是很常见的情况,但是对于复杂的项目,仍然推荐绘制E-R图。
- 设计ER模型的步骤如下:
- 标识实体和关系:此步骤主要是标识实体及实体之间的关系。
- 标识实体的方法,研究用户需求说明书里的名词或名词短语:例如员工管理系统里的员工、部门。在线考试系统里的课程、试卷、学员。从用户提供的需求说明中得到的一组实体可能不是唯一的。然而,分析过程的不断迭代必定会引导你选择对完成系统需求来说足够用的实体。
- 标识关系的方法,也研究需求说明书里的动词或动词短语:大多数情况下,关系都是二元的,例如,员工实体属于某个公司,试卷实体属于某个课程,学员(实体)解答某张试卷(实体)。
- 标识实体和关系中的属性、主键等信息:比如学员实体包括的属性可能有学员号、姓名、性别、生日等信息。
- 检查是否满足需求:在确定好实体后,我们再检查实体模型是否能够满足的我们的需求。
- 标识实体和关系:此步骤主要是标识实体及实体之间的关系。
2.2、将ER模型映射为表
这个步骤的主要目的是为步骤1建立的ER模型产生表的描述。这组表应该代表逻辑数据模型中的实体、关系、属性和约束。产生表的描述后,需要检查表是否满足用户的需求和业务规则。
3、数据库物理设计
3.1、数据库物理设计概述
物理数据库设计用于确定逻辑设计如何在目标关系数据库中物理地实现,和特定的DBMS有关。它描述了基本表、文件组织、用户高效访问数据的索引、相关的完整性约束及安全性限制。步骤如下:
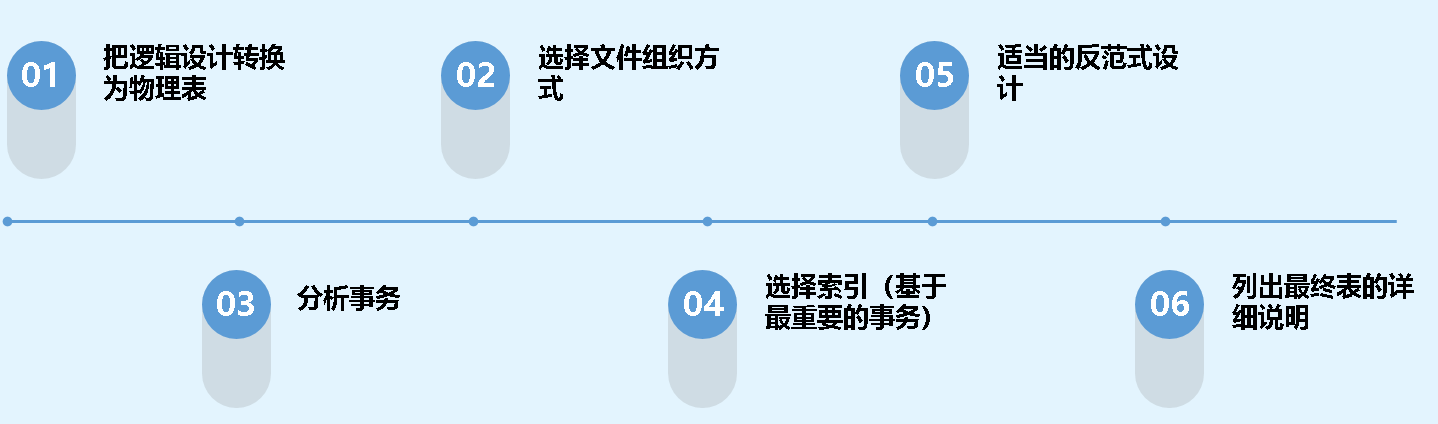
3.2、分析事务
- 分析事务指的是分析数据库需要满足的用户需求,只有了解了必须要支持的事务的细节,才能做出有意义的物理设计抉择。我们将利用这些信息来确定所需要的索引。
- 分析预期的所有事务是极为耗时的,只需研究最重要的那部分事务即可。最活跃的20%的事务往往占据了总的数据访问量的80%。当进行分析时,你会发现这个80/20规则是很有用的方针。所以分析事务主要按以下步骤:
- 找到最重要的两类事务:
- 经常运行的事务和对性能产生重影响的事务。
- 业务操作的关键事务。
- 分析事务细节:
- 事务运行的频率?频率信息将标识需要仔细考虑的表。
- 事务的高峰时间?
- 访问记录数比较多的事务。
- 分析SQL语句细节
- 将要使用的所有查询条件。
- 连接表所需要的列(对查询事务来说)。
- 用于排序的列(对查询事务来说)。
- 用于分组的列(对查询事务来说)。
- 可能使用的内置函数(例如AVG,SUM)。
- 被该事务更新的列。
- 找到最重要的两类事务:
3.3、选择文件组织方式
- 选择文件组织方式是指选择表数据的存放方式,以有效的方式存储数据。如果目标DBMS允许,则可以为每个表选择一个最佳的文件组织方式。
- 对于MySQL来说,选择文件组织方式,基本上等同于选择主键,因为MySQL主键采用聚簇索引。
- 一般选择以下列作为聚簇索引:
- 经常用于连接操作的列,因为这样会使连接更有效率。
- 在表中经常按某列的顺序访问记录的列。
- 自增主键在一般情况下也会工作得很好。
3.4、选择索引
设计索引需要平衡性能的提升和维护的成本。
3.4.1、推荐不建索引的场景
- 不必为小表创建索引。在内存中查询该表会比存储额外的索引结构更加有效。
- 如果查询将检索表中的大部分记录(例如25%),即使表很大,也不创建索引。这时候,查询整表可能比用索引查询更有效。
- 避免为由长字符串组成的列创建索引。
3.4.2、推荐建索引的场景
- 为检索数据时大量使用的列增加二级索引。
- 为经常有如下情况的列添加二级索引:查询或连接条件、ORDER BY、GROUP BY、其他操作(如UNION或DISTINCT)
- 考虑是否可以用覆盖索引(covering index)。
3.5、反范式设计
MySQL对于多表连接的支持比较差,也就是优化器比较简单,往往为了性能,我们需要考虑一些反规范化的设计。反范式增加了维护数据一致性的成本,因此需要谨慎实施。包括但不限于如下几点:
- 合并表;
- 冗余列:减少连接;
- 引入重复组:例如,某公司有5个电话号码,我们不必使用额外的电话表,而是增加5个列telNO1、telNO2、telNO3、telNO4、telNO5(此种情况一般用于重复组的项的数量不多且不易变化)。
- 创建统计表;
- 水平/垂直分区;
3.6、列出最终表的详细说明
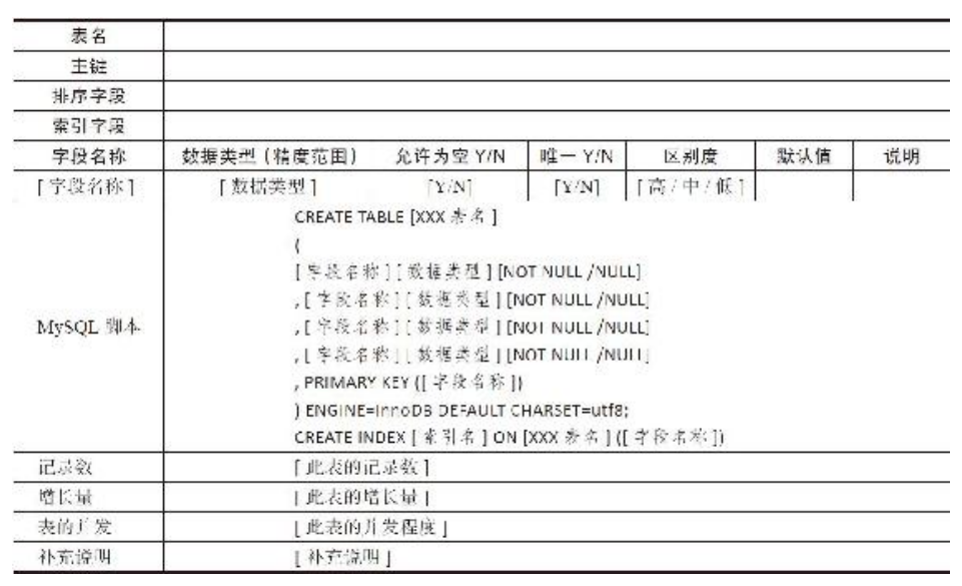
- 表的详细说明只要针对最重要、最关键的表做即可,模板见左图;
- 主要的说明项包括:
- 记录数:可补充说明未来半年、1年或2年的记录数。
- 增长量:单位时间的数据增长量。如果量大可以按每天;如果量不大则可以按每月。
- 表字段的区分度:主要是考虑到将来在此字段上建立索引类型选择时作参考,当字段值唯一时可以不考虑;当字段值不唯一时,估算一个区别度,近似即可。例如:如果一个表的NAME字段共有2000个值,其中有1999个不同的值,那么1999/2000=0.99越接近1区别度则越高,反之区别度就越低。
- 表的并发:根据具体的业务需求预测表的并发访问,或者说明高峰期的并发程度。
4、总结
- 数据库设计分为逻辑设计和物理设计两个大的步骤。
- 数据库逻辑设计首先是要根据需求中的名词识别出实体、根据需求中的动词识别出关系,从而建立ER模型,然后根据ER模型设计逻辑表。
- 数据库物理设计先逻辑表的字段转为物理表的字段,然后对两类关键表(数据量大的表、业务关键表)进行事务分析,确定其运行频率、高峰时间和记录数,分析SQL语句细节(查询条件列、排序列、分组列、事务更新列),根据对事务的分析选择主键、二级索引的创建策略,确定是否要做一定的反范式设计,最终给出关键表的详细说明(记录数、增长量、并发量、表字段的区分度、索引建立等)。注意只能对关键表做事务分析和详细说明。
- 对于数据量小的表、查询总是需要类似全表扫描的表都不建议建立索引。