BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
参考
BERT原文[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)
【(强推)李宏毅2021/2022春机器学习课程】 https://www.bilibili.com/video/BV1Wv411h7kN/?p=73&share_source=copy_web&vd_source=30e93e9c70e5a43ae75d42916063bc3b
【BERT 论文逐段精读【论文精读】】 https://www.bilibili.com/video/BV1PL411M7eQ/?share_source=copy_web&vd_source=30e93e9c70e5a43ae75d42916063bc3b
BERT是Transformer的双向编码器,是self-supervised,包括两个步骤:
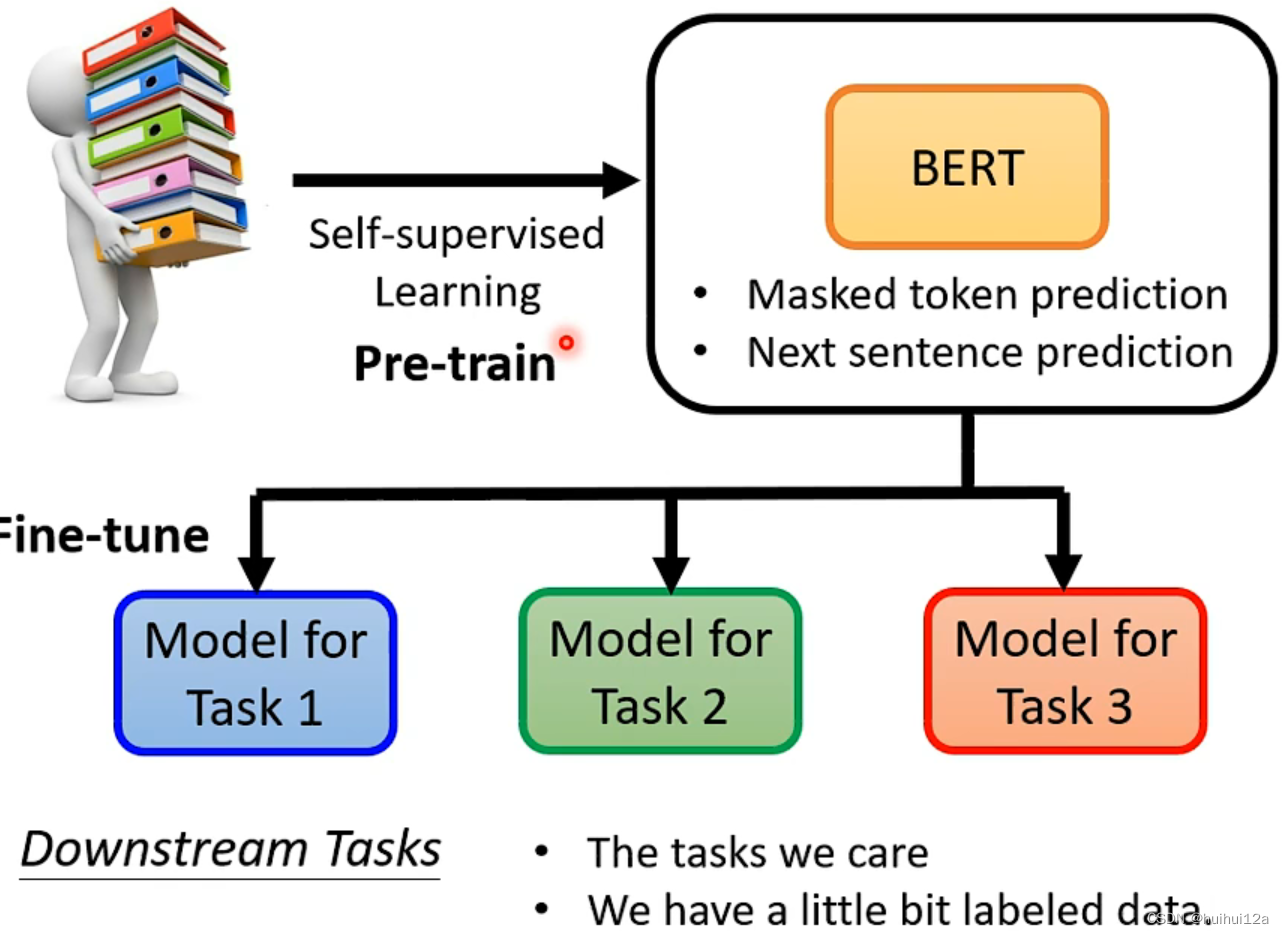
1.使用两个任务预训练:1)Masked LM,随机mask token,然后预测原始的mask token;2)NSP,判断是否为下一个句子,两个句子是否连在一起(类似于二分类)。
2.微调。之后将预训练的BERT用于下游任务。在应用到不同下游任务时,只用改一下输出层,使用下游任务的输入和输出。BERT模型首先使用预训练的参数进行初始化。只有为了任务加入的层需要随机初始化,从头训练。然后使用来自下游任务的标记数据对所有参数进行微调。
为什么BERT work:
相近的词具有相似的embedding,但是有一词多义的现象,BERT考虑上下文,形成更好的embedding
所以BERT在预测mask token时,学会了抽取上下文信息,通过上下文生成更好的embedding
Abstract
BERT: Bidirectional Encoder Representations from Transformers——来自Transformer的双向编码器表示来改进基于微调的方法。
BERT旨在通过在所有层中联合调节左右上下文来预训练未标记文本的深度双向表示。只需要一个额外的输出层,就可以对预训练的BERT模型进行微调,从而为各种任务创建最先进的模型,而无需对特定于任务的体系结构进行实质性修改。
GPT是单向的,BERT是双向的。ELMo是基于RNN的,在应用到不同下游任务时,需要对架构进行一些调整,而BERT基于transformer的,在应用到不同下游任务时,只用改一下输出层。
1 Introduction
1.语言模型预训练已被证明对改善许多NLP任务是有效的。包括sentence-level任务,如自然语言推理和释义,旨在通过整体分析来预测句子之间的关系;token-level任务,如命名实体识别和问题回答,其中模型需要在token-level产生细粒度输出。
2.存在两种将预训练语言表示应用于下游任务的策略:基于特征和微调。基于特征的方法,如ELMo,使用特定于任务的架构,将预训练的表征作为额外的特征输入模型;微调方法,例如GPT,引入最小的任务特定参数,并通过简单地微调所有预训练参数在下游任务上进行训练。这两种训练方法在预训练过程中共享相同的目标函数,它们使用单向语言模型学习一般语言表示。
3.目前技术限制了预训练表示的能力,特别是对于微调方法,主要限制的是标准语言模型是单向的,例如,GPT只能使用单向(左右)结构,每个token只能关注Transformer的自注意中的先前token,对sentence-level任务token-level任务不是最优,从两个方向上合并上下文至关重要。
4.BERT使用“掩码语言模型”(MLM)预训练目标缓解了前面提到的单向约束,该目标受到完形填空任务的启发,掩码语言模型从输入中随机掩码一些token,目标是仅基于masked word的上下文预测masked word的原始词汇id。和left-to-right 语言模型预训练不同,MLM目标使表示能够融合左右上下文,这允许我们预训练一个深度双向Transformer。除了屏蔽语言模型,我们还使用了“下一句预测”任务,联合预训练文本对表示.
本文贡献:1)证明双向预训练对语言表征的重要性,BERT使用掩码语言模型实现预训练的深度双向表示。而GPT使用单向的语言模型,ELMo使用独立训练的从左到右和从右到左的LM的简单拼接。
2)预训练的表示减少了许多高度工程化的特定于任务的架构的需求。
2 Related Work
2.1 Unsupervised Feature-based Approaches
将预训练的词嵌入,作为特征,当作输入一部分。
预训练词嵌入是现代NLP系统中不可分割的一部分,与从头学习的词嵌入相比,提供了显著的改进。
ELMo及其前身沿着不同的维度概括了传统的词嵌入研究。它们从从左到右和从右到左的语言模型中提取上下文敏感的特性。每个token的上下文表示是从左到右和从右到左表示的连接。当将上下文词嵌入与现有的特定于任务的架构集成时,ELMo提高了几个主要NLP基准的最新水平。
2.2 Unsupervised Fine-tuning Approaches
将预训练的参数拿来进行微调
与基于特征的方法一样,第一种方法仅从未标记的文本中预训练词嵌入参数(Collobert和Weston, 2008)。
最近,产生上下文标记表示的句子或文档编码器已经从未标记的文本中进行了预训练,并为有监督的下游任务进行了微调(Dai和Le, 2015;霍华德和鲁德,2018年;Radford等人,2018)。这些方法的优点是需要从头学习的参数很少。
2.3 Transfer Learning from Supervised Data
从具有大型数据集的监督任务上有效迁移很有用。
3 BERT
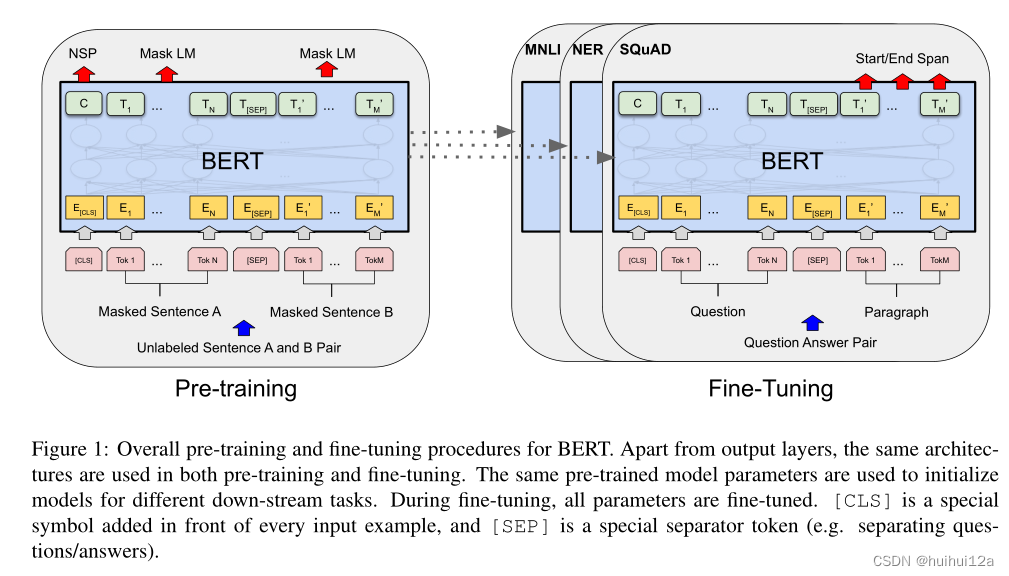
在我们的框架中有两个步骤:预训练和微调。在预训练期间,模型在不同的预训练任务中使用未标记的数据进行训练。为了进行微调,BERT模型首先使用预训练的参数进行初始化,然后使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型,即使它们是用相同的预训练参数初始化的。
BERT的显著特征它是跨不同任务的统一架构。预训练的体系结构和最终下游体系结构之间存在很小的差异。
Model Architecture:采用多层双向Transformer编码器。
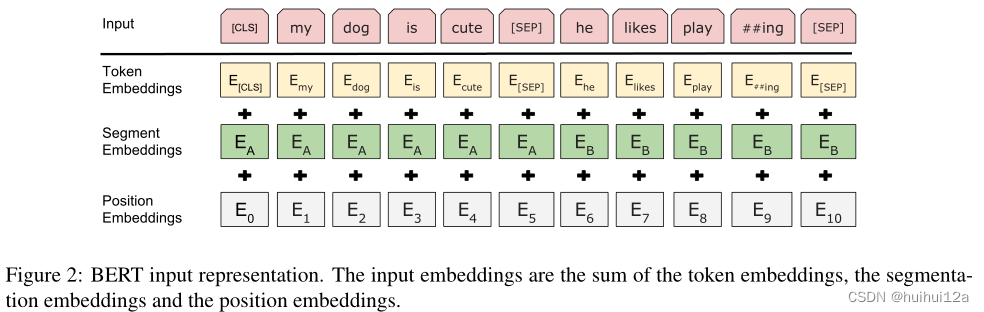
Input/Output Representations:为了使BERT处理各种下游任务,我们的input representation能够明确的表示在一个token sequence中的single sentence和a pair of sentences。input token sequence可能是single sentence或者two sentences packed together。
使用WordPiece嵌入,每个序列的第一个标记总是一个特殊的分类标记([CLS])。与此标记对应的最终隐藏状态用作分类任务的聚合序列表示,分类任务时使用。句子对被打包成一个序列。我们用两种方法来区分这些句子。首先,我们用一个特殊的标记([SEP])将它们分开。其次,我们为每个标记添加一个学习嵌入,表明它属于句子a还是句子b。如图1所示,我们将输入嵌入表示为E,将特殊[CLS]标记的最终隐藏向量表示为C∈RH,将第i个输入标记的最终隐藏向量表示为Ti∈RH。对于给定的token的input representation是由对应的token,segment,和position embedding的和构造的。
3.1 Pre-training BERT
本文没有使用传统的left-to -right或right-to-left语言模型训练BERT,使用两个无监督任务预训练BERT
3.1.1 Task1 Masked LM
预测被mask的token

为了训练深度双向表示,按照一定百分比随机mask(屏蔽)一些 input tokens,然后预测被mask的tokens。在这种情况下,与mask token相对应的最终隐藏向量被送入词汇表上的输出softmax.
虽然这样允许我们获得一个双向训练模型,但缺点是在pre-training和fine-tuning之间造成了不匹配,因为masked tokens在fine-tuning时不会出现。因此我们并不总是用实际的[MASK]token替换“masked”words。训练数据生成器随机选择15%的token位置进行预测。如果第i个token被选中,我们将第i个token替换为(1)80%的时间为[MASK]token(2)10%的时间为随机token3)10%的时间为不变的第i个token.然后使用Ti来预测具有交叉熵损失的原始token

3.1.2 Task2 Next Sentence Prediction (NSP)
判断是否为下一个句子,两个句子是否连在一起(类似于二分类)
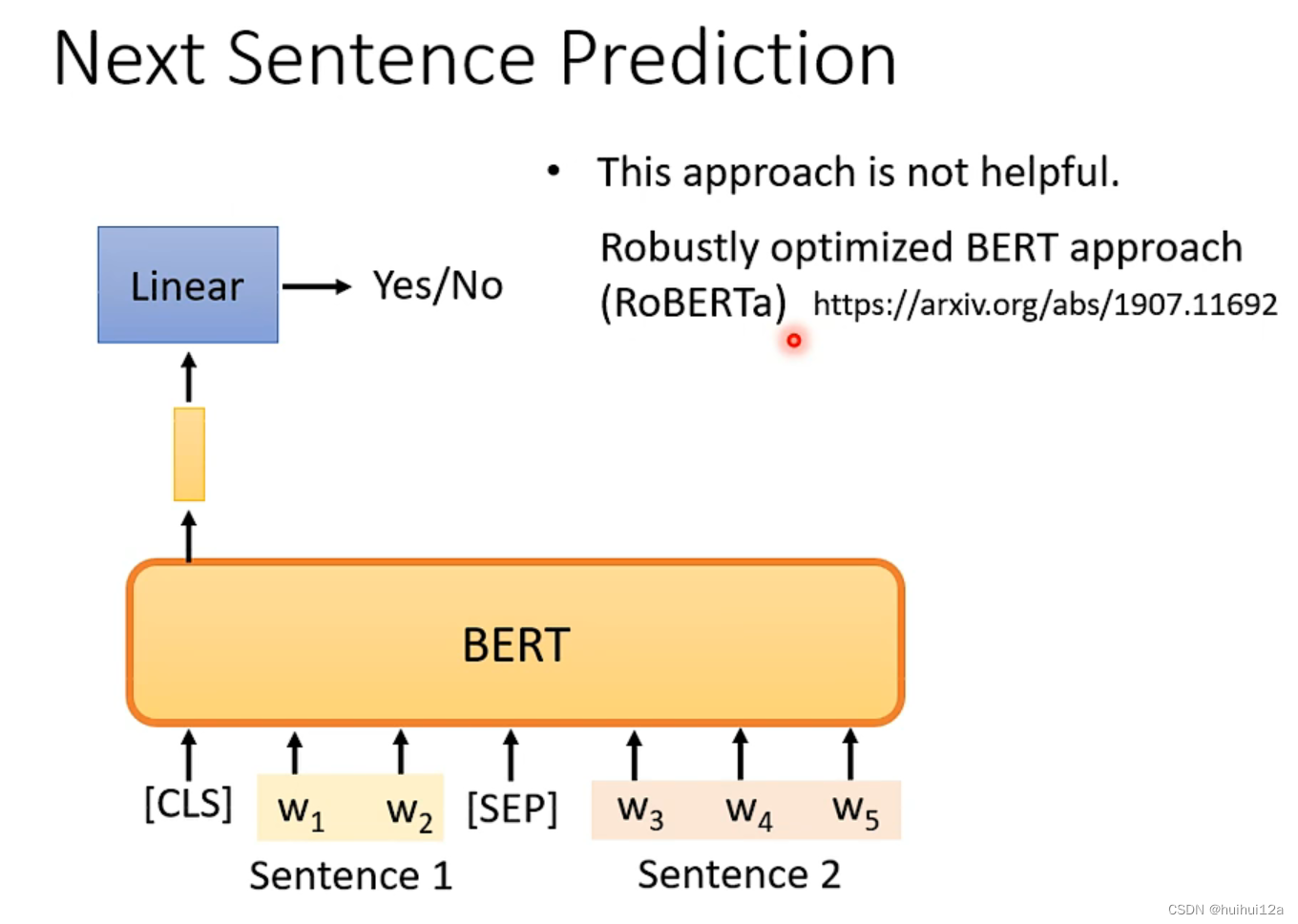
NSP是许多重要的下游任务,如问答和自然语言推断,都是基于对两个句子之间关系的理解。为了训练一个能够理解句子关系的模型,我们对一个二元化的下一句预测任务进行了预训练,该任务可以从任何单语言语料库中简单地生成。具体来说,在为每个预训练示例选择句子A和B时,50%的时间B是A之后的实际下一句句子(标记为IsNext), 50%的时间B是语料库中的随机句子(标记为NotNext)。
3.2 Fine-tuning BERT
对于每个任务,我们只需将特定于任务的输入和输出插入BERT,并对所有端到端的参数进行微调。在输入端,预训练的句子A和句子B类似于(1)释义中的句子对,(2)蕴涵中的假设-前提对,(3)问题回答中的问题-段落对,以及(4)文本分类或序列标注中的退化文本-∅对在输出端,标记表示被送入输出层用于标记级任务,例如序列标记或问题回答,而[CLS]表示被送入输出层用于分类,例如包含或情感分析
4 如何使用BERT
任务1:判断sentence是positive还是negative。加入的Linear层是随机初始化,而BERT是用pre-trained的参数初始化

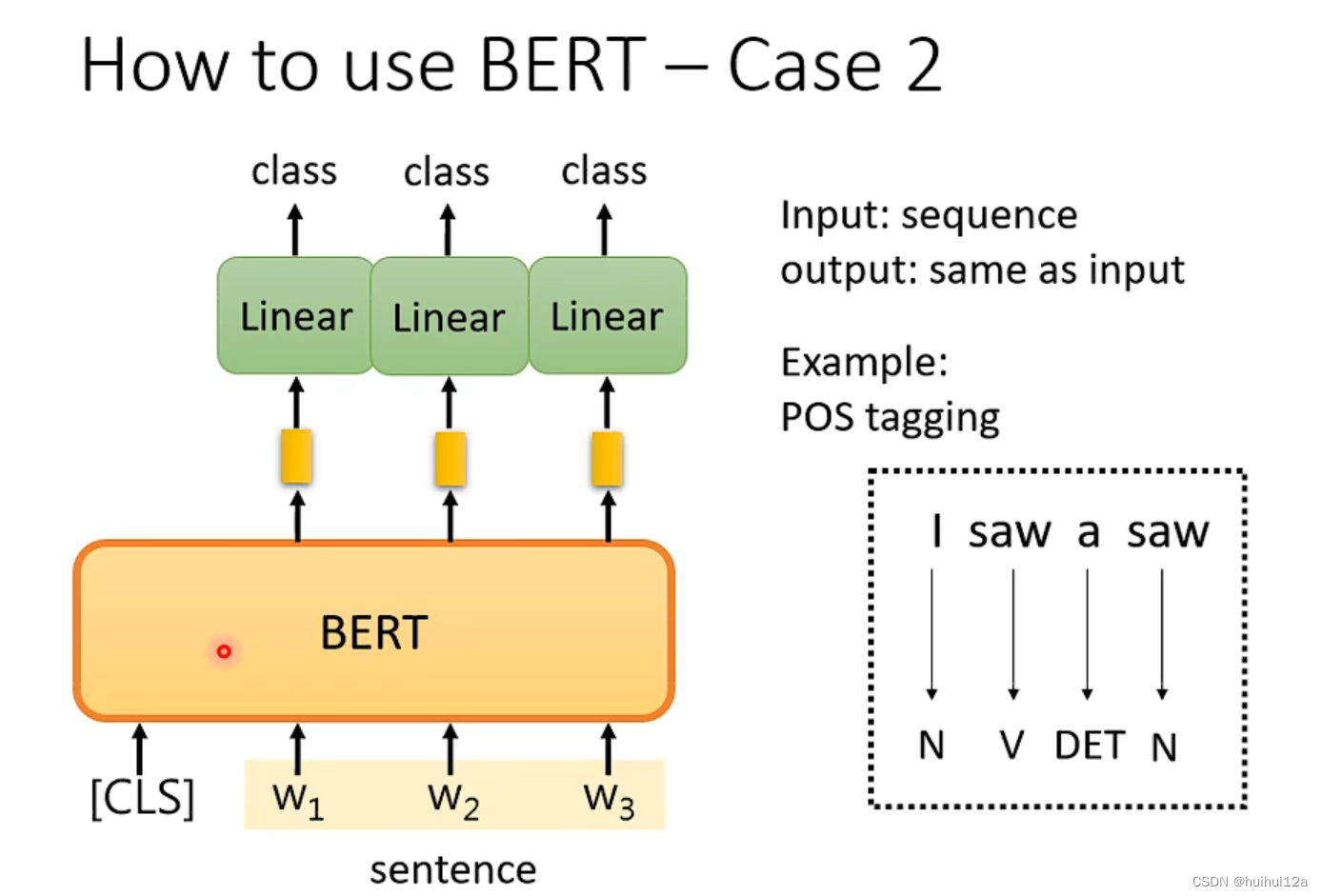
任务2:词性标注,输入和输出长度一样。
任务3:输入两个句子输出一个类别,例如判断两个句子的逻辑,是否矛盾?


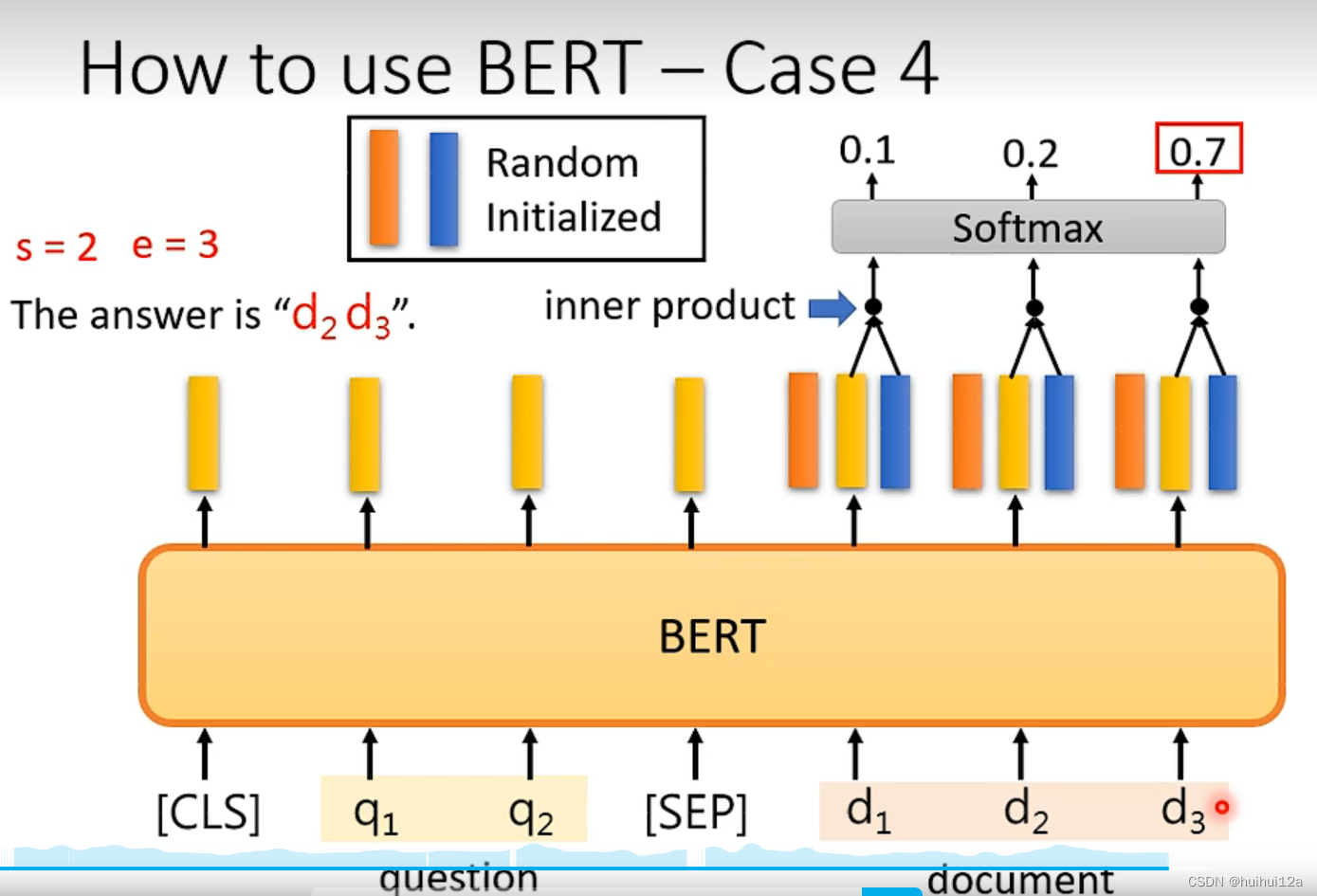
任务4:QA,给文章和问题,输出两个整数,定位答案的位置。

唯一需要从头随机初始化的是橙色和蓝色的两个向量。橙色和蓝色的向量分别和文档单词经过BERT的输出向量内积,计算出答案的起始位置。