力扣119杨辉三角 II:代码实现 + 方法总结(数学规律法 记忆法/备忘录)
文章目录
- 第一部分:题目
- 第二部分:解法①-数学规律法
- 2.1 规律分析
- 2.2 代码实现
- 2.3 需要思考
- 第三部分:解法②-记忆法(备忘录)
- 第四部分:对比总结
第一部分:题目
🏠 链接:119. 杨辉三角 II - 力扣(LeetCode)
⭐ 难度:简单

第二部分:解法①-数学规律法
2.1 规律分析

2.2 代码实现
public static List<Integer> getRow(int rowIndex) {
// 建立一个capacity=rowIndex+1的集合
ArrayList<Integer> arrayList = new ArrayList<>(rowIndex + 1);
// 设置第rowIndex行首位置的值
long indexValue = 1;
// 遍历第rowIndex行所有位置
for (int i = 0;i <= rowIndex;i++){
// long强转为int,将indexValue加入集合,发生了自动装包int->Integer
arrayList.add((int)indexValue);
// 根据规律设置下一个好下一个位置的值
indexValue = indexValue*(rowIndex-i)/(i+1);
}
return arrayList;
}
/*
这里有个细节:我们定义indexValue时类型为long,为什么不设置为int类型,这样便可以舍去加入集合时的强转过程
这是因为如果将indexValue定义为int类型,
那么在代码第六行计算indexValue*(rowIndex-i)时
由于indexValue,rowIndex和i都为int,那么indexValue*(rowIndex-i)的结果也为int
但是当rowIndex过大时,计算该行某些位置时indexValue*(rowIndex-i)的值会超过int的范围
导致这个值为负数。
因此,我们定义类型为long的话,由于long的精度比int高,
而indexValue*(rowIndex-i)的结果自然为long类型,且没有超过long的取值范围,
所以indexValue*(rowIndex-i)得到的便会是正常结果,而非因为数据溢出结果变为负数
*/
2.3 需要思考
我们定义indexValue时类型为long,为什么不设置为int类型,这样便可以舍去加入集合时的强转过程。
这是因为如果将indexValue定义为int类型,那么在代码第六行计算 indexValue * ( rowIndex - i ) 时由于 indexValue , rowIndex 和 i 都为int,那么 indexValue * ( rowIndex - i ) 的结果也为int。但是当rowIndex过大时,计算该行某些位置时indexValue*(rowIndex-i)的值会超过int的范围导致这个值为负数。
因此,我们定义类型为long的话,由于long的精度比int高,而indexValue*(rowIndex-i)的结果自然为long类型,且没有超过long的取值范围,所以indexValue * ( rowIndex - i ) 得到的便会是正常结果,而非因为数据溢出结果变为负数。
第三部分:解法②-记忆法(备忘录)
Memoization 记忆法(也称备忘录)是一种优化技术,通过存储函数调用结果(通常比较昂贵),当再次出现相同的输入(子问题)时,就能实现加速效果
public List<Integer> getRow(int rowIndex) {
ArrayList<Integer> list = new ArrayList<>(rowIndex + 1);
// 设置首元素的值为1
list.add(1);
// 从第二行(行索引为1)开始遍历
for (int i = 1; i <= rowIndex; i++) {
for (int j = i - 1; j > 0; j--) {
// 规律: [i][j] 的取值应为 [i-1][j-1] + [i-1][j]
list.set(j, list.get(j - 1) + list.get(j));
}
// 末尾元素的值为1
list.add(1);
}
return list;
}
第四部分:对比总结
我们来看下两种方法的执行效率:
1️⃣ 数学规律法
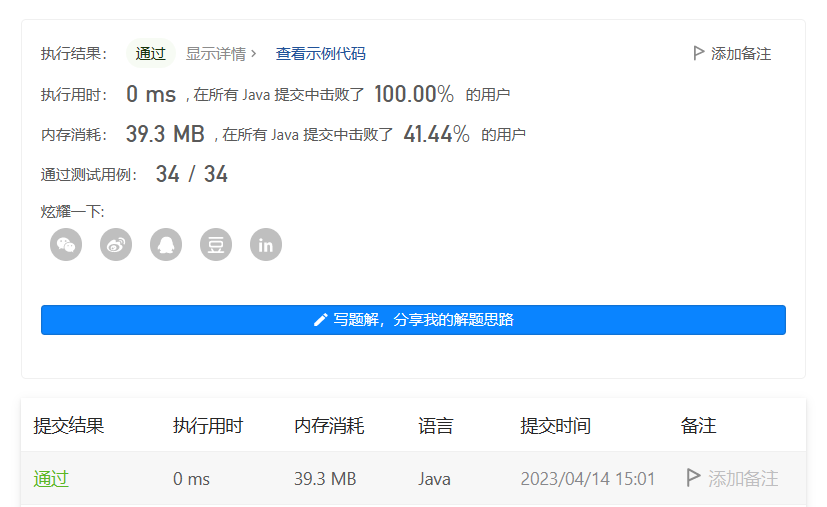
2️⃣ 记忆法
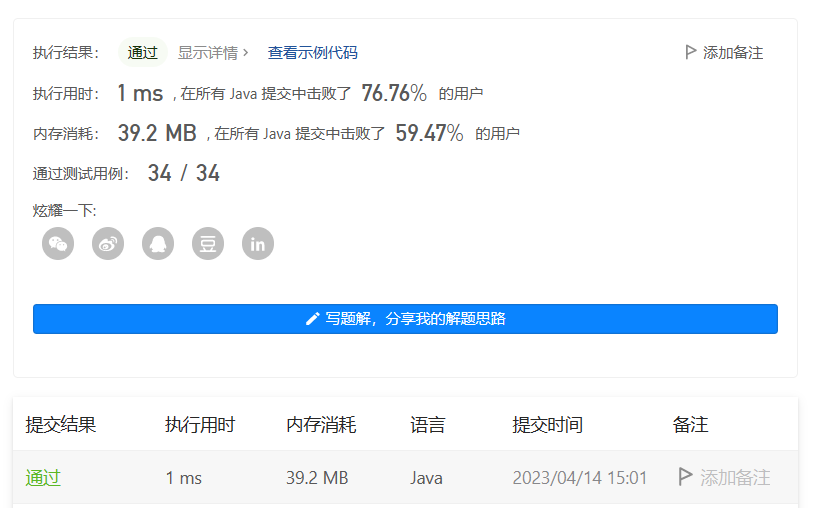
很明显,数学规律法花费的时间更少,这是因为 数学规律法 只需要我们逐一计算第 rowIndex 行每个元素的值即可,而 记忆法 需要我们从第0行开始,计算每一行每一个元素的值。