Go基础——数组、切片、集合
目录
- 1、数组
- 2、切片
- 3、集合
- 4、范围(range)
1、数组
数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
Go 语言数组声明需要指定元素类型及元素个数,与C语言稍微有所区别:
package main
import "fmt"
func main() {
var array1 [10]int
array1 = [10]int{1, 2, 3} // 未赋值的数组位补0
var array2 = [5]string{"a", "b"} // 未赋值的数组位补空值
array3 := [...]float32{1: 1.1, 2: 2.3} // 定义未确定长度的数组,并且给索引1和索引2赋值
fmt.Println(array1)
fmt.Println(array2)
fmt.Println(array3)
// 如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小
array4 := []int{1, 2, 3} // 实际为切片
fmt.Println(array4)
array5 := add(array4) // 将数组作为参数传递
fmt.Println(array5)
}
func add(arr []int) []int {
sum := 0
for i := 0; i < len(arr); i++ { // 与python一样,len计算长度
sum += arr[i]
arr[i] += 1
}
fmt.Println("re:", sum)
return arr
}
注意:在 Go 语言中,数组的大小是类型的一部分,因此不同大小的数组是不兼容的, [5]int 和 [10]int 是不同的类型。形参数组定义长度须与传参保持一致,函数传参时需特别注意!
多维数组与其他语言类似:
package main
import "fmt"
func main() {
arrays := [5][5]int{
{1, 2, 3, 4, 5},
{9, 8, 7, 6, -1},
}
fmt.Println(arrays)
access(arrays)
}
func access(arr [5][5]int) { // 形参数组定义长度须与传参保持一致
// 可通过len得到数组长度,用于不知道数组长度时
rows := len(arr) // 数组行数
cols := len(arr[0]) // 数组列数
for i := 0; i < rows; i++ {
for j := 0; j < cols; j++ {
fmt.Print(arr[i][j])
}
fmt.Print("\n")
}
}
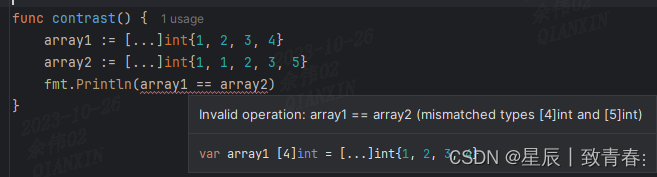
数组对比:可判断两个数组的元素是否相同,但两数组长度不相等是不能进行 == 运算
func contrast() {
array1 := [4]int{1, 2, 3, 4}
array2 := [4]int{1, 1, 2, 3}
fmt.Println(array1 == array2) // false
}
2、切片
Go 语言切片是对数组的抽象。Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
// 声明一个未指定大小的数组来定义切片:
var identifier []type
上代码:
package main
import (
"fmt"
"reflect"
)
func main() {
array := [5]int{1, 2, 4, 5, 6}
fmt.Println("array 类型:", reflect.TypeOf(array)) // array 类型: [5]int
s := array[:]
fmt.Println("s 类型:", reflect.TypeOf(s)) // s 类型: []int
fmt.Println(s) // [1 2 4 5 6]
// 切片,跟其他语言一样,左闭右开
sli1 := array[1:3]
sli2 := array[:len(array)-1]
sli3 := array[0:]
// sli1 := array[1:]
// sli1 := array[1:]
slic4 := make([]int, 2, 3) // 长度为2,容量为3的切片
fmt.Println(sli1) // [2 4]
fmt.Println(sli2) // [1 2 4 5]
fmt.Println(sli3) // [1 2 4 5 6]
fmt.Println(sli4) // [0 0] make创建的切片初始值为0,不等于nil
slis()
}
func slis() {
array1 := [8]int{1, 2, 3, 4}
s1 := array1[:]
s2 := []int{1, 2, 5, 7}
var s3 []int // 允许创建nil 空切片
fmt.Println("array1-cap: ", cap(s1)) // array1-cap: 8
fmt.Println("s2-cap: ", cap(s2)) // s2-cap: 4
if s3 == nil { // nil是一种特殊的值,表示没有任何指针指向的对象。相当于null
fmt.Println("s3-cap: ", cap(s3)) // 0
}
array2 := []int{8, 9, 3, 4, 5, 6, 7, 8, 9}
fmt.Println("array2-cap: ", array2, cap(array2))
array2 = append(array2, 1)
fmt.Println("array2-append-cap: ", array2, cap(array2))
}
切片可以看做是一个数组,索引、访问都是一样的,并且可以进行增删。
切片除了长度(len),还有容量(cap):容量(capacity)表示切片底层数组中可以容纳的元素数量。切片的容量可以预先分配更多的内存空间,以减少在运行时动态扩展切片的开销。当知道切片可能需要的最大元素数量时,可以通过设置合适的容量来避免频繁的内存分配和数据复制。切片的容量可以用于控制内存的使用。当创建一个切片时,Go语言会根据切片的长度和容量分配相应的内存空间。通过合理设置切片的容量,可以更好地控制内存的使用情况,避免不必要的内存浪费。但是切片的容量并不限制切片的长度,切片的长度可以根据需要动态增长,只要不超过容量的上限。当切片的长度超过容量时,Go语言会自动分配更大的内存空间(一般自动分配为原容量的2倍),并将原有数据复制到新的内存位置。因此,合理地设置切片的容量可以提高程序的性能和内存管理效率,但需要根据具体的应用场景和数据规模来进行权衡和选择。
append()函数:向slice里面追加一个或多个元素,然后返回一个和slice一样类型的slice。通过append也可实现对切片元素的删除。
arr := []int{1, 2}
arr = append(arr, 3, 4, 5, 6, 7, 8, 'a') // 单引号返回字符ASCII值
fmt.Println(arr) // [1 2 3 4 5 6 7 8 97]
arrs := []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
arrs = append(arrs[:1], arrs[4:]...) // 删除索引1到索引3处的元素
fmt.Println(arrs) // [1 5 6 7 8 9]
copy()函数:用于将源切片中的元素复制到目标切片中。
func copy(dst_slice, src_slice []Type) int
dst_slice是目标切片,src_slice是源切片,Type是切片元素的类型。函数返回为一个整数值,表示实际复制的元素个数(即src和dst的最小长度)
- dst_slice和src_slice的底层数组必须是相同类型的。例如,不能将一个 []int 类型的切片复制到一个 []string 类型的切片中。
- copy() 函数不会对切片本身进行初始化,所以在使用 copy() 之前,必须确保目标切片 dst_slice 已经初始化。
- copy() 不会自动扩容:copy() 函数只会复制dst_slice 切片能容纳的元素数量,如果dst_slice 的容量不足以容纳 src_slice 的所有元素,多余的元素将被丢弃。如果需要将src_slice切片的所有元素复制到dst_slice切片中,并且确保 dst_slice具有足够的容量,需要在复制前先对 dst进行扩容。可以使用 append() 函数来实现切片的扩容,然后再调用 copy() 函数进行复制。
- copy()函数会将src_slice中的元素逐个复制到dst_slice,不会对切片进行扩容或缩容。
- copy()函数不会创建新的切片,它只是修改目标切片的内容。
func sli_copy() {
sli1 := []int{9, 8, 7, 6, 5, 4}
sli2 := make([]int, 6)
num := copy(sli2, sli1)
fmt.Println(sli2, num) // [9 8 7 6 5 4] 6
sli3 := make([]int, 2)
num2 := copy(sli3, sli1) // copy 到短切片
fmt.Println(sli3, num2) // [9 8] 2
sli4 := make([]int, len(sli3))
_ = copy(sli4, sli3) // 切片copy后,内存地址不同
fmt.Printf("Address: slic3:%p slic4: %p", sli3, sli4) // Address: slic3:0xc000016190 slic4: 0xc0000161c0
}
注意:当目标切片长度为0时,copy不会生效。如将一个长度为0的切片[]int分配给sli5。sli5的内部数组没有足够的空间来容纳copy操作中src切片中的元素。因此,copy操作不会生效,因为它没有足够的空间去存储复制的数据。
sli5 := make([]int, 0)
_ = copy(sli5, sli3)
3、集合
Go语言中Map 是一种无序的键值对的集合。Map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。
Map 是一种集合,所以可以像迭代数组和切片那样迭代它。不过,Map 是无序的,遍历 Map 时返回的键值对的顺序是不确定的。
在获取 Map 的值时,如果键不存在,返回该类型的零值,例如 int 类型的零值是 0,string 类型的零值是 “”。Map 是引用类型,如果将一个 Map 传递给一个函数或赋值给另一个变量,它们都指向同一个底层数据结构,因此对 Map 的修改会影响到所有引用它的变量。
/* 使用 make 函数 */
map_variable := make(map[KeyType]ValueType, initialCapacity)
其中 KeyType 是键的类型,ValueType 是值的类型,initialCapacity 是可选的参数,用于指定 Map 的初始容量。Map 的容量是指 Map 中可以保存的键值对的数量,当 Map 中的键值对数量达到容量时,Map 会自动扩容。如果不指定 initialCapacity,Go 语言会根据实际情况选择一个合适的值。
func MapCreate() {
map1 := make(map[string]int) // 空map
map1["a"] = 1 // 与python一样,直接访问键,增加或修改值
fmt.Println(len(map1)) // 1
map2 := map[string]float32{ // 字面量创建
"aa": 1.5,
"bb": 2.0,
"cc": 3.36,
}
fmt.Println(map2)
// 遍历
for k, v := range map2 {
fmt.Printf("key=%s, value=%.2f\n", k, v)
}
// 删除
delete(map2, "cc")
fmt.Println(map2) // map[aa:1.5 bb:2]
}
delete() 函数用于删除集合的元素, 参数为 map 和其对应的 key。如果map中不存在指定的键,那么delete函数什么也不做。
4、范围(range)
range 关键字用于 for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。
先看切片的range:
for i, v := range pow {
fmt.Printf("索引:%d, 元素:%d \n", i, v)
}
// 此时遍历得到的是索引
for i := range pow {
fmt.Printf("%d ", i)
}
fmt.Printf("\n")
// 此时遍历得到的是索引
for _, v := range pow {
fmt.Printf("%d ", v)
}
fmt.Printf("\n")
// 不需要使用内部元素时
lens := 0
for range pow {
lens++
}
集合的range:
func MapRange() {
map1 := map[string]int{
"num1": 100,
"num2": 101,
"num3": 102,
"num4": 103,
}
// 键值对遍历
for key, vale := range map1 {
fmt.Printf("key: %s value: %d \n", key, vale)
}
// 只遍历建
for key := range map1 {
fmt.Printf("key: %s \n", key)
}
// 只遍历值
for _, vale := range map1 {
fmt.Printf("value: %d \n", vale)
}
//range也可以用来枚举 Unicode 字符串。第一个参数是字符的索引,第二个是字符(Unicode的值)本身。
for i, c := range "go" {
fmt.Println(i, c)
}
// 0 103
// 1 111
for i, c := range "中文啊" {
fmt.Println(i, c)
}
// 0 20013
// 3 25991
// 6 21834
}
与切片类似,但比较有意思的是当range范围是字符串时,遍历返回的是字符的Unicode编码值;而且当字符串是中文时,并且采用UTF-8编码时,一个中文占用3字节,如“中文啊”字节序列为:“E4 B8 AD E6 96 87 E5 95 8A”,每个字节对应一个Unicode码点,每三个字节表示一个汉字。上述 i 则是Unicode码点的索引,c则是对应的UTF-8编码。